![]()

Tutorial 1: GLMs for Encoding#
Week 1, Day 3: Generalized Linear Models
By Neuromatch Academy
Content creators: Pierre-Etienne H. Fiquet, Ari Benjamin, Jakob Macke
Content reviewers: Davide Valeriani, Alish Dipani, Michael Waskom, Ella Batty
Production editors: Spiros Chavlis
Tutorial Objectives#
Estimated timing of tutorial: 1 hour, 15 minutes
This is part 1 of a 2-part series about Generalized Linear Models (GLMs), which are a fundamental framework for supervised learning.
In this tutorial, the objective is to model a retinal ganglion cell spike train by fitting a temporal receptive field. First with a Linear-Gaussian GLM (also known as ordinary least-squares regression model) and then with a Poisson GLM (aka “Linear-Nonlinear-Poisson” model). In the next tutorial, we’ll extend to a special case of GLMs, logistic regression, and learn how to ensure good model performance.
This tutorial is designed to run with retinal ganglion cell spike train data from Uzzell & Chichilnisky 2004.
Acknowledgements:
We thank EJ Chichilnisky for providing the dataset. Please note that it is provided for tutorial purposes only, and should not be distributed or used for publication without express permission from the author (ej@stanford.edu).
We thank Jonathan Pillow, much of this tutorial is inspired by exercises assigned in his ‘Statistical Modeling and Analysis of Neural Data’ class.
Setup#
Install and import feedback gadget#
Show code cell source
# @title Install and import feedback gadget
!pip3 install vibecheck datatops --quiet
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "neuromatch_cn",
"user_key": "y1x3mpx5",
},
).render()
feedback_prefix = "W1D3_T1"
# Imports
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import minimize
from scipy.io import loadmat
Figure settings#
Show code cell source
# @title Figure settings
import logging
logging.getLogger('matplotlib.font_manager').disabled = True
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle")
Plotting Functions#
Show code cell source
# @title Plotting Functions
def plot_stim_and_spikes(stim, spikes, dt, nt=120):
"""Show time series of stim intensity and spike counts.
Args:
stim (1D array): vector of stimulus intensities
spikes (1D array): vector of spike counts
dt (number): duration of each time step
nt (number): number of time steps to plot
"""
timepoints = np.arange(nt)
time = timepoints * dt
f, (ax_stim, ax_spikes) = plt.subplots(
nrows=2, sharex=True, figsize=(8, 5),
)
ax_stim.plot(time, stim[timepoints])
ax_stim.set_ylabel('Stimulus intensity')
ax_spikes.plot(time, spikes[timepoints])
ax_spikes.set_xlabel('Time (s)')
ax_spikes.set_ylabel('Number of spikes')
f.tight_layout()
plt.show()
def plot_glm_matrices(X, y, nt=50):
"""Show X and Y as heatmaps.
Args:
X (2D array): Design matrix.
y (1D or 2D array): Target vector.
"""
from matplotlib.colors import BoundaryNorm
from mpl_toolkits.axes_grid1 import make_axes_locatable
Y = np.c_[y] # Ensure Y is 2D and skinny
f, (ax_x, ax_y) = plt.subplots(
ncols=2,
figsize=(6, 8),
sharey=True,
gridspec_kw=dict(width_ratios=(5, 1)),
)
norm = BoundaryNorm([-1, -.2, .2, 1], 256)
imx = ax_x.pcolormesh(X[:nt], cmap="coolwarm", norm=norm)
ax_x.set(
title="X\n(lagged stimulus)",
xlabel="Time lag (time bins)",
xticks=[4, 14, 24],
xticklabels=['-20', '-10', '0'],
ylabel="Time point (time bins)",
)
plt.setp(ax_x.spines.values(), visible=True)
divx = make_axes_locatable(ax_x)
caxx = divx.append_axes("right", size="5%", pad=0.1)
cbarx = f.colorbar(imx, cax=caxx)
cbarx.set_ticks([-.6, 0, .6])
cbarx.set_ticklabels(np.sort(np.unique(X)))
norm = BoundaryNorm(np.arange(y.max() + 1), 256)
imy = ax_y.pcolormesh(Y[:nt], cmap="magma", norm=norm)
ax_y.set(
title="Y\n(spike count)",
xticks=[]
)
ax_y.invert_yaxis()
plt.setp(ax_y.spines.values(), visible=True)
divy = make_axes_locatable(ax_y)
caxy = divy.append_axes("right", size="30%", pad=0.1)
cbary = f.colorbar(imy, cax=caxy)
cbary.set_ticks(np.arange(y.max()) + .5)
cbary.set_ticklabels(np.arange(y.max()))
plt.show()
def plot_spike_filter(theta, dt, show=True, **kws):
"""Plot estimated weights based on time lag model.
Args:
theta (1D array): Filter weights, not including DC term.
dt (number): Duration of each time bin.
kws: Pass additional keyword arguments to plot()
show (boolean): To plt.show or not the plot.
"""
d = len(theta)
t = np.arange(-d + 1, 1) * dt
ax = plt.gca()
ax.plot(t, theta, marker="o", **kws)
ax.axhline(0, color=".2", linestyle="--", zorder=1)
ax.set(
xlabel="Time before spike (s)",
ylabel="Filter weight",
)
if show:
plt.show()
def plot_spikes_with_prediction(spikes, predicted_spikes, dt,
nt=50, t0=120, **kws):
"""Plot actual and predicted spike counts.
Args:
spikes (1D array): Vector of actual spike counts
predicted_spikes (1D array): Vector of predicted spike counts
dt (number): Duration of each time bin.
nt (number): Number of time bins to plot
t0 (number): Index of first time bin to plot.
show (boolean): To plt.show or not the plot.
kws: Pass additional keyword arguments to plot()
"""
t = np.arange(t0, t0 + nt) * dt
f, ax = plt.subplots()
lines = ax.stem(t, spikes[:nt])
plt.setp(lines, color=".5")
lines[-1].set_zorder(1)
kws.setdefault("linewidth", 3)
yhat, = ax.plot(t, predicted_spikes[:nt], **kws)
ax.set(
xlabel="Time (s)",
ylabel="Spikes",
)
ax.yaxis.set_major_locator(plt.MaxNLocator(integer=True))
ax.legend([lines[0], yhat], ["Spikes", "Predicted"])
plt.show()
Data retrieval and loading#
Show code cell source
# @title Data retrieval and loading
import os
import hashlib
import requests
fname = "RGCdata.mat"
url = "https://osf.io/mzujs/download"
expected_md5 = "1b2977453020bce5319f2608c94d38d0"
if not os.path.isfile(fname):
try:
r = requests.get(url)
except requests.ConnectionError:
print("!!! Failed to download data !!!")
else:
if r.status_code != requests.codes.ok:
print("!!! Failed to download data !!!")
elif hashlib.md5(r.content).hexdigest() != expected_md5:
print("!!! Data download appears corrupted !!!")
else:
with open(fname, "wb") as fid:
fid.write(r.content)
Section 1: Linear-Gaussian GLM#
Video 1: Linear Gaussian model#
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Linear_Gaussian_Model_Video")
Section 1.1: Load retinal ganglion cell activity data#
Estimated timing to here from start of tutorial: 10 min
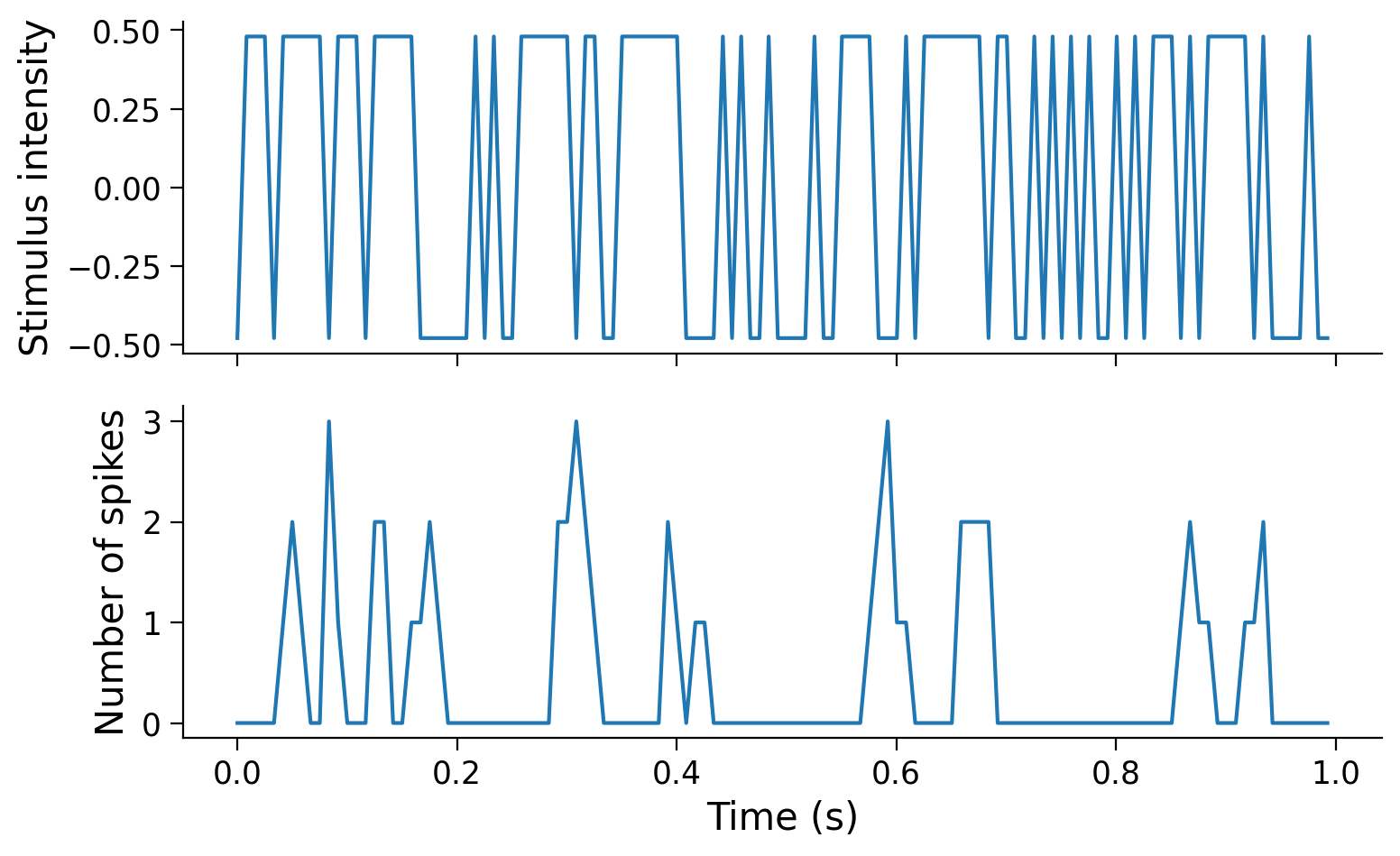
In this exercise we use data from an experiment that presented a screen which randomly alternated between two luminance values and recorded responses from retinal ganglion cell (RGC), a type of neuron in the retina in the back of the eye. This kind of visual stimulus is called a “full-field flicker”, and it was presented at ~120Hz (ie. the stimulus presented on the screen was refreshed about every 8ms). These same time bins were used to count the number of spikes emitted by each neuron.
The file RGCdata.mat contains three variables:
Stim, the stimulus intensity at each time point. It is an array with shape \(T \times 1\), where \(T=144051\).SpCounts, the binned spike counts for 2 ON cells, and 2 OFF cells. It is a \(144051 \times 4\) array, and each column has counts for a different cell.dtStim, the size of a single time bin (in seconds), which is needed for computing model output in units of spikes / s. The stimulus frame rate is given by1 / dtStim.
Because these data were saved in MATLAB, where everything is a matrix, we will also process the variables to more Pythonic representations (1D arrays or scalars, where appropriate) as we load the data.
data = loadmat('RGCdata.mat') # loadmat is a function in scipy.io
dt_stim = data['dtStim'].item() # .item extracts a scalar value
# Extract the stimulus intensity
stim = data['Stim'].squeeze() # .squeeze removes dimensions with 1 element
# Extract the spike counts for one cell
cellnum = 2
spikes = data['SpCounts'][:, cellnum]
# Don't use all of the timepoints in the dataset, for speed
keep_timepoints = 20000
stim = stim[:keep_timepoints]
spikes = spikes[:keep_timepoints]
Use the plot_stim_and_spikes helper function to visualize the changes in stimulus intensities and spike counts over time.
plot_stim_and_spikes(stim, spikes, dt_stim)
Coding Exercise 1.1: Create design matrix#
Our goal is to predict the cell’s activity from the stimulus intensities preceding it. That will help us understand how RGCs process information over time. To do so, we first need to create the design matrix for this model, which organizes the stimulus intensities in matrix form such that the \(i\)th row has the stimulus frames preceding timepoint \(i\).
In this exercise, we will create the design matrix \(\mathbf{X}\) using \(d=25\) time lags. That is, \(\mathbf{X}\) should be a \(T \times d\) matrix. \(d = 25\) (about 200 ms) is a choice we’re making based on our prior knowledge of the temporal window that influences RGC responses. In practice, you might not know the right duration to use.
The last entry in row t should correspond to the stimulus that was shown at time t, the entry to the left of it should contain the value that was shown one time bin earlier, etc. Specifically, \(X_{ij}\) will be the stimulus intensity at time \(i + d - 1 - j\).
Note that for the first few time bins, we have access to the recorded spike counts but not to the stimulus shown in the recent past. For simplicity we are going to assume that values of stim are 0 for the time lags prior to the first timepoint in the dataset. This is known as “zero-padding”, so that the design matrix has the same number of rows as the response vectors in spikes.
Your task is is to complete the function below to:
make a zero-padded version of the stimulus
initialize an empty design matrix with the correct shape
fill in each row of the design matrix, using the zero-padded version of the stimulus
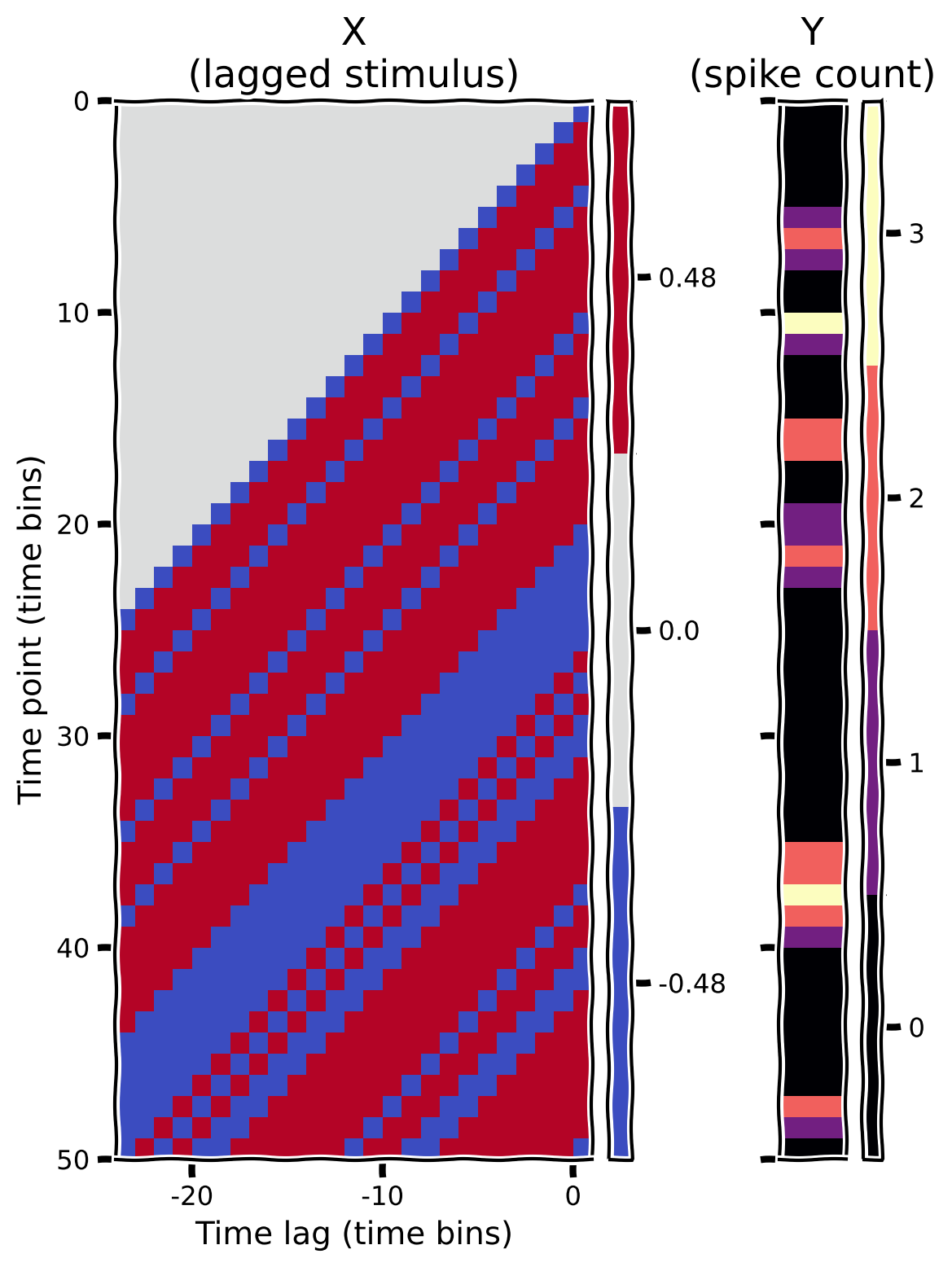
To visualize your design matrix (and the corresponding vector of spike counts), we will plot a “heatmap”, which encodes the numerical value in each position of the matrix as a color. The helper functions include some code to do this.
def make_design_matrix(stim, d=25):
"""Create time-lag design matrix from stimulus intensity vector.
Args:
stim (1D array): Stimulus intensity at each time point.
d (number): Number of time lags to use.
Returns
X (2D array): GLM design matrix with shape T, d
"""
# Create version of stimulus vector with zeros before onset
padded_stim = np.concatenate([np.zeros(d - 1), stim])
#####################################################################
# Fill in missing code (...),
# then remove or comment the line below to test your function
raise NotImplementedError("Complete the make_design_matrix function")
#####################################################################
# Construct a matrix where each row has the d frames of
# the stimulus preceding and including timepoint t
T = len(...) # Total number of timepoints (hint: number of stimulus frames)
X = np.zeros((T, d))
for t in range(T):
X[t] = ...
return X
# Make design matrix
X = make_design_matrix(stim)
# Visualize
plot_glm_matrices(X, spikes, nt=50)
Example output:
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Create_design_matrix_Exercise")
Section 1.2: Fit Linear-Gaussian regression model#
Estimated timing to here from start of tutorial: 25 min
First, we will use the design matrix to compute the maximum likelihood estimate for a linear-Gaussian GLM (aka “general linear model”). The maximum likelihood estimate of \(\theta\) in this model can be solved analytically using the equation you learned about on Day 3:
Before we can apply this equation, we need to augment the design matrix to account for the mean of \(y\), because the spike counts are all \(\geq 0\). We do this by adding a constant column of 1’s to the design matrix, which will allow the model to learn an additive offset weight. We will refer to this additional weight as \(b\) (for bias), although it is alternatively known as a “DC term” or “intercept”.
# Build the full design matrix
y = spikes
constant = np.ones_like(y)
X = np.column_stack([constant, make_design_matrix(stim)])
# Get the MLE weights for the LG model
theta = np.linalg.inv(X.T @ X) @ X.T @ y
theta_lg = theta[1:]
Plot the resulting maximum likelihood filter estimate (just the 25-element weight vector \(\theta\) on the stimulus elements, not the DC term \(b\)).
plot_spike_filter(theta_lg, dt_stim)
Coding Exercise 1.2: Predict spike counts with Linear-Gaussian model#
Now we are going to put these pieces together and write a function that outputs a predicted spike count for each timepoint using the stimulus information.
Your steps should be:
Create the complete design matrix
Obtain the MLE weights (\(\boldsymbol{\hat \theta}\))
Compute \(\mathbf{\hat y} = \mathbf{X}\boldsymbol{\hat \theta}\)
def predict_spike_counts_lg(stim, spikes, d=25):
"""Compute a vector of predicted spike counts given the stimulus.
Args:
stim (1D array): Stimulus values at each timepoint
spikes (1D array): Spike counts measured at each timepoint
d (number): Number of time lags to use.
Returns:
yhat (1D array): Predicted spikes at each timepoint.
"""
##########################################################################
# Fill in missing code (...) and then comment or remove the error to test
raise NotImplementedError("Complete the predict_spike_counts_lg function")
##########################################################################
# Create the design matrix
y = spikes
constant = ...
X = ...
# Get the MLE weights for the LG model
theta = ...
# Compute predicted spike counts
yhat = X @ theta
return yhat
# Predict spike counts
predicted_counts = predict_spike_counts_lg(stim, spikes)
# Visualize
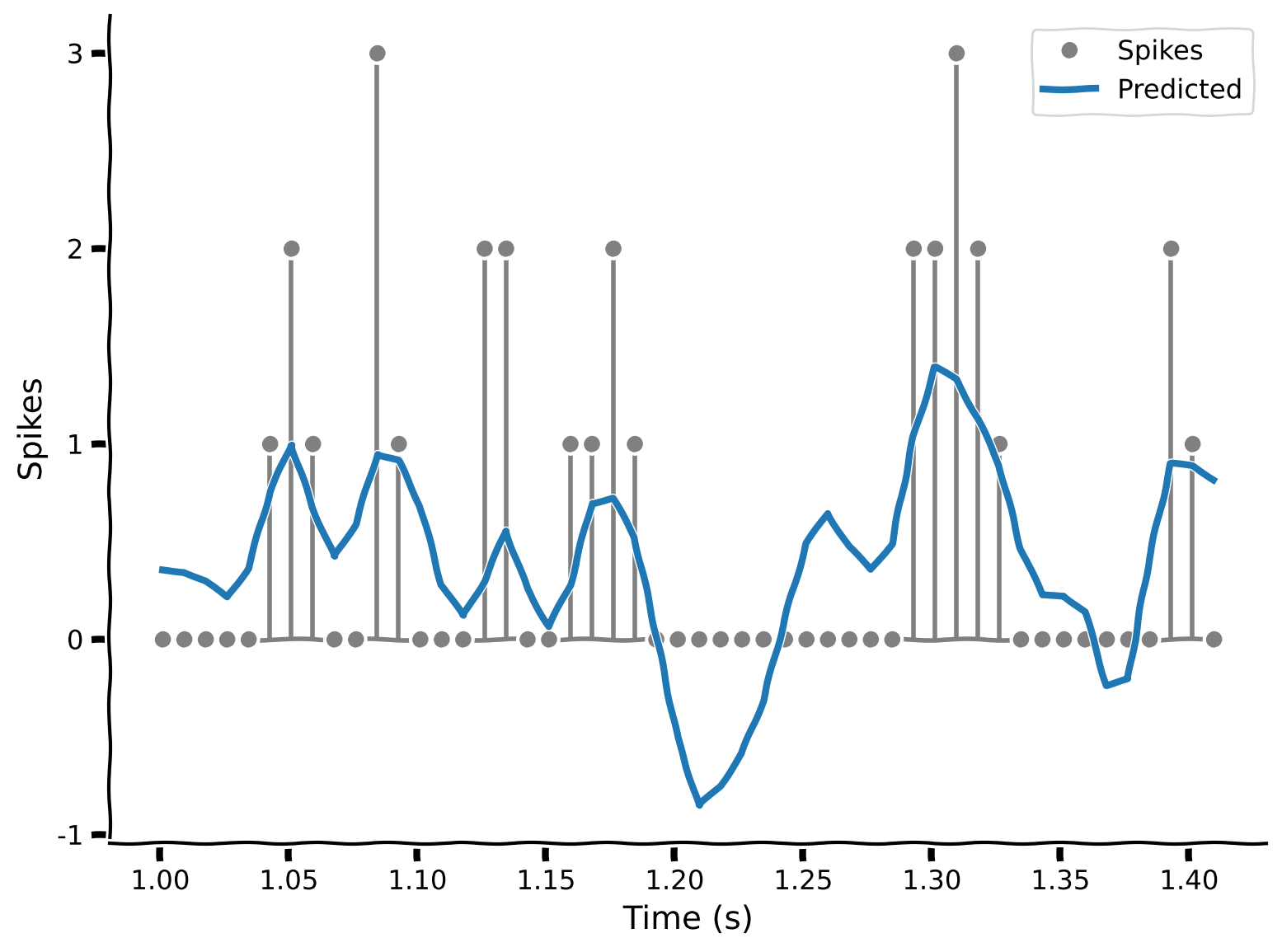
plot_spikes_with_prediction(spikes, predicted_counts, dt_stim)
Example output:
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Predict_counts_with_Linear_Gaussian_model_Exercise")
Is this a good model? The prediction line more-or-less follows the bumps in the spikes, but it never predicts as many spikes as are actually observed. And, more troublingly, it’s predicting negative spikes for some time points.
The Poisson GLM will help to address these failures.
Bonus challenge#
The “spike-triggered average” falls out as a subcase of the linear Gaussian GLM: \(\mathrm{STA} = \mathbf{X}^{\top} \mathbf{y} \,/\, \textrm{sum}(\mathbf{y})\), where \(\mathbf{y}\) is the vector of spike counts of the neuron. In the LG GLM, the term \((\mathbf{X}^{\top}\mathbf{X})^{-1}\) corrects for potential correlation between the regressors. Because the experiment that produced these data used a white noise stimulus, there are no such correlations. Therefore the two methods are equivalent. (How would you check the statement about no correlations?)
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Bonus_Challenge_Activity")
Section 2: Linear-Nonlinear-Poisson GLM#
Estimated timing to here from start of tutorial: 36 min
Video 2: Generalized linear model#
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Generalized_linear_model_Video")
Section 2.1: Nonlinear optimization with scipy.optimize#
Estimated timing to here from start of tutorial: 45 min
Before diving into the Poisson GLM case, let us review the use and importance of convexity in optimization:
We have seen previously that in the Linear-Gaussian case, maximum likelihood parameter estimate can be computed analytically. That is great because it only takes us a single line of code!
Unfortunately in general there is no analytical solution to our statistical estimation problems of interest. Instead, we need to apply a nonlinear optimization algorithm to find the parameter values that minimize some objective function. This can be extremely tedious because there is no general way to check whether we have found the optimal solution or if we are just stuck in some local minimum.
Somewhere in between these two extremes, the special case of convex objective function is of great practical importance. Indeed, such optimization problems can be solved very reliably (and usually quite rapidly too!) using some standard software.
Notes:
a function is convex if and only if its curve lies below any chord joining two of its points
to learn more about optimization, you can consult the book of Stephen Boyd and Lieven Vandenberghe Convex Optimization.
Here we will use the scipy.optimize module, it contains a function called minimize that provides a generic interface to a large number of optimization algorithms. This function expects as argument an objective function and an “initial guess” for the parameter values. It then returns a dictionary that includes the minimum function value, the parameters that give this minimum, and other information.
Let’s see how this works with a simple example. We want to minimize the function \(f(x) = x^2\):
f = np.square
res = minimize(f, x0=2)
print(f"Minimum value: {res['fun']:.4g} at x = {res['x'].item():.5e}")
Minimum value: 3.566e-16 at x = -1.88846e-08
When minimizing a \(f(x) = x^2\), we get a minimum value of \(f(x) \approx 0\) when \(x \approx 0\). The algorithm doesn’t return exactly \(0\), because it stops when it gets “close enough” to a minimum. You can change the tol parameter to control how it defines “close enough”.
A point about the code bears emphasis. The first argument to minimize is not a number or a string but a function. Here, we used np.square. Take a moment to make sure you understand what’s going on, because it’s a bit unusual, and it will be important for the exercise you’re going to do in a moment.
In this example, we started at \(x_0 = 2\). Let’s try different values for the starting point:
start_points = -1, 1.5
xx = np.linspace(-2, 2, 100)
plt.plot(xx, f(xx), color=".2")
plt.xlabel("$x$")
plt.ylabel("$f(x)$")
for i, x0 in enumerate(start_points):
res = minimize(f, x0)
plt.plot(x0, f(x0), "o", color=f"C{i}", ms=10, label=f"Start {i}")
plt.plot(res["x"].item(), res["fun"], "x", c=f"C{i}",
ms=10, mew=2, label=f"End {i}")
plt.legend()
plt.show()
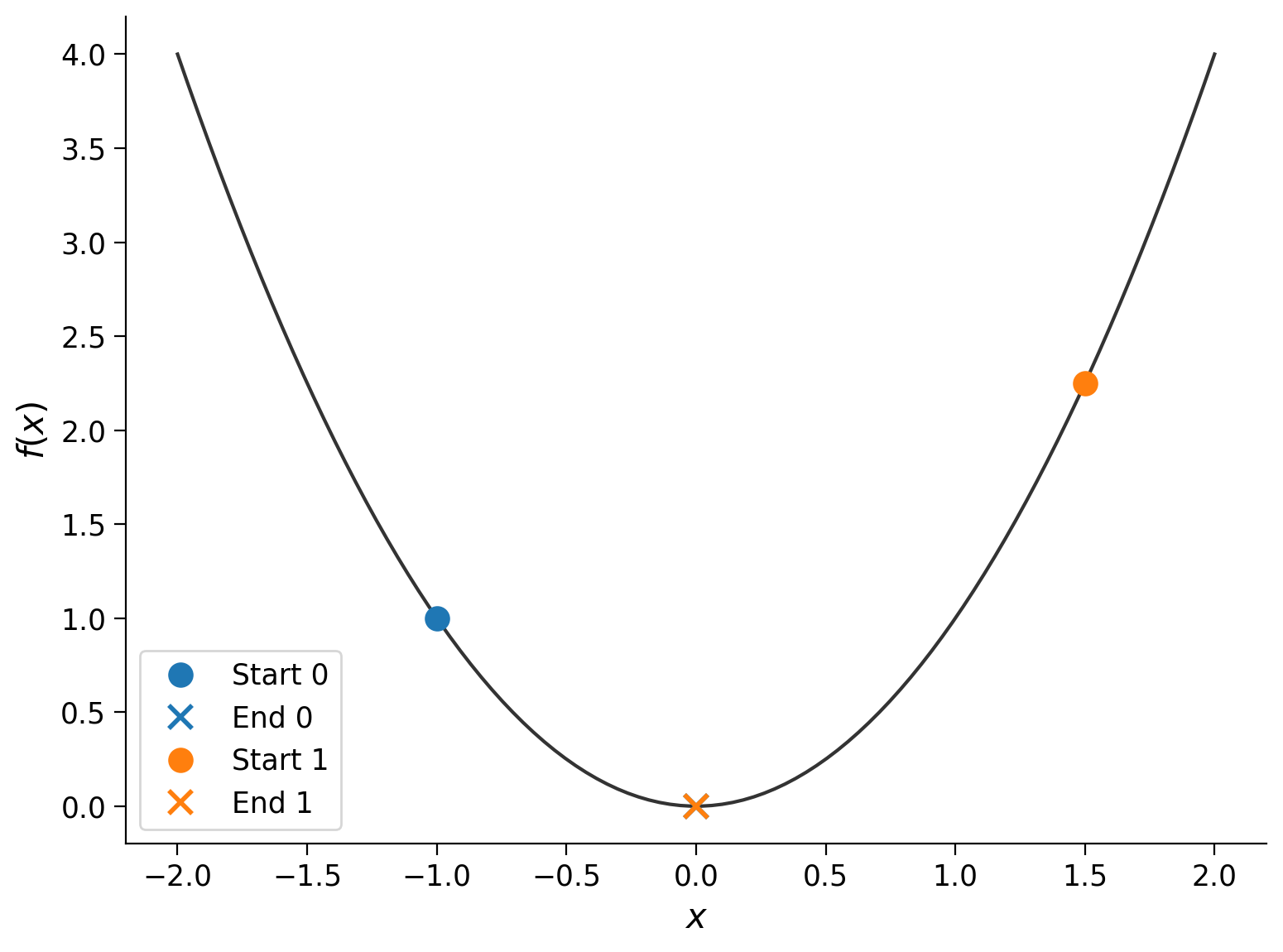
The runs started at different points (the dots), but they each ended up at roughly the same place (the cross): \(f(x_\textrm{final}) \approx 0\). Let’s see what happens if we use a different function:
g = lambda x: x / 5 + np.cos(x)
start_points = -.5, 1.5
xx = np.linspace(-4, 4, 100)
plt.plot(xx, g(xx), color=".2")
plt.xlabel("$x$")
plt.ylabel("$f(x)$")
for i, x0 in enumerate(start_points):
res = minimize(g, x0)
plt.plot(x0, g(x0), "o", color=f"C{i}", ms=10, label=f"Start {i}")
plt.plot(res["x"].item(), res["fun"], "x", color=f"C{i}",
ms=10, mew=2, label=f"End {i}")
plt.legend()
plt.show()
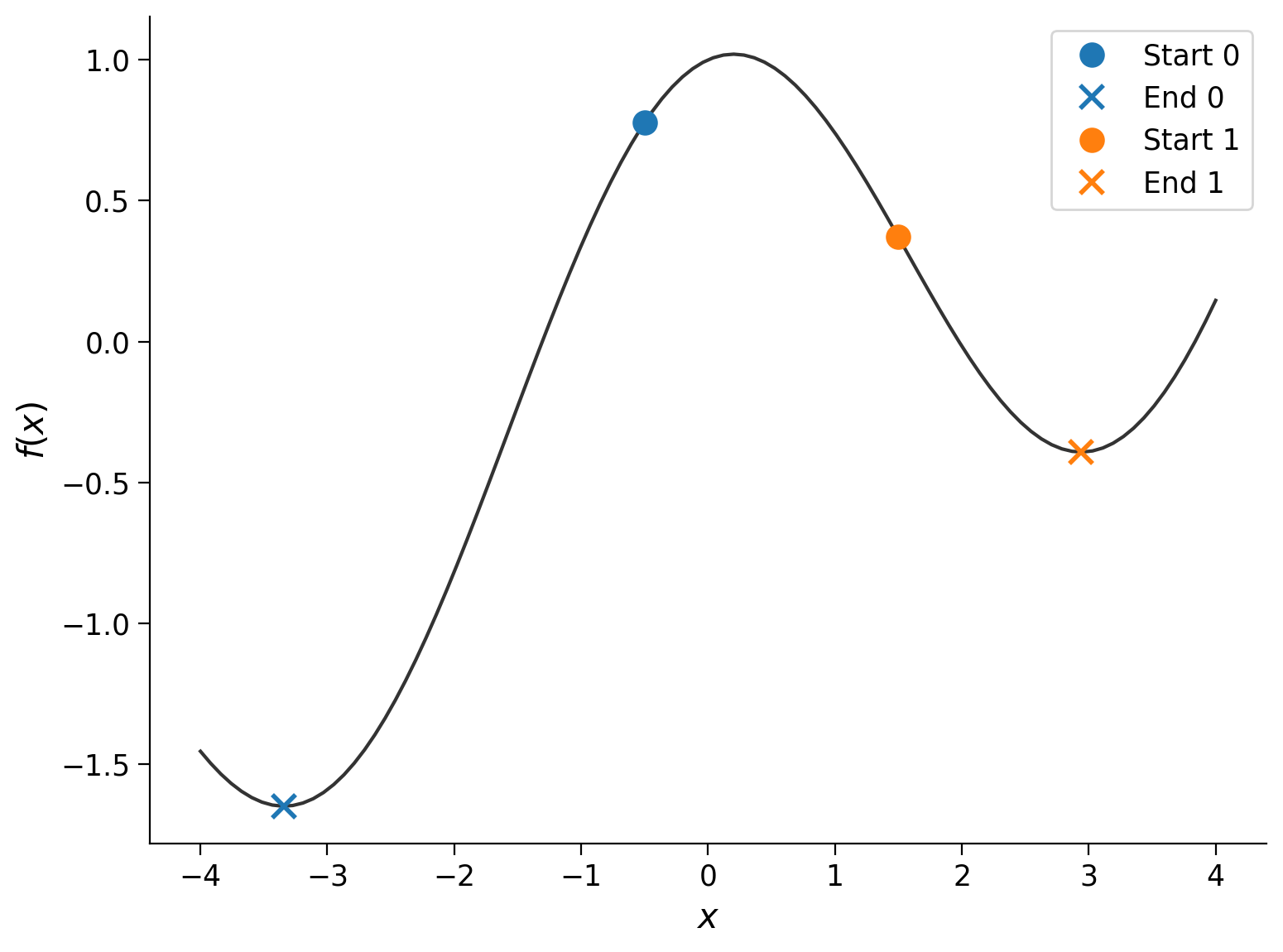
Unlike \(f(x) = x^2\), \(g(x) = \frac{x}{5} + \cos(x)\) is not convex. We see that the final position of the minimization algorithm depends on the starting point, which adds a layer of complexity to such problems.
Coding Exercise 2.1: Fitting the Poisson GLM and prediction spikes#
In this exercise, we will use scipy.optimize.minimize to compute maximum likelihood estimates for the filter weights in the Poisson GLM model with an exponential nonlinearity (LNP: Linear-Nonlinear-Poisson).
In practice, this will involve filling out two functions.
The first should be an objective function that takes a design matrix, a spike count vector, and a vector of parameters. It should return a negative log likelihood.
The second function should take
stimandspikes, build the design matrix and then useminimizeinternally, and return the MLE parameters.
What should the objective function look like? We want it to return the negative log likelihood: \(-\log P(y \mid \mathbf{X}, \theta).\)
In the Poisson GLM,
where
Now, taking the log likelihood for all the data we obtain:
Because we are going to minimize the negative log likelihood with respect to the parameters \(\theta\), we can ignore the last term that does not depend on \(\theta\). For faster implementation, let us rewrite this in matrix notation:
Finally, don’t forget to add the minus sign for your function to return the negative log likelihood.
def neg_log_lik_lnp(theta, X, y):
"""Return -loglike for the Poisson GLM model.
Args:
theta (1D array): Parameter vector.
X (2D array): Full design matrix.
y (1D array): Data values.
Returns:
number: Negative log likelihood.
"""
#####################################################################
# Fill in missing code (...), then remove the error
raise NotImplementedError("Complete the neg_log_lik_lnp function")
#####################################################################
# Compute the Poisson log likelihood
rate = np.exp(X @ theta)
log_lik = y @ ... - ...
return ...
def fit_lnp(stim, spikes, d=25):
"""Obtain MLE parameters for the Poisson GLM.
Args:
stim (1D array): Stimulus values at each timepoint
spikes (1D array): Spike counts measured at each timepoint
d (number): Number of time lags to use.
Returns:
1D array: MLE parameters
"""
#####################################################################
# Fill in missing code (...), then remove the error
raise NotImplementedError("Complete the fit_lnp function")
#####################################################################
# Build the design matrix
y = spikes
constant = np.ones_like(y)
X = np.column_stack([constant, make_design_matrix(stim)])
# Use a random vector of weights to start (mean 0, sd .2)
x0 = np.random.normal(0, .2, d + 1)
# Find parameters that minimize the negative log likelihood function
res = minimize(..., args=(X, y))
return ...
# Fit LNP model
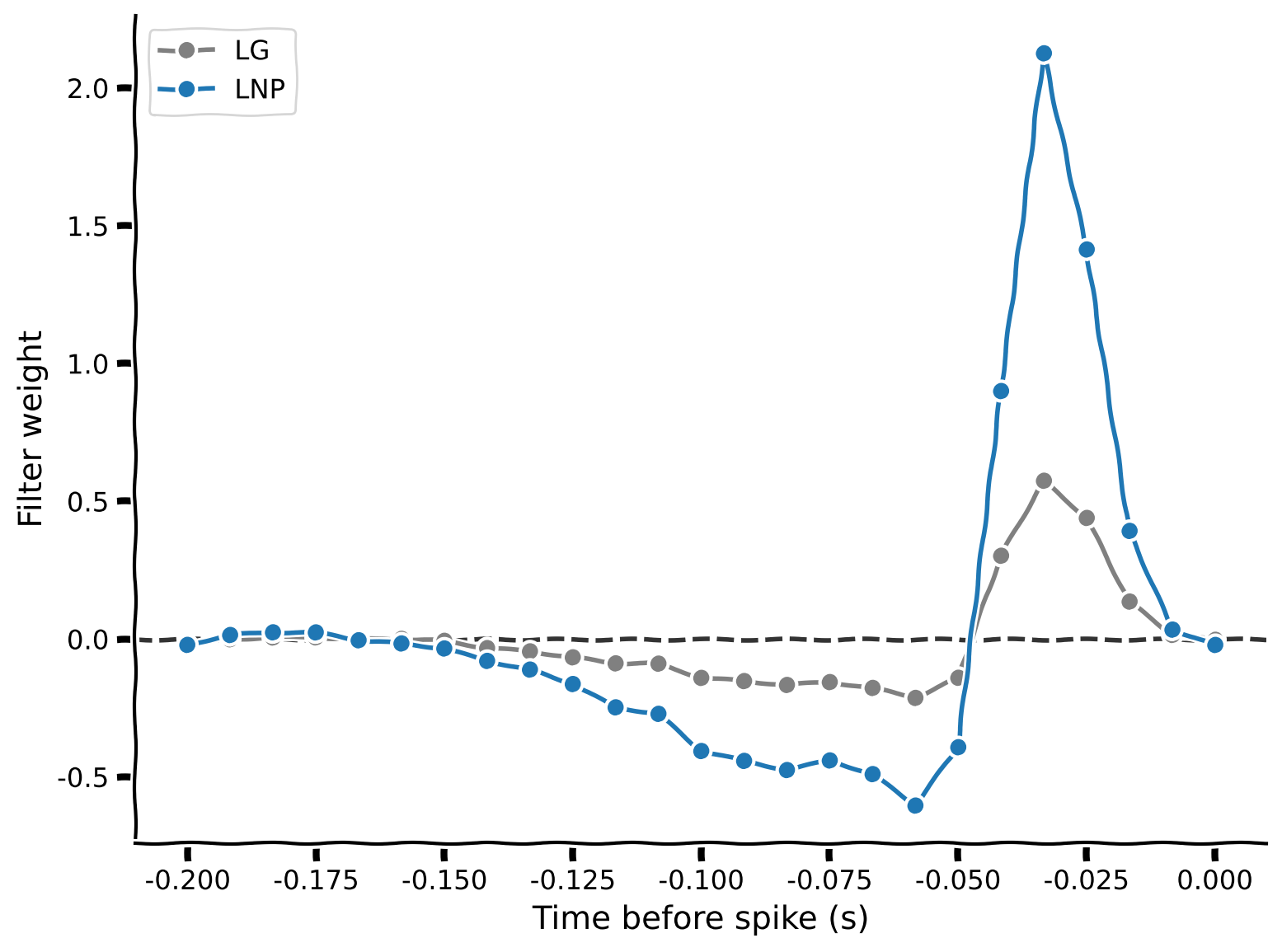
theta_lnp = fit_lnp(stim, spikes)
# Visualize
plot_spike_filter(theta_lg[1:], dt_stim, show=False, color=".5", label="LG")
plot_spike_filter(theta_lnp[1:], dt_stim, show=False, label="LNP")
plt.legend(loc="upper left")
plt.show()
Example output:
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Fitting_the_Poisson_GLM_Exercise")
Plotting the LG and LNP weights together, we see that they are broadly similar, but the LNP weights are generally larger. What does that mean for the model’s ability to predict spikes? To see that, let’s finish the exercise by filling out the predict_spike_counts_lnp function:
def predict_spike_counts_lnp(stim, spikes, theta=None, d=25):
"""Compute a vector of predicted spike counts given the stimulus.
Args:
stim (1D array): Stimulus values at each timepoint
spikes (1D array): Spike counts measured at each timepoint
theta (1D array): Filter weights; estimated if not provided.
d (number): Number of time lags to use.
Returns:
yhat (1D array): Predicted spikes at each timepoint.
"""
###########################################################################
# Fill in missing code (...) and then remove the error to test
raise NotImplementedError("Complete the predict_spike_counts_lnp function")
###########################################################################
y = spikes
constant = np.ones_like(spikes)
X = np.column_stack([constant, make_design_matrix(stim)])
if theta is None: # Allow pre-cached weights, as fitting is slow
theta = fit_lnp(X, y, d)
yhat = ...
return yhat
# Predict spike counts
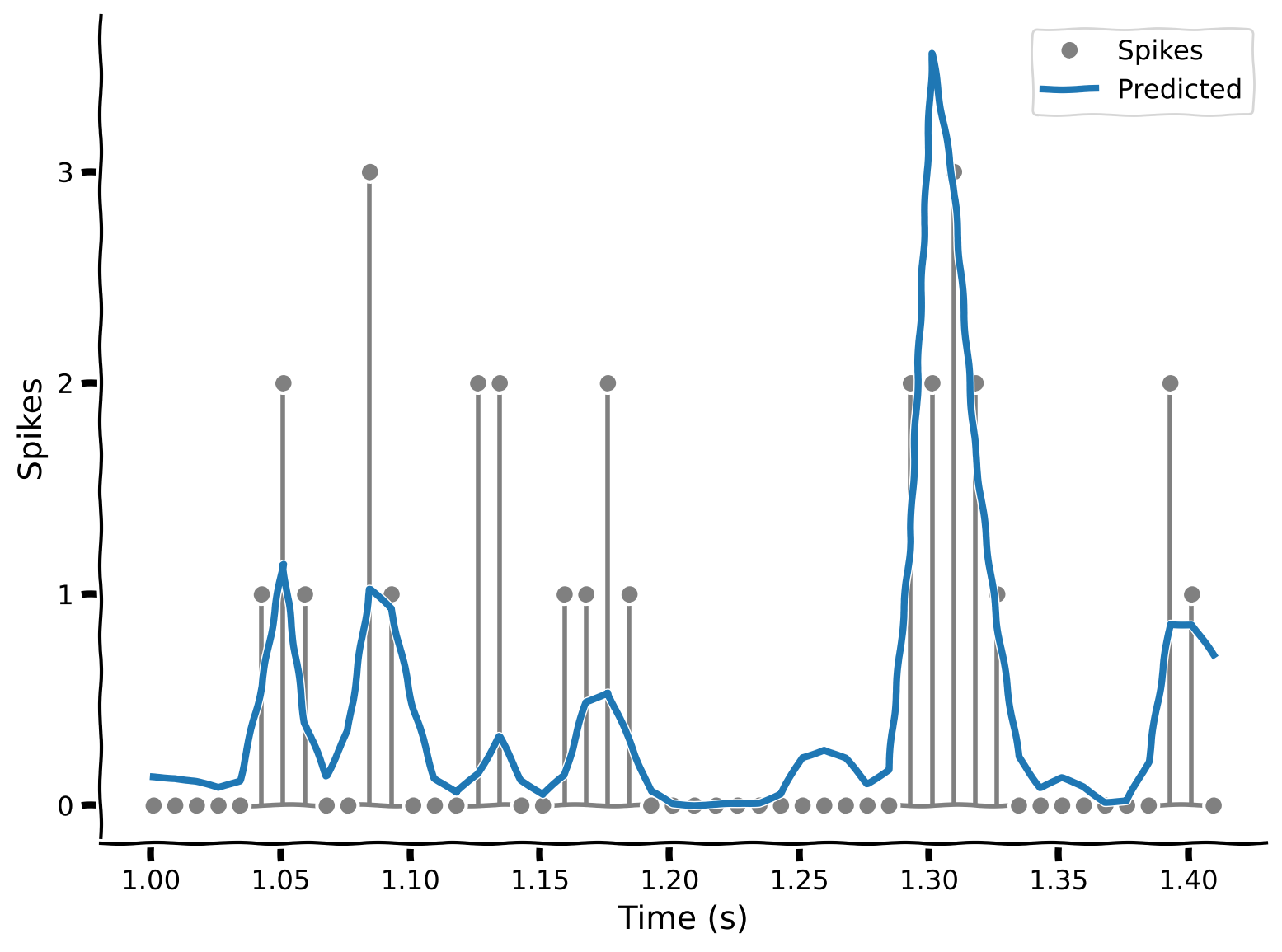
yhat = predict_spike_counts_lnp(stim, spikes, theta_lnp)
# Visualize
plot_spikes_with_prediction(spikes, yhat, dt_stim)
Example output:
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Predict_spike_counts_Exercise")
We see that the LNP model does a better job of fitting the actual spiking data. Importantly, it never predicts negative spikes!
Bonus: Our statement that the LNP model “does a better job” is qualitative and based mostly on the visual appearance of the plot. But how would you make this a quantitative statement?
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Predict_spike_counts_Bonus")
Summary#
Estimated timing of tutorial: 1 hour, 15 minutes
In this first tutorial, we used two different models to learn something about how retinal ganglion cells respond to a flickering white noise stimulus. We learned how to construct a design matrix that we could pass to different GLMs, and we found that the Linear-Nonlinear-Poisson (LNP) model allowed us to predict spike rates better than a simple Linear-Gaussian (LG) model.
In the next tutorial, we’ll extend these ideas further. We’ll meet yet another GLM — logistic regression — and we’ll learn how to ensure good model performance even when the number of parameters d is large compared to the number of data points N.