![]()

Tutorial 3: “Why” models#
Week 1, Day 1: Model Types
By Neuromatch Academy
Content creators: Matt Laporte, Byron Galbraith, Konrad Kording
Content reviewers: Dalin Guo, Aishwarya Balwani, Madineh Sarvestani, Maryam Vaziri-Pashkam, Michael Waskom, Ella Batty
Post-production team: Gagana B, Spiros Chavlis
We would like to acknowledge Steinmetz et al. (2019) for sharing their data, a subset of which is used here.
Tutorial Objectives#
Estimated timing of tutorial: 45 minutes
This is tutorial 3 of a 3-part series on different flavors of models used to understand neural data. In parts 1 and 2 we explored mechanisms that would produce the data. In this tutorial we will explore models and techniques that can potentially explain why the spiking data we have observed is produced the way it is.
To understand why different spiking behaviors may be beneficial, we will learn about the concept of entropy. Specifically, we will:
Write code to compute formula for entropy, a measure of information
Compute the entropy of a number of toy distributions
Compute the entropy of spiking activity from the Steinmetz dataset
Setup#
Install and import feedback gadget#
Show code cell source
# @title Install and import feedback gadget
!pip3 install vibecheck datatops --quiet
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "neuromatch_cn",
"user_key": "y1x3mpx5",
},
).render()
feedback_prefix = "W1D1_T3"
# Imports
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
Figure Settings#
Show code cell source
# @title Figure Settings
import logging
logging.getLogger('matplotlib.font_manager').disabled = True
import ipywidgets as widgets # interactive display
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle")
Plotting Functions#
Show code cell source
# @title Plotting Functions
def plot_pmf(pmf,isi_range):
"""Plot the probability mass function."""
ymax = max(0.2, 1.05 * np.max(pmf))
pmf_ = np.insert(pmf, 0, pmf[0])
plt.plot(bins, pmf_, drawstyle="steps")
plt.fill_between(bins, pmf_, step="pre", alpha=0.4)
plt.title(f"Neuron {neuron_idx}")
plt.xlabel("Inter-spike interval (s)")
plt.ylabel("Probability mass")
plt.xlim(isi_range)
plt.ylim([0, ymax])
Download Data#
Show code cell source
#@title Download Data
import io
import requests
r = requests.get('https://osf.io/sy5xt/download')
if r.status_code != 200:
print('Could not download data')
else:
steinmetz_spikes = np.load(io.BytesIO(r.content), allow_pickle=True)['spike_times']
“Why” models#
Video 1: “Why” models#
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Why_models_Video")
Section 1: Optimization and Information#
Remember that the notation section is located after the Summary for quick reference!
Neurons can only fire so often in a fixed period of time, as the act of emitting a spike consumes energy that is depleted and must eventually be replenished. To communicate effectively for downstream computation, the neuron would need to make good use of its limited spiking capability. This becomes an optimization problem:
What is the optimal way for a neuron to fire in order to maximize its ability to communicate information?
In order to explore this question, we first need to have a quantifiable measure for information. Shannon introduced the concept of entropy to do just that, and defined it as
where \(H\) is entropy measured in units of base \(b\) and \(p(x)\) is the probability of observing the event \(x\) from the set of all possible events in \(X\). See the Bonus Section 1 for a more detailed look at how this equation was derived.
The most common base of measuring entropy is \(b=2\), so we often talk about bits of information, though other bases are used as well (e.g. when \(b=e\) we call the units nats).
First, let’s explore how entropy changes between some simple discrete probability distributions. In the rest of this tutorial we will refer to these as probability mass functions (PMF), where \(p(x_i)\) equals the \(i^{th}\) value in an array, and mass refers to how much of the distribution is contained at that value.
For our first PMF, we will choose one where all of the probability mass is located in the middle of the distribution.
n_bins = 50 # number of points supporting the distribution
x_range = (0, 1) # will be subdivided evenly into bins corresponding to points
bins = np.linspace(*x_range, n_bins + 1) # bin edges
pmf = np.zeros(n_bins)
pmf[len(pmf) // 2] = 1.0 # middle point has all the mass
# Since we already have a PMF, rather than un-binned samples, `plt.hist` is not
# suitable. Instead, we directly plot the PMF as a step function to visualize
# the histogram:
pmf_ = np.insert(pmf, 0, pmf[0]) # this is necessary to align plot steps with bin edges
plt.plot(bins, pmf_, drawstyle="steps")
# `fill_between` provides area shading
plt.fill_between(bins, pmf_, step="pre", alpha=0.4)
plt.xlabel("x")
plt.ylabel("p(x)")
plt.xlim(x_range)
plt.ylim(0, 1)
plt.show()
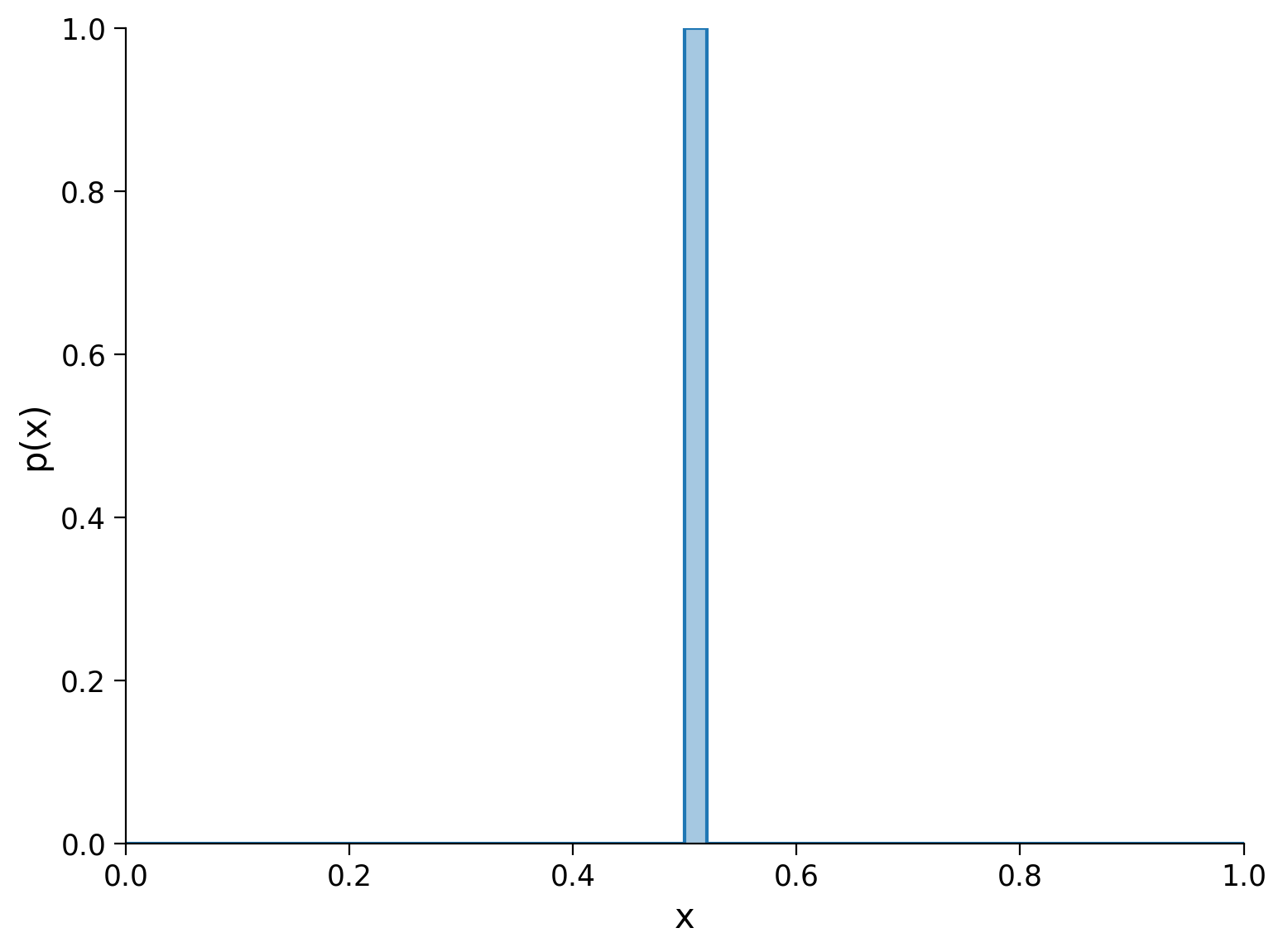
If we were to draw a sample from this distribution, we know exactly what we would get every time. Distributions where all the mass is concentrated on a single event are known as deterministic.
How much entropy is contained in a deterministic distribution? We will compute this in the next exercise.
Coding Exercise 1: Computing Entropy#
Your first exercise is to implement a method that computes the entropy of a discrete probability distribution, given its mass function. Remember that we are interested in entropy in units of bits, so be sure to use the correct log function.
Recall that \(\log(0)\) is undefined. When evaluated at \(0\), NumPy log functions (such as np.log2) return np.nan (“Not a Number”). By convention, these undefined terms— which correspond to points in the distribution with zero mass—are excluded from the sum that computes the entropy.
def entropy(pmf):
"""Given a discrete distribution, return the Shannon entropy in bits.
This is a measure of information in the distribution. For a totally
deterministic distribution, where samples are always found in the same bin,
then samples from the distribution give no more information and the entropy
is 0.
For now this assumes `pmf` arrives as a well-formed distribution (that is,
`np.sum(pmf)==1` and `not np.any(pmf < 0)`)
Args:
pmf (np.ndarray): The probability mass function for a discrete distribution
represented as an array of probabilities.
Returns:
h (number): The entropy of the distribution in `pmf`.
"""
############################################################################
# Exercise for students: compute the entropy of the provided PMF
# 1. Exclude the points in the distribution with no mass (where `pmf==0`).
# Hint: this is equivalent to including only the points with `pmf>0`.
# 2. Implement the equation for Shannon entropy (in bits).
# When ready to test, comment or remove the next line
raise NotImplementedError("Exercise: implement the equation for entropy")
############################################################################
# reduce to non-zero entries to avoid an error from log2(0)
pmf = ...
# implement the equation for Shannon entropy (in bits)
h = ...
# return the absolute value (avoids getting a -0 result)
return np.abs(h)
# Call entropy function and print result
print(f"{entropy(pmf):.2f} bits")
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Optimization_and_Information_Exercise")
We expect zero surprise from a deterministic distribution. If we had done this calculation by hand, it would simply be \(-1\log_2 1 = -0=0\).
Note that changing the location of the peak (i.e. the point and bin on which all the mass rests) doesn’t alter the entropy. The entropy is about how predictable a sample is with respect to a distribution. A single peak is deterministic regardless of which point it sits on - the following plot shows a PMF that would also have zero entropy.
Execute this cell to visualize another PMF with zero entropy
Show code cell source
# @markdown Execute this cell to visualize another PMF with zero entropy
pmf = np.zeros(n_bins)
pmf[2] = 1.0 # arbitrary point has all the mass
pmf_ = np.insert(pmf, 0, pmf[0])
plt.plot(bins, pmf_, drawstyle="steps")
plt.fill_between(bins, pmf_, step="pre", alpha=0.4)
plt.xlabel("x")
plt.ylabel("p(x)")
plt.xlim(x_range)
plt.ylim(0, 1);
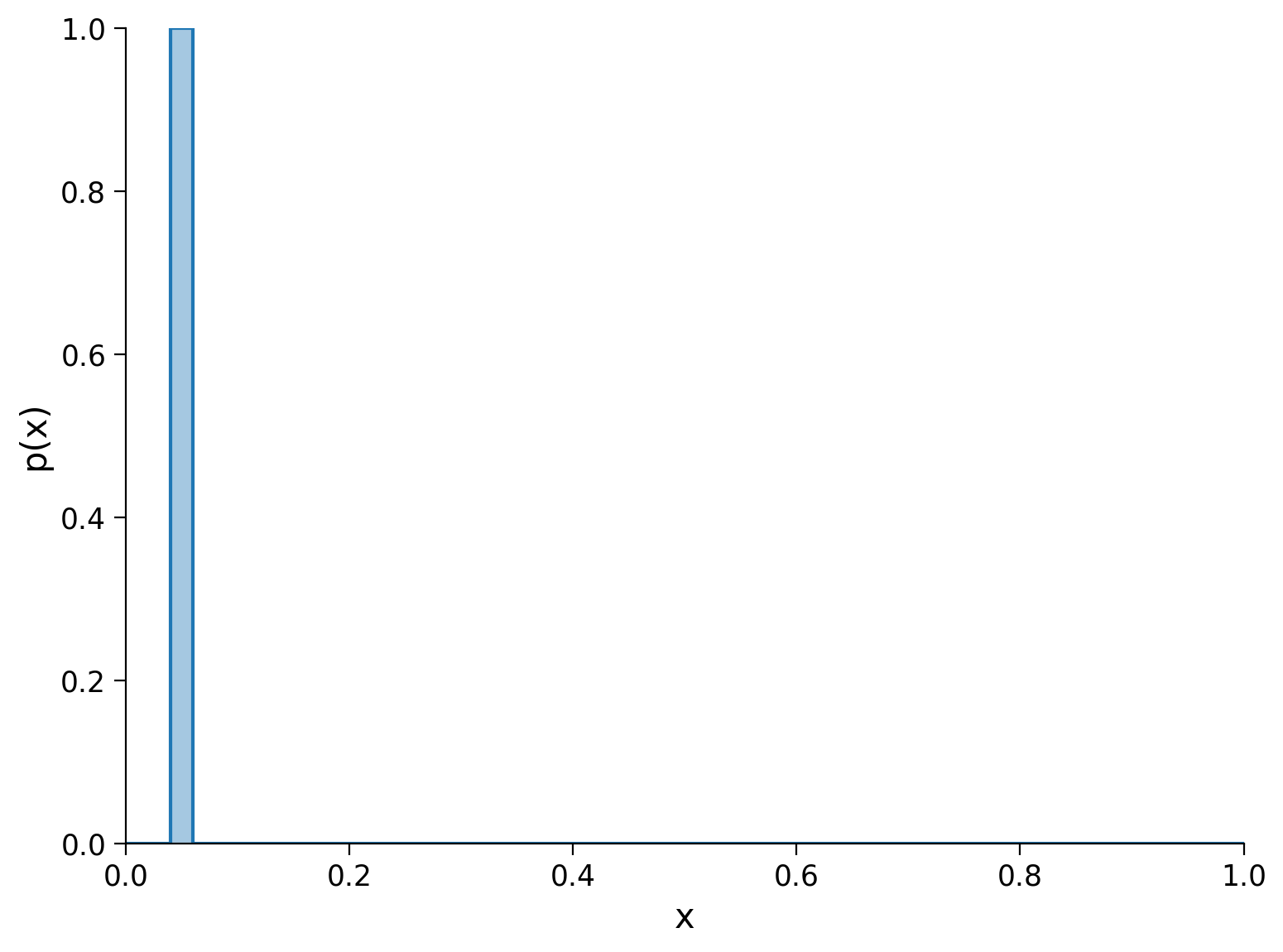
What about a distribution with mass split equally between two points?
Execute this cell to visualize a PMF with split mass
Show code cell source
# @markdown Execute this cell to visualize a PMF with split mass
pmf = np.zeros(n_bins)
pmf[len(pmf) // 3] = 0.5
pmf[2 * len(pmf) // 3] = 0.5
pmf_ = np.insert(pmf, 0, pmf[0])
plt.plot(bins, pmf_, drawstyle="steps")
plt.fill_between(bins, pmf_, step="pre", alpha=0.4)
plt.xlabel("x")
plt.ylabel("p(x)")
plt.xlim(x_range)
plt.ylim(0, 1)
plt.show()
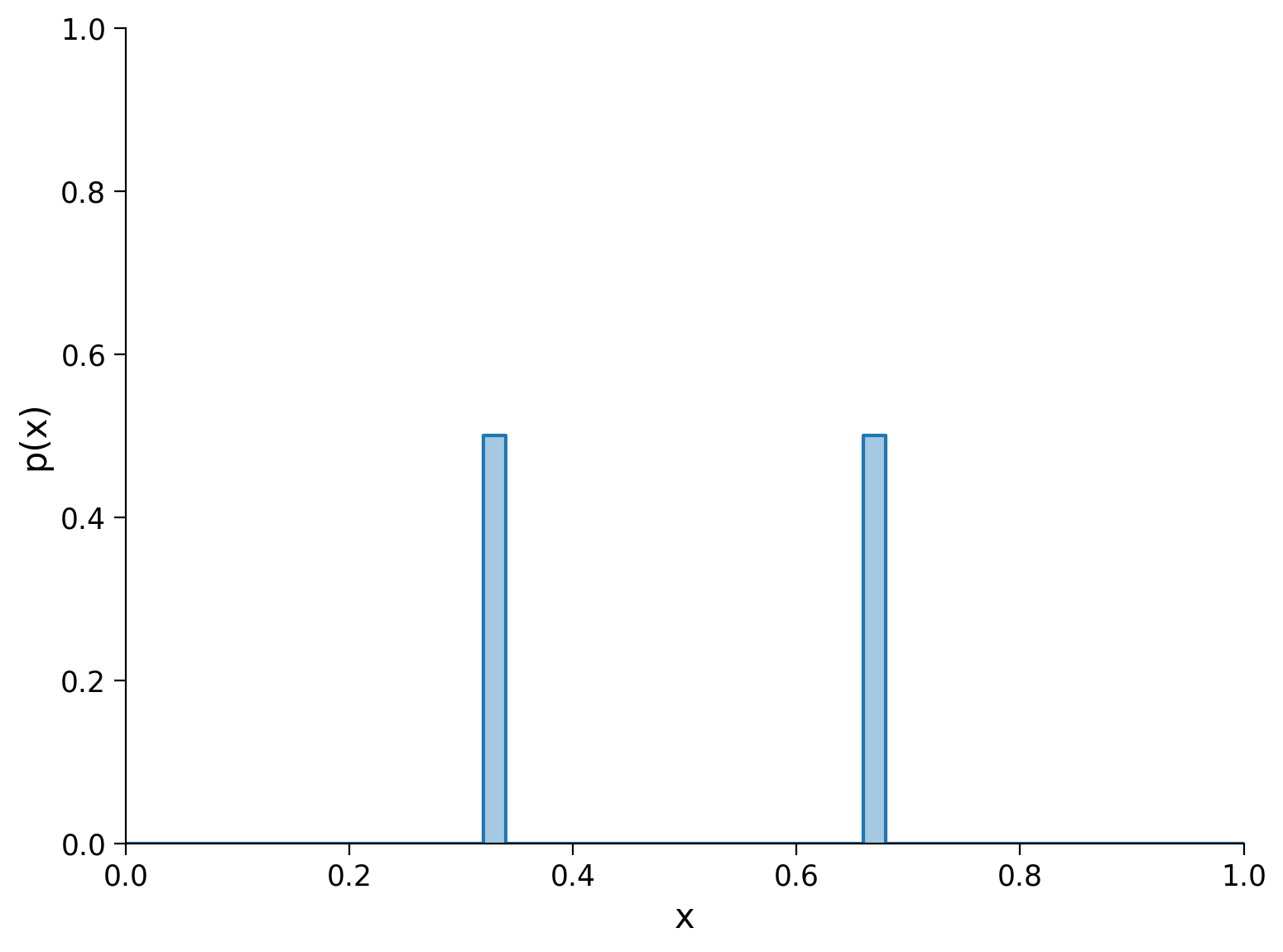
Here, the entropy calculation is: \(-(0.5 \log_2 0.5 + 0.5\log_2 0.5)=1\)
There is 1 bit of entropy. This means that before we take a random sample, there is 1 bit of uncertainty about which point in the distribution the sample will fall on: it will either be the first peak or the second one.
Likewise, if we make one of the peaks taller (i.e. its point holds more of the probability mass) and the other one shorter, the entropy will decrease because of the increased certainty that the sample will fall on one point and not the other: : \(-(0.2 \log_2 0.2 + 0.8\log_2 0.8)\approx 0.72\)
Try changing the definition of the number and weighting of peaks, and see how the entropy varies.
If we split the probability mass among even more points, the entropy continues to increase. Let’s derive the general form for \(N\) points of equal mass, where \(p_i=p=1/N\):
If we have \(N\) discrete points, the uniform distribution (where all points have equal mass) is the distribution with the highest entropy: \(\log_b N\). This upper bound on entropy is useful when considering binning strategies, as any estimate of entropy over \(N\) discrete points (or bins) must be in the interval \([0, \log_b N]\).
Execute this cell to visualize a PMF of uniform distribution
Show code cell source
# @markdown Execute this cell to visualize a PMF of uniform distribution
pmf = np.ones(n_bins) / n_bins # [1/N] * N
pmf_ = np.insert(pmf, 0, pmf[0])
plt.plot(bins, pmf_, drawstyle="steps")
plt.fill_between(bins, pmf_, step="pre", alpha=0.4)
plt.xlabel("x")
plt.ylabel("p(x)")
plt.xlim(x_range)
plt.ylim(0, 1)
plt.show()
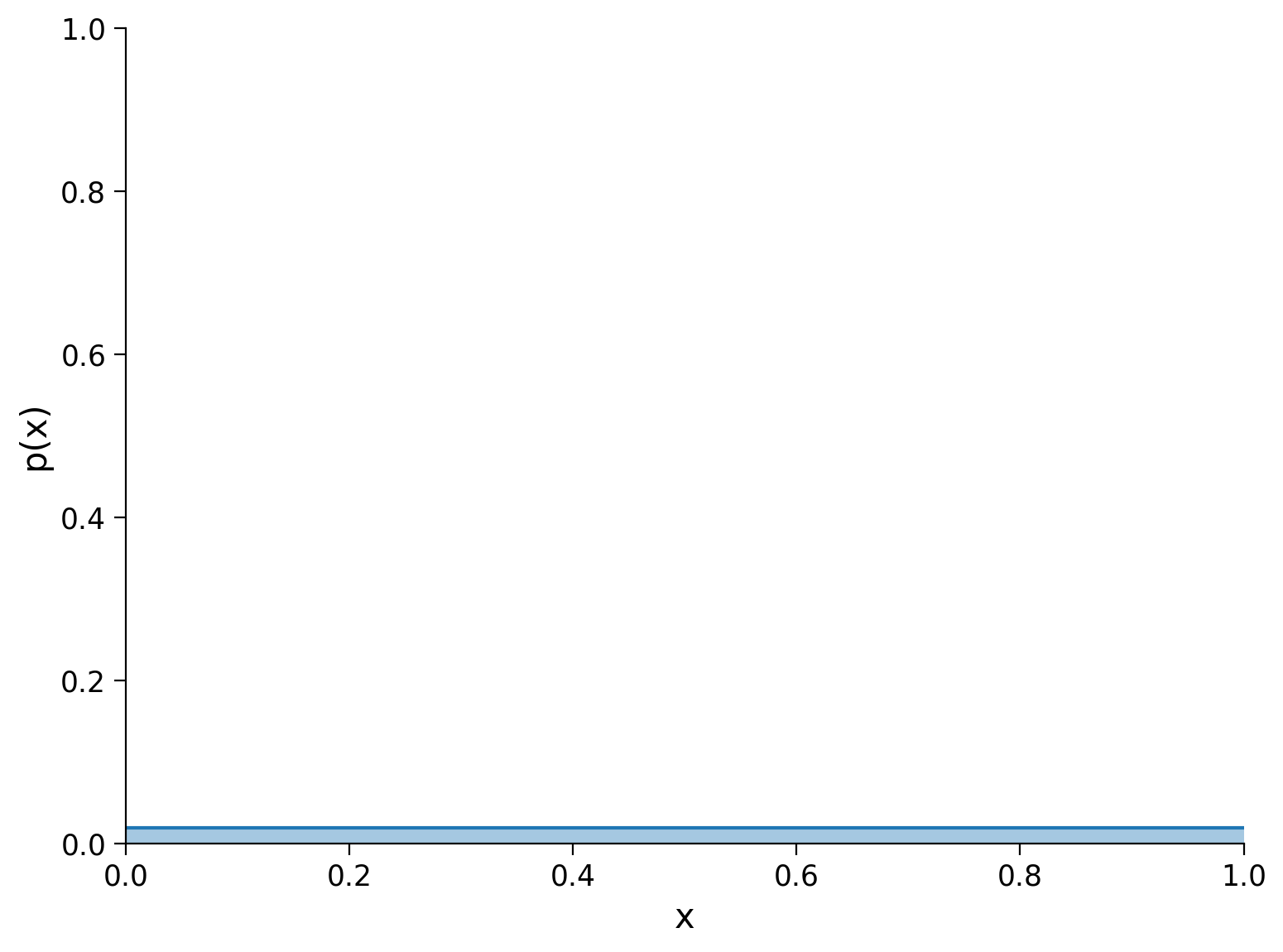
Here, there are 50 points and the entropy of the uniform distribution is \(\log_2 50\approx 5.64\). If we construct any discrete distribution \(X\) over 50 points (or bins) and calculate an entropy of \(H_2(X)>\log_2 50\), something must be wrong with our implementation of the discrete entropy computation.
Section 2: Information, neurons, and spikes#
Estimated timing to here from start of tutorial: 20 min
Video 2: Entropy of different distributions#
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Entropy_of_different_distributions_Video")
Recall the discussion of spike times and inter-spike intervals (ISIs) from Tutorial 1. What does the information content (or distributional entropy) of these measures say about our theory of nervous systems?
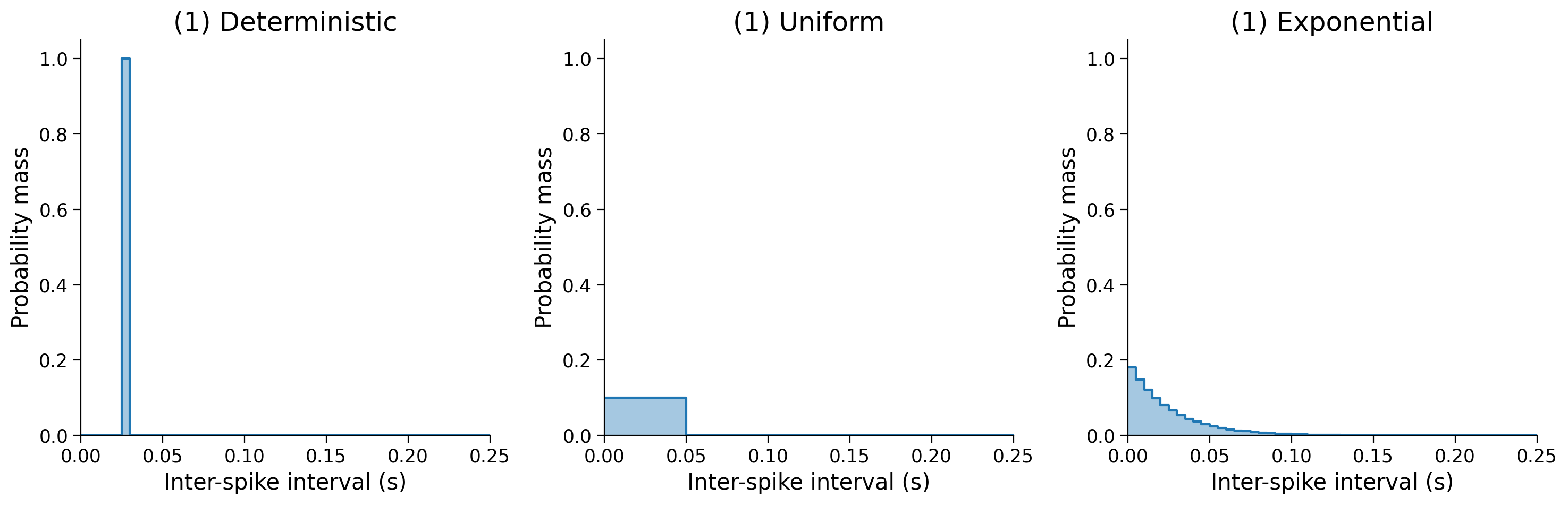
We’ll consider three hypothetical neurons that all have the same mean ISI, but with different distributions:
Deterministic
Uniform
Exponential
Fixing the mean of the ISI distribution is equivalent to fixing its inverse: the neuron’s mean firing rate. If a neuron has a fixed energy budget and each of its spikes has the same energy cost, then by fixing the mean firing rate, we are normalizing for energy expenditure. This provides a basis for comparing the entropy of different ISI distributions. In other words: if our neuron has a fixed budget, what ISI distribution should it express (all else being equal) to maximize the information content of its outputs?
Let’s construct our three distributions and see how their entropies differ.
n_bins = 50
mean_isi = 0.025
isi_range = (0, 0.25)
bins = np.linspace(*isi_range, n_bins + 1)
mean_idx = np.searchsorted(bins, mean_isi)
# 1. all mass concentrated on the ISI mean
pmf_single = np.zeros(n_bins)
pmf_single[mean_idx] = 1.0
# 2. mass uniformly distributed about the ISI mean
pmf_uniform = np.zeros(n_bins)
pmf_uniform[0:2*mean_idx] = 1 / (2 * mean_idx)
# 3. mass exponentially distributed about the ISI mean
pmf_exp = stats.expon.pdf(bins[1:], scale=mean_isi)
pmf_exp /= np.sum(pmf_exp)
Run this cell to plot the three PMFs
Show code cell source
# @markdown Run this cell to plot the three PMFs
fig, axes = plt.subplots(ncols=3, figsize=(15, 5))
dists = [# (subplot title, pmf, ylim)
("(1) Deterministic", pmf_single, (0, 1.05)),
("(1) Uniform", pmf_uniform, (0, 1.05)),
("(1) Exponential", pmf_exp, (0, 1.05))]
for ax, (label, pmf_, ylim) in zip(axes, dists):
pmf_ = np.insert(pmf_, 0, pmf_[0])
ax.plot(bins, pmf_, drawstyle="steps")
ax.fill_between(bins, pmf_, step="pre", alpha=0.4)
ax.set_title(label)
ax.set_xlabel("Inter-spike interval (s)")
ax.set_ylabel("Probability mass")
ax.set_xlim(isi_range)
ax.set_ylim(ylim)
plt.show()
print(
f"Deterministic: {entropy(pmf_single):.2f} bits",
f"Uniform: {entropy(pmf_uniform):.2f} bits",
f"Exponential: {entropy(pmf_exp):.2f} bits",
sep="\n",
)
Section 3: Calculate entropy of ISI distributions from data#
Estimated timing to here from start of tutorial: 25 min
Section 3.1: Computing probabilities from histogram#
Video 3: Probabilities from histogram#
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Probabilities_from_histogram_Video")
In the previous example we created the PMFs by hand to illustrate idealized scenarios. How would we compute them from data recorded from actual neurons?
One way is to convert the ISI histograms we’ve previously computed into discrete probability distributions using the following equation:
where \(p_i\) is the probability of an ISI falling within a particular interval \(i\) and \(n_i\) is the count of how many ISIs were observed in that interval.
Coding Exercise 3.1: Probability Mass Function#
Your second exercise is to implement a method that will produce a probability mass function from an array of ISI bin counts.
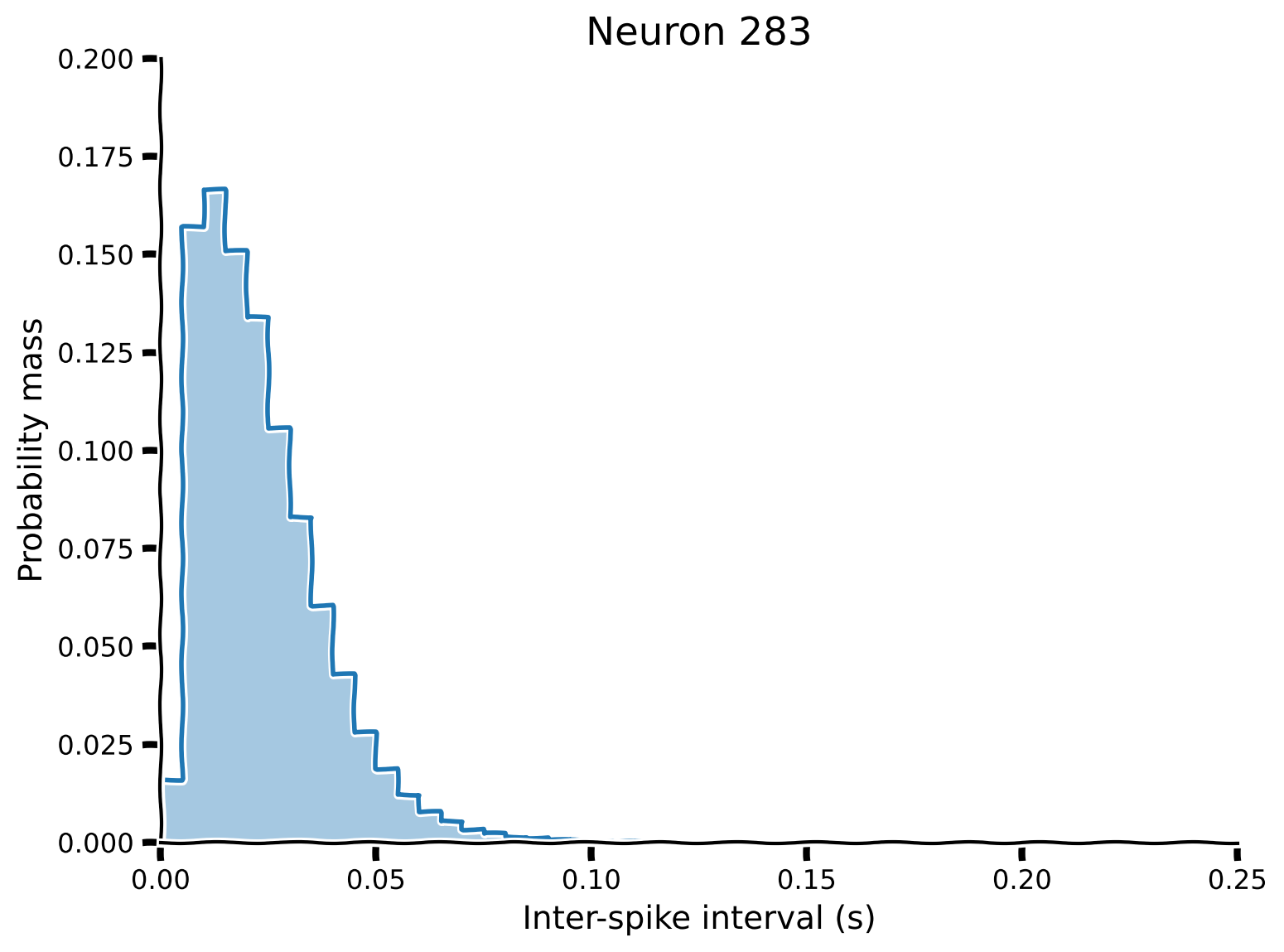
To verify your solution, we will compute the probability distribution of ISIs from real neural data taken from the Steinmetz dataset.
def pmf_from_counts(counts):
"""Given counts, normalize by the total to estimate probabilities."""
###########################################################################
# Exercise: Compute the PMF. Remove the next line to test your function
raise NotImplementedError("Student exercise: compute the PMF from ISI counts")
###########################################################################
pmf = ...
return pmf
# Get neuron index
neuron_idx = 283
# Get counts of ISIs from Steinmetz data
isi = np.diff(steinmetz_spikes[neuron_idx])
bins = np.linspace(*isi_range, n_bins + 1)
counts, _ = np.histogram(isi, bins)
# Compute pmf
pmf = pmf_from_counts(counts)
# Visualize
plot_pmf(pmf, isi_range)
Example output:
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Probability_mass_function_Exercise")
Section 3.2: Calculating entropy from pmf#
Video 4: Calculating entropy from pmf#
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Calculating_entropy_from_pmf_Video")
Now that we have the probability distribution for the actual neuron spiking activity, we can calculate its entropy.
print(f"Entropy for Neuron {neuron_idx}: {entropy(pmf):.2f} bits")
Interactive Demo 3.2: Entropy of neurons#
We can combine the above distribution plot and entropy calculation with an interactive widget to explore how the different neurons in the dataset vary in spiking activity and relative information. Note that the mean firing rate across neurons is not fixed, so some neurons with a uniform ISI distribution may have higher entropy than neurons with a more exponential distribution.
Run the cell to enable the sliders.
Show code cell source
# @markdown **Run the cell** to enable the sliders.
def _pmf_from_counts(counts):
"""Given counts, normalize by the total to estimate probabilities."""
pmf = counts / np.sum(counts)
return pmf
def _entropy(pmf):
"""Given a discrete distribution, return the Shannon entropy in bits."""
# remove non-zero entries to avoid an error from log2(0)
pmf = pmf[pmf > 0]
h = -np.sum(pmf * np.log2(pmf))
# absolute value applied to avoid getting a -0 result
return np.abs(h)
@widgets.interact(neuron=widgets.IntSlider(0, min=0, max=(len(steinmetz_spikes)-1)))
def steinmetz_pmf(neuron):
""" Given a neuron from the Steinmetz data, compute its PMF and entropy """
isi = np.diff(steinmetz_spikes[neuron])
bins = np.linspace(*isi_range, n_bins + 1)
counts, _ = np.histogram(isi, bins)
pmf = _pmf_from_counts(counts)
plot_pmf(pmf, isi_range)
plt.title(f"Neuron {neuron}: H = {_entropy(pmf):.2f} bits")
plt.show()
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Entropy_of_neurons_Interactive_Demo")
Section 4: Reflecting on why models#
Estimated timing to here from start of tutorial: 35 min
Think! 3: Reflecting on why models#
Please discuss the following questions for around 10 minutes with your group:
Have you seen why models before?
Have you ever done one?
Why are why models useful?
When are they possible? Does your field have why models?
What do we learn from constructing them?
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Reflecting_on_why_models_Discussion")
Summary#
Estimated timing of tutorial: 45 minutes
Video 5: Summary of model types#
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Summary_of_model_types_Video")
Congratulations! You’ve finished your first NMA tutorial. In this 3 part tutorial series, we used different types of models to understand the spiking behavior of neurons recorded in the Steinmetz data set.
We used “what” models to discover that the ISI distribution of real neurons is closest to an exponential distribution
We used “how” models to discover that balanced excitatory and inhibitory inputs, coupled with a leaky membrane, can give rise to neuronal spiking with exhibiting such an exponential ISI distribution
We used “why” models to discover that exponential ISI distributions contain the most information when the mean spiking is constrained
Notation#
Bonus#
Bonus Section 1: The foundations for Entropy#
In his foundational 1948 paper on information theory, Claude Shannon began with three criteria for a function \(H\) defining the entropy of a discrete distribution of probability masses \(p_i\in p(X)\) over the points \(x_i\in X\):
\(H\) should be continuous in the \(p_i\).
That is, \(H\) should change smoothly in response to smooth changes to the mass \(p_i\) on each point \(x_i\).
If all the points have equal shares of the probability mass, \(p_i=1/N\), \(H\) should be a non-decreasing function of \(N\).
That is, if \(X_N\) is the support with \(N\) discrete points and \(p(x\in X_N)\) assigns constant mass to each point, then \(H(X_1) < H(X_2) < H(X_3) < \dots\)
\(H\) should be preserved by (invariant to) the equivalent (de)composition of distributions.
For example (from Shannon’s paper) if we have a discrete distribution over three points with masses \((\frac{1}{2},\frac{1}{3},\frac{1}{6})\), then their entropy can be represented in terms of a direct choice between the three and calculated \(H(\frac{1}{2},\frac{1}{3},\frac{1}{6})\). However, it could also be represented in terms of a series of two choices:
either we sample the point with mass \(1/2\) or not (not is the other \(1/2\), whose subdivisions are not given in the first choice),
if (with probability \(1/2\)) we don’t sample the first point, we sample one of the two remaining points, masses \(1/3\) and \(1/6\).
Thus in this case we require that \(H(\frac{1}{2},\frac{1}{3},\frac{1}{6})=H(\frac{1}{2},\frac{1}{2}) + \frac{1}{2}H(\frac{1}{3}, \frac{1}{6})\)
There is a unique function (up to a linear scaling factor) which satisfies these 3 requirements:
Where the base of the logarithm \(b>1\) controls the units of entropy. The two most common cases are \(b=2\) for units of bits, and \(b=e\) for nats.
We can view this function as the expectation of the self-information over a distribution:
Self-information is just the negative logarithm of probability, and is a measure of how surprising an event sampled from the distribution would be. Events with \(p(x)=1\) are certain to occur, and their self-information is zero (as is the entropy of the distribution they compose) meaning they are totally unsurprising. The smaller the probability of an event, the higher its self-information, and the more surprising the event would be to observe.