{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {},
"id": "view-in-github"
},
"source": [
"
 "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Bonus Tutorial 4: The Kalman Filter, part 2\n",
"\n",
"**Week 3, Day 2: Hidden Dynamics**\n",
"\n",
"**By Neuromatch Academy**\n",
"\n",
"**Content creators:** Caroline Haimerl and Byron Galbraith\n",
"\n",
"**Content reviewers:** Jesse Livezey, Matt Krause, Michael Waskom, and Xaq Pitkow\n",
"\n",
"**Production editors:** Gagana B, Spiros Chavlis\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Bonus Tutorial 4: The Kalman Filter, part 2\n",
"\n",
"**Week 3, Day 2: Hidden Dynamics**\n",
"\n",
"**By Neuromatch Academy**\n",
"\n",
"**Content creators:** Caroline Haimerl and Byron Galbraith\n",
"\n",
"**Content reviewers:** Jesse Livezey, Matt Krause, Michael Waskom, and Xaq Pitkow\n",
"\n",
"**Production editors:** Gagana B, Spiros Chavlis\n",
"\n",
"
\n",
"\n",
"**Important note:** This is bonus material, included from NMA 2020. It has not been substantially revised. This means that the notation and standards are slightly different. We include it here because it provides additional information about how the Kalman filter works in two dimensions.\n",
"\n",
"
\n",
"\n",
"**Useful references:**\n",
"- Roweis, Ghahramani (1998): A unifying review of linear Gaussian Models\n",
"- Bishop (2006): Pattern Recognition and Machine Learning\n",
"\n",
"
\n",
"\n",
"**Acknowledgements:**\n",
"\n",
"This tutorial is in part based on code originally created by Caroline Haimerl for Dr. Cristina Savin's *Probabilistic Time Series* class at the Center for Data Science, New York University"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Tutorial Objectives\n",
"\n",
"In the previous tutorial we gained intuition for the Kalman filter in one dimension. In this tutorial, we will examine the **two-dimensional** Kalman filter and more of its mathematical foundations.\n",
"\n",
"In this tutorial, you will:\n",
"* Review linear dynamical systems\n",
"* Implement the Kalman filter\n",
"* Explore how the Kalman filter can be used to smooth data from an eye-tracking experiment"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @markdown\n",
"from IPython.display import IFrame\n",
"from ipywidgets import widgets\n",
"out = widgets.Output()\n",
"with out:\n",
" print(f\"If you want to download the slides: https://osf.io/download/rh23s/\")\n",
" display(IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/rh23s/?direct%26mode=render%26action=download%26mode=render\", width=730, height=410))\n",
"display(out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Setup"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install dependencies\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install dependencies\n",
"!pip install pykalman --quiet # Install PyKalman (https://pykalman.github.io/)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install and import feedback gadget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install and import feedback gadget\n",
"\n",
"!pip3 install vibecheck datatops --quiet\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
" return DatatopsContentReviewContainer(\n",
" \"\", # No text prompt\n",
" notebook_section,\n",
" {\n",
" \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
" \"name\": \"neuromatch_cn\",\n",
" \"user_key\": \"y1x3mpx5\",\n",
" },\n",
" ).render()\n",
"\n",
"\n",
"feedback_prefix = \"W3D2_T4_Bonus\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Imports\n",
"import sys\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"import pykalman\n",
"from scipy import stats"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Figure settings\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Figure settings\n",
"import logging\n",
"logging.getLogger('matplotlib.font_manager').disabled = True\n",
"\n",
"import ipywidgets as widgets # interactive display\n",
"%config InlineBackend.figure_format = 'retina'\n",
"plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Plotting functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Plotting functions\n",
"np.set_printoptions(precision=3)\n",
"\n",
"\n",
"def plot_kalman(state, observation, estimate=None, label='filter', color='r-',\n",
" title='LDS', axes=None):\n",
" if axes is None:\n",
" fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(16, 6))\n",
" ax1.plot(state[:, 0], state[:, 1], 'g-', label='true latent')\n",
" ax1.plot(observation[:, 0], observation[:, 1], 'k.', label='data')\n",
" else:\n",
" ax1, ax2 = axes\n",
"\n",
" if estimate is not None:\n",
" ax1.plot(estimate[:, 0], estimate[:, 1], color=color, label=label)\n",
" ax1.set(title=title, xlabel='X position', ylabel='Y position')\n",
" ax1.legend()\n",
"\n",
" if estimate is None:\n",
" ax2.plot(state[:, 0], observation[:, 0], '.k', label='dim 1')\n",
" ax2.plot(state[:, 1], observation[:, 1], '.', color='grey', label='dim 2')\n",
" ax2.set(title='correlation', xlabel='latent', ylabel='measured')\n",
" else:\n",
" ax2.plot(state[:, 0], estimate[:, 0], '.', color=color,\n",
" label='latent dim 1')\n",
" ax2.plot(state[:, 1], estimate[:, 1], 'x', color=color,\n",
" label='latent dim 2')\n",
" ax2.set(title='correlation',\n",
" xlabel='real latent',\n",
" ylabel='estimated latent')\n",
" ax2.legend()\n",
" plt.show()\n",
" return ax1, ax2\n",
"\n",
"\n",
"def plot_gaze_data(data, img=None, ax=None):\n",
" # overlay gaze on stimulus\n",
" if ax is None:\n",
" fig, ax = plt.subplots(figsize=(8, 6))\n",
"\n",
" xlim = None\n",
" ylim = None\n",
" if img is not None:\n",
" ax.imshow(img, aspect='auto')\n",
" ylim = (img.shape[0], 0)\n",
" xlim = (0, img.shape[1])\n",
"\n",
" ax.scatter(data[:, 0], data[:, 1], c='m', s=100, alpha=0.7)\n",
" ax.set(xlim=xlim, ylim=ylim)\n",
"\n",
" return ax\n",
"\n",
"\n",
"def plot_kf_state(kf, data, ax, show=True):\n",
" mu_0 = np.ones(kf.n_dim_state)\n",
" mu_0[:data.shape[1]] = data[0]\n",
" kf.initial_state_mean = mu_0\n",
"\n",
" mu, sigma = kf.smooth(data)\n",
" ax.plot(mu[:, 0], mu[:, 1], 'limegreen', linewidth=3, zorder=1)\n",
" ax.scatter(mu[0, 0], mu[0, 1], c='orange', marker='>', s=200, zorder=2)\n",
" ax.scatter(mu[-1, 0], mu[-1, 1], c='orange', marker='s', s=200, zorder=2)\n",
" if show:\n",
" plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Data retrieval and loading\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"#@title Data retrieval and loading\n",
"import io\n",
"import os\n",
"import hashlib\n",
"import requests\n",
"\n",
"fname = \"W2D3_mit_eyetracking_2009.npz\"\n",
"url = \"https://osf.io/jfk8w/download\"\n",
"expected_md5 = \"20c7bc4a6f61f49450997e381cf5e0dd\"\n",
"\n",
"if not os.path.isfile(fname):\n",
" try:\n",
" r = requests.get(url)\n",
" except requests.ConnectionError:\n",
" print(\"!!! Failed to download data !!!\")\n",
" else:\n",
" if r.status_code != requests.codes.ok:\n",
" print(\"!!! Failed to download data !!!\")\n",
" elif hashlib.md5(r.content).hexdigest() != expected_md5:\n",
" print(\"!!! Data download appears corrupted !!!\")\n",
" else:\n",
" with open(fname, \"wb\") as fid:\n",
" fid.write(r.content)\n",
"\n",
"def load_eyetracking_data(data_fname=fname):\n",
"\n",
" with np.load(data_fname, allow_pickle=True) as dobj:\n",
" data = dict(**dobj)\n",
"\n",
" images = [plt.imread(io.BytesIO(stim), format='JPG')\n",
" for stim in data['stimuli']]\n",
" subjects = data['subjects']\n",
"\n",
" return subjects, images"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 0: Introduction"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 1: Introduction\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"#@title Video 1: Introduction\n",
"# Insert the ID of the corresponding youtube video\n",
"from IPython.display import YouTubeVideo\n",
"video = YouTubeVideo(id=\"6f_51L3i5aQ\", width=730, height=410, fs=1)\n",
"print(\"Video available at https://youtu.be/\" + video.id)\n",
"video"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Introduction_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 1: Linear Dynamical System (LDS)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 2: Linear Dynamical Systems\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"#@title Video 2: Linear Dynamical Systems\n",
"# Insert the ID of the corresponding youtube video\n",
"from IPython.display import YouTubeVideo\n",
"video = YouTubeVideo(id=\"2SWh639YgEg\", width=730, height=410, fs=1)\n",
"print(\"Video available at https://youtu.be/\" + video.id)\n",
"video"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Linear_Dynamical_Systems_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Kalman filter definitions\n",
"\n",
"The latent state $s_t$ evolves as a stochastic linear dynamical system in discrete time, with a dynamics matrix $D$:\n",
"\n",
"\\begin{equation}\n",
"s_t = Ds_{t-1}+w_t\n",
"\\end{equation}\n",
"\n",
"Just as in the HMM, the structure is a Markov chain where the state at time point $t$ is conditionally independent of previous states given the state at time point $t-1$.\n",
"\n",
"Sensory measurements $m_t$ (observations) are noisy linear projections of the latent state:\n",
"\n",
"\\begin{equation}\n",
"m_t = Hs_{t}+\\eta_t\n",
"\\end{equation}\n",
"\n",
"Both states and measurements have Gaussian variability, often called noise: 'process noise' $w_t$ for the states, and 'measurement' or 'observation noise' $\\eta_t$ for the measurements. The initial state is also Gaussian distributed. These quantities have means and covariances:\n",
"\n",
"\\begin{eqnarray}\n",
"w_t & \\sim & \\mathcal{N}(0, Q) \\\\\n",
"\\eta_t & \\sim & \\mathcal{N}(0, R) \\\\\n",
"s_0 & \\sim & \\mathcal{N}(\\mu_0, \\Sigma_0)\n",
"\\end{eqnarray}\n",
"\n",
"As a consequence, $s_t$, $m_t$ and their joint distributions are Gaussian. This makes all of the math analytically tractable using linear algebra, so we can easily compute the marginal and conditional distributions we will use for inferring the current state given the entire history of measurements.\n",
"\n",
"_**Please note**: we are trying to create uniform notation across tutorials. In some videos created in 2020, measurements $m_t$ were denoted $y_t$, and the Dynamics matrix $D$ was denoted $F$. We apologize for any confusion!_"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 1.1: Sampling from a latent linear dynamical system\n",
"\n",
"The first thing we will investigate is how to generate timecourse samples from a linear dynamical system given its parameters. We will start by defining the following system:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# task dimensions\n",
"n_dim_state = 2\n",
"n_dim_obs = 2\n",
"\n",
"# initialize model parameters\n",
"params = {\n",
" 'D': 0.9 * np.eye(n_dim_state), # state transition matrix\n",
" 'Q': np.eye(n_dim_obs), # state noise covariance\n",
" 'H': np.eye(n_dim_state), # observation matrix\n",
" 'R': 1.0 * np.eye(n_dim_obs), # observation noise covariance\n",
" 'mu_0': np.zeros(n_dim_state), # initial state mean\n",
" 'sigma_0': 0.1 * np.eye(n_dim_state), # initial state noise covariance\n",
"}"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Coding note**: We used a parameter dictionary `params` above. As the number of parameters we need to provide to our functions increases, it can be beneficial to condense them into a data structure like this to clean up the number of inputs we pass in. The trade-off is that we have to know what is in our data structure to use those values, rather than looking at the function signature directly."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise 1: Sampling from a linear dynamical system\n",
"\n",
"In this exercise you will implement the dynamics functions of a linear dynamical system to sample both a latent space trajectory (given parameters set above) and noisy measurements.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def sample_lds(n_timesteps, params, seed=0):\n",
" \"\"\" Generate samples from a Linear Dynamical System specified by the provided\n",
" parameters.\n",
"\n",
" Args:\n",
" n_timesteps (int): the number of time steps to simulate\n",
" params (dict): a dictionary of model parameters: (D, Q, H, R, mu_0, sigma_0)\n",
" seed (int): a random seed to use for reproducibility checks\n",
"\n",
" Returns:\n",
" ndarray, ndarray: the generated state and observation data\n",
" \"\"\"\n",
" n_dim_state = params['D'].shape[0]\n",
" n_dim_obs = params['H'].shape[0]\n",
"\n",
" # set seed\n",
" np.random.seed(seed)\n",
"\n",
" # precompute random samples from the provided covariance matrices\n",
" # mean defaults to 0\n",
" mi = stats.multivariate_normal(cov=params['Q']).rvs(n_timesteps)\n",
" eta = stats.multivariate_normal(cov=params['R']).rvs(n_timesteps)\n",
"\n",
" # initialize state and observation arrays\n",
" state = np.zeros((n_timesteps, n_dim_state))\n",
" obs = np.zeros((n_timesteps, n_dim_obs))\n",
"\n",
" ###################################################################\n",
" ## TODO for students: compute the next state and observation values\n",
" # Fill out function and remove\n",
" raise NotImplementedError(\"Student exercise: compute the next state and observation values\")\n",
" ###################################################################\n",
"\n",
" # simulate the system\n",
" for t in range(n_timesteps):\n",
" # write the expressions for computing state values given the time step\n",
" if t == 0:\n",
" state[t] = ...\n",
" else:\n",
" state[t] = ...\n",
"\n",
" # write the expression for computing the observation\n",
" obs[t] = ...\n",
"\n",
" return state, obs\n",
"\n",
"\n",
"state, obs = sample_lds(100, params)\n",
"print('sample at t=3 ', state[3])\n",
"plot_kalman(state, obs, title='sample')"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D2_HiddenDynamics/solutions/W3D2_Tutorial4_Solution_82cbb57a.py)\n",
"\n",
"*Example output:*\n",
"\n",
"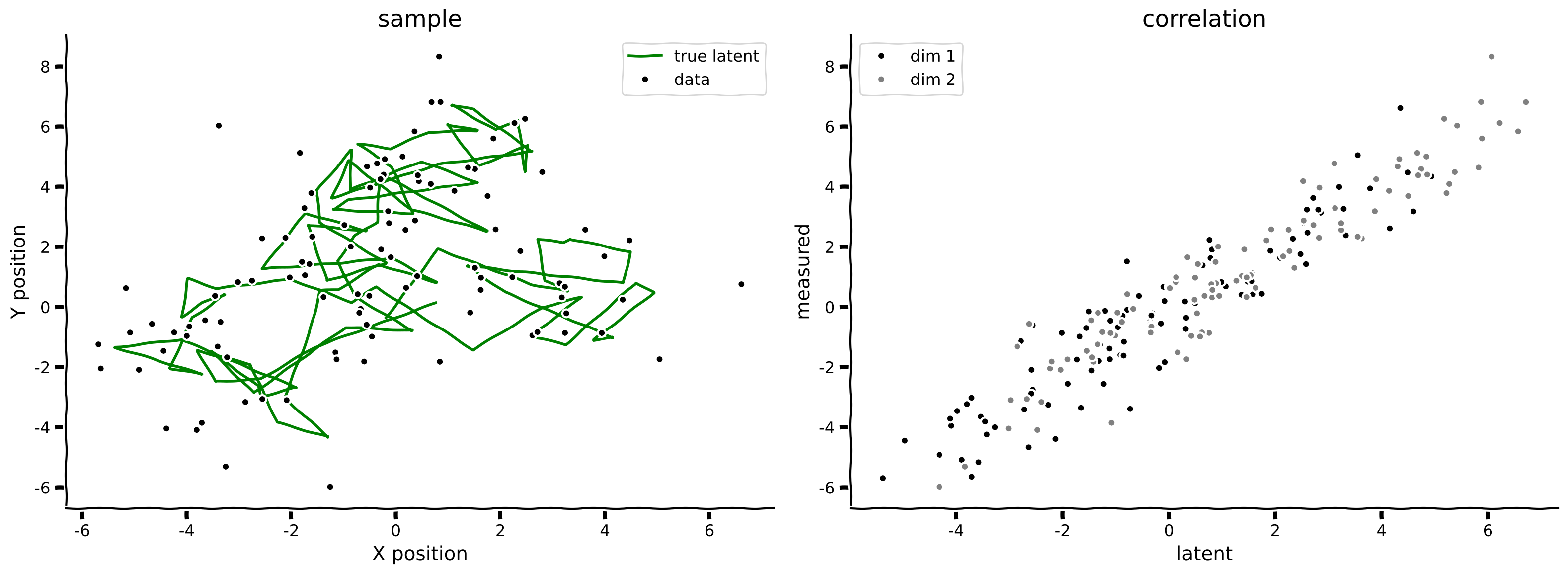 \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Sampling_from_a_linear_dynamical_system_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 1: Adjusting System Dynamics\n",
"\n",
"To test your understanding of the parameters of a linear dynamical system, think about what you would expect if you made the following changes:\n",
"1. Reduce observation noise $R$\n",
"2. Increase respective temporal dynamics $D$\n",
"\n",
"Use the interactive widget below to vary the values of $R$ and $D$."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Make sure you execute this cell to enable the widget!\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Make sure you execute this cell to enable the widget!\n",
"\n",
"@widgets.interact(R=widgets.FloatLogSlider(1., min=-2, max=2),\n",
" D=widgets.FloatSlider(0.9, min=0.0, max=1.0, step=.01))\n",
"def explore_dynamics(R=0.1, D=0.5):\n",
" params = {\n",
" 'D': D * np.eye(n_dim_state), # state transition matrix\n",
" 'Q': np.eye(n_dim_obs), # state noise covariance\n",
" 'H': np.eye(n_dim_state), # observation matrix\n",
" 'R': R * np.eye(n_dim_obs), # observation noise covariance\n",
" 'mu_0': np.zeros(n_dim_state), # initial state mean,\n",
" 'sigma_0': 0.1 * np.eye(n_dim_state), # initial state noise covariance\n",
" }\n",
"\n",
" state, obs = sample_lds(100, params)\n",
" plot_kalman(state, obs, title='sample')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Adjusting_System_Dynamics_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 2: Kalman Filtering\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 3: Kalman Filtering\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"#@title Video 3: Kalman Filtering\n",
"# Insert the ID of the corresponding youtube video\n",
"from IPython.display import YouTubeVideo\n",
"video = YouTubeVideo(id=\"VboZOV9QMOI\", width=730, height=410, fs=1)\n",
"print(\"Video available at https://youtu.be/\" + video.id)\n",
"video"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Kalman_filtering_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We want to infer the latent state variable $s_t$ given the measured (observed) variable $m_t$.\n",
"\n",
"\\begin{equation}\n",
"P(s_t|m_1, ..., m_t, m_{t+1}, ..., m_T)\\sim \\mathcal{N}(\\hat{\\mu}_t, \\hat{\\Sigma_t})\n",
"\\end{equation}"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"First we obtain estimates of the latent state by running the filtering from $t=0,....T$."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\\begin{equation}\n",
"s_t^{\\rm pred}\\sim \\mathcal{N}(\\hat{\\mu}_t^{\\rm pred},\\hat{\\Sigma}_t^{\\rm pred})\\end{equation}\n",
"\n",
"Where $\\hat{\\mu}_t^{\\rm pred}$ and $\\hat{\\Sigma}_t^{\\rm pred}$ are derived as follows:\n",
"\n",
"\\begin{eqnarray}\n",
"\\hat{\\mu}_1^{\\rm pred} & = & D\\hat{\\mu}_{0} \\\\\n",
"\\hat{\\mu}_t^{\\rm pred} & = & D\\hat{\\mu}_{t-1}\n",
"\\end{eqnarray}\n",
"\n",
"This is the prediction for $s_t$ obtained simply by taking the expected value of $s_{t-1}$ and projecting it forward one step using the transition matrix $D$.\n",
"We do the same for the covariance, taking into account the noise covariance $Q$ and the fact that scaling a variable by $D$ scales its covariance $\\Sigma$ as $D\\Sigma D^\\mathsf{T}$:\n",
"\n",
"\\begin{eqnarray}\n",
"\\hat{\\Sigma}_0^{\\rm pred} & = & D\\hat{\\Sigma}_{0}D^\\mathsf{T}+Q \\\\\n",
"\\hat{\\Sigma}_t^{\\rm pred} & = & D\\hat{\\Sigma}_{t-1}D^\\mathsf{T}+Q\n",
"\\end{eqnarray}\n",
"\n",
"\n",
"We then use a Bayesian update from the newest measurements to obtain $\\hat{\\mu}_t^{\\rm filter}$ and $\\hat{\\Sigma}_t^{\\rm filter}$\n",
"\n",
"Project our prediction to observational space:\n",
"\n",
"\\begin{equation}\n",
"m_t^{\\rm pred}\\sim \\mathcal{N}(H\\hat{\\mu}_t^{\\rm pred}, H\\hat{\\Sigma}_t^{\\rm pred}H^\\mathsf{T}+R)\n",
"\\end{equation}\n",
"\n",
"update prediction by actual data:\n",
"\n",
"\\begin{eqnarray}\n",
"s_t^{\\rm filter} & \\sim & \\mathcal{N}(\\hat{\\mu}_t^{\\rm filter}, \\hat{\\Sigma}_t^{\\rm filter}) \\\\\n",
"\\hat{\\mu}_t^{\\rm filter} & = & \\hat{\\mu}_t^{\\rm pred}+K_t(m_t-H\\hat{\\mu}_t^{\\rm pred}) \\\\\n",
"\\hat{\\Sigma}_t^{\\rm filter} & = & (I-K_tH)\\hat{\\Sigma}_t^{\\rm pred}\n",
"\\end{eqnarray}\n",
"\n",
"Kalman gain matrix:\n",
"\\begin{equation}\n",
"K_t=\\hat{\\Sigma}_t^{\\rm pred}H^T(H\\hat{\\Sigma}_t^{\\rm pred}H^\\mathsf{T}+R)^{-1}\n",
"\\end{equation}\n",
"\n",
"We use the latent-only prediction to project it to the observational space and compute a correction proportional to the error $m_t-HDz_{t-1}$ between prediction and data. The coefficient of this correction is the Kalman gain matrix."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Interpretations**\n",
"\n",
"If measurement noise is small and dynamics are fast, then estimation will depend mostly on currently observed data.\n",
"If the measurement noise is large, then the Kalman filter uses past observations as well, combining them as long as the underlying state is at least somewhat predictable."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"In order to explore the impact of filtering, we will use the following noisy oscillatory system:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# task dimensions\n",
"n_dim_state = 2\n",
"n_dim_obs = 2\n",
"T = 100\n",
"\n",
"# initialize model parameters\n",
"params = {\n",
" 'D': np.array([[1., 1.], [-(2*np.pi/20.)**2., .9]]), # state transition matrix\n",
" 'Q': np.eye(n_dim_obs), # state noise covariance\n",
" 'H': np.eye(n_dim_state), # observation matrix\n",
" 'R': 100.0 * np.eye(n_dim_obs), # observation noise covariance\n",
" 'mu_0': np.zeros(n_dim_state), # initial state mean\n",
" 'sigma_0': 0.1 * np.eye(n_dim_state), # initial state noise covariance\n",
"}\n",
"\n",
"state, obs = sample_lds(T, params)\n",
"plot_kalman(state, obs, title='Sample')"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Coding Exercise 2: Implement Kalman filtering\n",
"\n",
"In this exercise you will implement the Kalman filter (forward) process. Your focus will be on writing the expressions for the Kalman gain, filter mean, and filter covariance at each time step (refer to the equations above)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def kalman_filter(data, params):\n",
" \"\"\" Perform Kalman filtering (forward pass) on the data given the provided\n",
" system parameters.\n",
"\n",
" Args:\n",
" data (ndarray): a sequence of observations of shape(n_timesteps, n_dim_obs)\n",
" params (dict): a dictionary of model parameters: (D, Q, H, R, mu_0, sigma_0)\n",
"\n",
" Returns:\n",
" ndarray, ndarray: the filtered system means and noise covariance values\n",
" \"\"\"\n",
" # pulled out of the params dict for convenience\n",
" D = params['D']\n",
" Q = params['Q']\n",
" H = params['H']\n",
" R = params['R']\n",
"\n",
" n_dim_state = D.shape[0]\n",
" n_dim_obs = H.shape[0]\n",
" I = np.eye(n_dim_state) # identity matrix\n",
"\n",
" # state tracking arrays\n",
" mu = np.zeros((len(data), n_dim_state))\n",
" sigma = np.zeros((len(data), n_dim_state, n_dim_state))\n",
"\n",
" # filter the data\n",
" for t, y in enumerate(data):\n",
" if t == 0:\n",
" mu_pred = params['mu_0']\n",
" sigma_pred = params['sigma_0']\n",
" else:\n",
" mu_pred = D @ mu[t-1]\n",
" sigma_pred = D @ sigma[t-1] @ D.T + Q\n",
"\n",
" ###########################################################################\n",
" ## TODO for students: compute the filtered state mean and covariance values\n",
" # Fill out function and remove\n",
" raise NotImplementedError(\"Student exercise: compute the filtered state mean and covariance values\")\n",
" ###########################################################################\n",
" # write the expression for computing the Kalman gain\n",
" K = ...\n",
" # write the expression for computing the filtered state mean\n",
" mu[t] = ...\n",
" # write the expression for computing the filtered state noise covariance\n",
" sigma[t] = ...\n",
"\n",
" return mu, sigma\n",
"\n",
"\n",
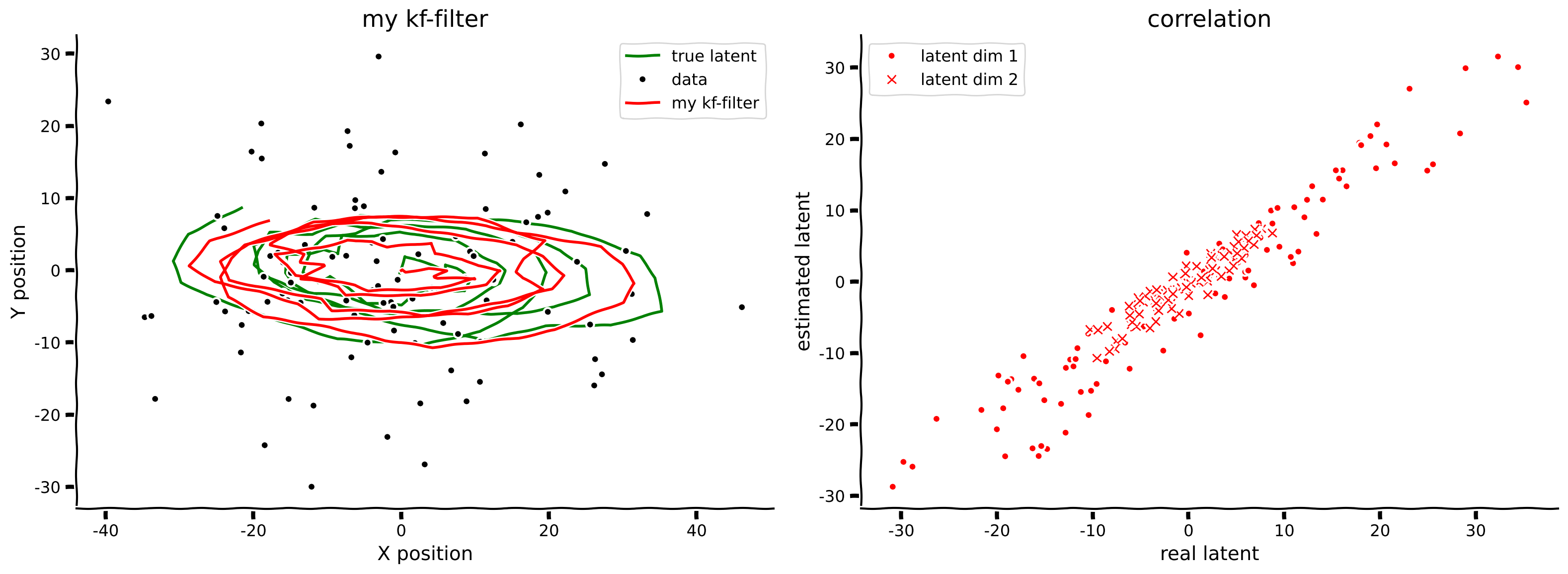
"filtered_state_means, filtered_state_covariances = kalman_filter(obs, params)\n",
"plot_kalman(state, obs, filtered_state_means, title=\"my kf-filter\",\n",
" color='r', label='my kf-filter')"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D2_HiddenDynamics/solutions/W3D2_Tutorial4_Solution_3549ecf3.py)\n",
"\n",
"*Example output:*\n",
"\n",
"
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Sampling_from_a_linear_dynamical_system_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 1: Adjusting System Dynamics\n",
"\n",
"To test your understanding of the parameters of a linear dynamical system, think about what you would expect if you made the following changes:\n",
"1. Reduce observation noise $R$\n",
"2. Increase respective temporal dynamics $D$\n",
"\n",
"Use the interactive widget below to vary the values of $R$ and $D$."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Make sure you execute this cell to enable the widget!\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Make sure you execute this cell to enable the widget!\n",
"\n",
"@widgets.interact(R=widgets.FloatLogSlider(1., min=-2, max=2),\n",
" D=widgets.FloatSlider(0.9, min=0.0, max=1.0, step=.01))\n",
"def explore_dynamics(R=0.1, D=0.5):\n",
" params = {\n",
" 'D': D * np.eye(n_dim_state), # state transition matrix\n",
" 'Q': np.eye(n_dim_obs), # state noise covariance\n",
" 'H': np.eye(n_dim_state), # observation matrix\n",
" 'R': R * np.eye(n_dim_obs), # observation noise covariance\n",
" 'mu_0': np.zeros(n_dim_state), # initial state mean,\n",
" 'sigma_0': 0.1 * np.eye(n_dim_state), # initial state noise covariance\n",
" }\n",
"\n",
" state, obs = sample_lds(100, params)\n",
" plot_kalman(state, obs, title='sample')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Adjusting_System_Dynamics_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 2: Kalman Filtering\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 3: Kalman Filtering\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"#@title Video 3: Kalman Filtering\n",
"# Insert the ID of the corresponding youtube video\n",
"from IPython.display import YouTubeVideo\n",
"video = YouTubeVideo(id=\"VboZOV9QMOI\", width=730, height=410, fs=1)\n",
"print(\"Video available at https://youtu.be/\" + video.id)\n",
"video"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Kalman_filtering_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We want to infer the latent state variable $s_t$ given the measured (observed) variable $m_t$.\n",
"\n",
"\\begin{equation}\n",
"P(s_t|m_1, ..., m_t, m_{t+1}, ..., m_T)\\sim \\mathcal{N}(\\hat{\\mu}_t, \\hat{\\Sigma_t})\n",
"\\end{equation}"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"First we obtain estimates of the latent state by running the filtering from $t=0,....T$."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\\begin{equation}\n",
"s_t^{\\rm pred}\\sim \\mathcal{N}(\\hat{\\mu}_t^{\\rm pred},\\hat{\\Sigma}_t^{\\rm pred})\\end{equation}\n",
"\n",
"Where $\\hat{\\mu}_t^{\\rm pred}$ and $\\hat{\\Sigma}_t^{\\rm pred}$ are derived as follows:\n",
"\n",
"\\begin{eqnarray}\n",
"\\hat{\\mu}_1^{\\rm pred} & = & D\\hat{\\mu}_{0} \\\\\n",
"\\hat{\\mu}_t^{\\rm pred} & = & D\\hat{\\mu}_{t-1}\n",
"\\end{eqnarray}\n",
"\n",
"This is the prediction for $s_t$ obtained simply by taking the expected value of $s_{t-1}$ and projecting it forward one step using the transition matrix $D$.\n",
"We do the same for the covariance, taking into account the noise covariance $Q$ and the fact that scaling a variable by $D$ scales its covariance $\\Sigma$ as $D\\Sigma D^\\mathsf{T}$:\n",
"\n",
"\\begin{eqnarray}\n",
"\\hat{\\Sigma}_0^{\\rm pred} & = & D\\hat{\\Sigma}_{0}D^\\mathsf{T}+Q \\\\\n",
"\\hat{\\Sigma}_t^{\\rm pred} & = & D\\hat{\\Sigma}_{t-1}D^\\mathsf{T}+Q\n",
"\\end{eqnarray}\n",
"\n",
"\n",
"We then use a Bayesian update from the newest measurements to obtain $\\hat{\\mu}_t^{\\rm filter}$ and $\\hat{\\Sigma}_t^{\\rm filter}$\n",
"\n",
"Project our prediction to observational space:\n",
"\n",
"\\begin{equation}\n",
"m_t^{\\rm pred}\\sim \\mathcal{N}(H\\hat{\\mu}_t^{\\rm pred}, H\\hat{\\Sigma}_t^{\\rm pred}H^\\mathsf{T}+R)\n",
"\\end{equation}\n",
"\n",
"update prediction by actual data:\n",
"\n",
"\\begin{eqnarray}\n",
"s_t^{\\rm filter} & \\sim & \\mathcal{N}(\\hat{\\mu}_t^{\\rm filter}, \\hat{\\Sigma}_t^{\\rm filter}) \\\\\n",
"\\hat{\\mu}_t^{\\rm filter} & = & \\hat{\\mu}_t^{\\rm pred}+K_t(m_t-H\\hat{\\mu}_t^{\\rm pred}) \\\\\n",
"\\hat{\\Sigma}_t^{\\rm filter} & = & (I-K_tH)\\hat{\\Sigma}_t^{\\rm pred}\n",
"\\end{eqnarray}\n",
"\n",
"Kalman gain matrix:\n",
"\\begin{equation}\n",
"K_t=\\hat{\\Sigma}_t^{\\rm pred}H^T(H\\hat{\\Sigma}_t^{\\rm pred}H^\\mathsf{T}+R)^{-1}\n",
"\\end{equation}\n",
"\n",
"We use the latent-only prediction to project it to the observational space and compute a correction proportional to the error $m_t-HDz_{t-1}$ between prediction and data. The coefficient of this correction is the Kalman gain matrix."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Interpretations**\n",
"\n",
"If measurement noise is small and dynamics are fast, then estimation will depend mostly on currently observed data.\n",
"If the measurement noise is large, then the Kalman filter uses past observations as well, combining them as long as the underlying state is at least somewhat predictable."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"In order to explore the impact of filtering, we will use the following noisy oscillatory system:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# task dimensions\n",
"n_dim_state = 2\n",
"n_dim_obs = 2\n",
"T = 100\n",
"\n",
"# initialize model parameters\n",
"params = {\n",
" 'D': np.array([[1., 1.], [-(2*np.pi/20.)**2., .9]]), # state transition matrix\n",
" 'Q': np.eye(n_dim_obs), # state noise covariance\n",
" 'H': np.eye(n_dim_state), # observation matrix\n",
" 'R': 100.0 * np.eye(n_dim_obs), # observation noise covariance\n",
" 'mu_0': np.zeros(n_dim_state), # initial state mean\n",
" 'sigma_0': 0.1 * np.eye(n_dim_state), # initial state noise covariance\n",
"}\n",
"\n",
"state, obs = sample_lds(T, params)\n",
"plot_kalman(state, obs, title='Sample')"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Coding Exercise 2: Implement Kalman filtering\n",
"\n",
"In this exercise you will implement the Kalman filter (forward) process. Your focus will be on writing the expressions for the Kalman gain, filter mean, and filter covariance at each time step (refer to the equations above)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def kalman_filter(data, params):\n",
" \"\"\" Perform Kalman filtering (forward pass) on the data given the provided\n",
" system parameters.\n",
"\n",
" Args:\n",
" data (ndarray): a sequence of observations of shape(n_timesteps, n_dim_obs)\n",
" params (dict): a dictionary of model parameters: (D, Q, H, R, mu_0, sigma_0)\n",
"\n",
" Returns:\n",
" ndarray, ndarray: the filtered system means and noise covariance values\n",
" \"\"\"\n",
" # pulled out of the params dict for convenience\n",
" D = params['D']\n",
" Q = params['Q']\n",
" H = params['H']\n",
" R = params['R']\n",
"\n",
" n_dim_state = D.shape[0]\n",
" n_dim_obs = H.shape[0]\n",
" I = np.eye(n_dim_state) # identity matrix\n",
"\n",
" # state tracking arrays\n",
" mu = np.zeros((len(data), n_dim_state))\n",
" sigma = np.zeros((len(data), n_dim_state, n_dim_state))\n",
"\n",
" # filter the data\n",
" for t, y in enumerate(data):\n",
" if t == 0:\n",
" mu_pred = params['mu_0']\n",
" sigma_pred = params['sigma_0']\n",
" else:\n",
" mu_pred = D @ mu[t-1]\n",
" sigma_pred = D @ sigma[t-1] @ D.T + Q\n",
"\n",
" ###########################################################################\n",
" ## TODO for students: compute the filtered state mean and covariance values\n",
" # Fill out function and remove\n",
" raise NotImplementedError(\"Student exercise: compute the filtered state mean and covariance values\")\n",
" ###########################################################################\n",
" # write the expression for computing the Kalman gain\n",
" K = ...\n",
" # write the expression for computing the filtered state mean\n",
" mu[t] = ...\n",
" # write the expression for computing the filtered state noise covariance\n",
" sigma[t] = ...\n",
"\n",
" return mu, sigma\n",
"\n",
"\n",
"filtered_state_means, filtered_state_covariances = kalman_filter(obs, params)\n",
"plot_kalman(state, obs, filtered_state_means, title=\"my kf-filter\",\n",
" color='r', label='my kf-filter')"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D2_HiddenDynamics/solutions/W3D2_Tutorial4_Solution_3549ecf3.py)\n",
"\n",
"*Example output:*\n",
"\n",
" \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Implement_Kalman_filtering_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 3: Fitting Eye Gaze Data"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 4: Fitting Eye Gaze Data\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"#@title Video 4: Fitting Eye Gaze Data\n",
"# Insert the ID of the corresponding youtube video\n",
"from IPython.display import YouTubeVideo\n",
"video = YouTubeVideo(id=\"M7OuXmVWHGI\", width=730, height=410, fs=1)\n",
"print(\"Video available at https://youtu.be/\" + video.id)\n",
"video"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Fitting_Eye_Gaze_Data_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Tracking eye gaze is used in both experimental and user interface applications. Getting an accurate estimation of where someone is looking on a screen in pixel coordinates can be challenging, however, due to the various sources of noise inherent in obtaining these measurements. A main source of noise is the general accuracy of the eye tracker device itself and how well it maintains calibration over time. Changes in ambient light or subject position can further reduce accuracy of the sensor. Eye blinks introduce a different form of noise as interruptions in the data stream which also need to be addressed.\n",
"\n",
"Fortunately we have a candidate solution for handling noisy eye gaze data in the Kalman filter we just learned about. Let's look at how we can apply these methods to a small subset of data taken from the [MIT Eyetracking Database](http://people.csail.mit.edu/tjudd/WherePeopleLook/index.html) [[Judd et al. 2009](http://people.csail.mit.edu/tjudd/WherePeopleLook/Docs/wherepeoplelook.pdf)]. This data was collected as part of an effort to model [visual saliency](http://www.scholarpedia.org/article/Visual_salience) -- given an image, can we predict where a person is most likely going to look."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# load eyetracking data\n",
"subjects, images = load_eyetracking_data()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Interactive Demo 2: Tracking Eye Gaze\n",
"\n",
"We have three stimulus images and five different subjects' gaze data. Each subject fixated in the center of the screen before the image appeared, then had a few seconds to freely look around. You can use the widget below to see how different subjects visually scanned the presented image. A subject ID of -1 will show the stimulus images without any overlaid gaze trace.\n",
"\n",
"Note that the images are rescaled below for display purposes, they were in their original aspect ratio during the task itself."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Make sure you execute this cell to enable the widget!\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Make sure you execute this cell to enable the widget!\n",
"\n",
"@widgets.interact(subject_id=widgets.IntSlider(-1, min=-1, max=4),\n",
" image_id=widgets.IntSlider(0, min=0, max=2))\n",
"def plot_subject_trace(subject_id=-1, image_id=0):\n",
" if subject_id == -1:\n",
" subject = np.zeros((3, 0, 2))\n",
" else:\n",
" subject = subjects[subject_id]\n",
" data = subject[image_id]\n",
" img = images[image_id]\n",
"\n",
" fig, ax = plt.subplots()\n",
" ax.imshow(img, aspect='auto')\n",
" ax.scatter(data[:, 0], data[:, 1], c='m', s=100, alpha=0.7)\n",
" ax.set(xlim=(0, img.shape[1]), ylim=(img.shape[0], 0))\n",
" plt.show(fig)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Tracking_Eye_Gaze_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 3.1: Fitting data with `pykalman`\n",
"\n",
"Now that we have data, we'd like to use Kalman filtering to give us a better estimate of the true gaze. Up until this point we've known the parameters of our LDS, but here we need to estimate them from data directly. We will use the `pykalman` package to handle this estimation using the EM algorithm, a useful and influential learning algorithm described briefly in the bonus material.\n",
"\n",
"Before exploring fitting models with `pykalman` it's worth pointing out some naming conventions used by the library:\n",
"\n",
"\\begin{align}\n",
"D &: \\texttt{transition_matrices} &\n",
"Q &: \\texttt{transition_covariance} \\\\\n",
"H &: \\texttt{observation_matrices} &\n",
"R &: \\texttt{observation_covariance} \\\\\n",
"\\mu_0 &: \\texttt{initial_state_mean} & \\Sigma_0 &: \\texttt{initial_state_covariance}\n",
"\\end{align}"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The first thing we need to do is provide a guess at the dimensionality of the latent state. Let's start by assuming the dynamics line-up directly with the observation data (pixel x,y-coordinates), and so we have a state dimension of 2.\n",
"\n",
"We also need to decide which parameters we want the EM algorithm to fit. In this case, we will let the EM algorithm discover the dynamics parameters i.e. the $D$, $Q$, $H$, and $R$ matrices.\n",
"\n",
"We set up our `pykalman` `KalmanFilter` object with these settings using the code below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# set up our KalmanFilter object and tell it which parameters we want to\n",
"# estimate\n",
"np.random.seed(1)\n",
"\n",
"n_dim_obs = 2\n",
"n_dim_state = 2\n",
"\n",
"kf = pykalman.KalmanFilter(\n",
" n_dim_state=n_dim_state,\n",
" n_dim_obs=n_dim_obs,\n",
" em_vars=['transition_matrices', 'transition_covariance',\n",
" 'observation_matrices', 'observation_covariance']\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Because we know from the reported experimental design that subjects fixated in the center of the screen right before the image appears, we can set the initial starting state estimate $\\mu_0$ as being the center pixel of the stimulus image (the first data point in this sample dataset) with a correspondingly low initial noise covariance $\\Sigma_0$. Once we have everything set, it's time to fit some data."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Choose a subject and stimulus image\n",
"subject_id = 1\n",
"image_id = 2\n",
"data = subjects[subject_id][image_id]\n",
"\n",
"# Provide the initial states\n",
"kf.initial_state_mean = data[0]\n",
"kf.initial_state_covariance = 0.1*np.eye(n_dim_state)\n",
"\n",
"# Estimate the parameters from data using the EM algorithm\n",
"kf.em(data)\n",
"\n",
"print(f'D=\\n{kf.transition_matrices}')\n",
"print(f'Q =\\n{kf.transition_covariance}')\n",
"print(f'H =\\n{kf.observation_matrices}')\n",
"print(f'R =\\n{kf.observation_covariance}')"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We see that the EM algorithm has found fits for the various dynamics parameters. One thing you will note is that both the state and observation matrices are close to the identity matrix, which means the x- and y-coordinate dynamics are independent of each other and primarily impacted by the noise covariances.\n",
"\n",
"We can now use this model to smooth the observed data from the subject. In addition to the source image, we can also see how this model will work with the gaze recorded by the same subject on the other images as well, or even with different subjects.\n",
"\n",
"Below are the three stimulus images overlaid with recorded gaze in magenta and smoothed state from the filter in green, with gaze begin (orange triangle) and gaze end (orange square) markers."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Make sure you execute this cell to enable the widget!\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Make sure you execute this cell to enable the widget!\n",
"\n",
"@widgets.interact(subject_id=widgets.IntSlider(1, min=0, max=4))\n",
"def plot_smoothed_traces(subject_id=0):\n",
" subject = subjects[subject_id]\n",
" fig, axes = plt.subplots(ncols=3, figsize=(18, 4))\n",
" for data, img, ax in zip(subject, images, axes):\n",
" ax = plot_gaze_data(data, img=img, ax=ax)\n",
" plot_kf_state(kf, data, ax, show=False)\n",
" plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_DaySummary\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Discussion questions\n",
"\n",
"1. Why do you think one trace from one subject was sufficient to provide a decent fit across all subjects? If you were to go back and change the subject_id and/or image_id for when we fit the data using EM, do you think the fits would be different?\n",
"\n",
"2. We don't think the eye is exactly following a linear dynamical system. Nonetheless that is what we assumed for this exercise when we applied a Kalman filter. Despite the mismatch, these algorithms do perform well. Discuss what differences we might find between the true and assumed processes. What mistakes might be likely consequences of these differences?\n",
"\n",
"3. Finally, recall that the original task was to use this data to help develop models of visual salience. While our Kalman filter is able to provide smooth estimates of observed gaze data, it's not telling us anything about *why* the gaze is going in a certain direction. In fact, if we sample data from our parameters and plot them, we get what amounts to a random walk."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"kf_state, kf_data = kf.sample(len(data))\n",
"ax = plot_gaze_data(kf_data, img=images[2])\n",
"plot_kf_state(kf, kf_data, ax)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"This should not be surprising, as we have given the model no other observed data beyond the pixels at which gaze was detected. We expect there is some other aspect driving the latent state of where to look next other than just the previous fixation location.\n",
"\n",
"In summary, while the Kalman filter is a good option for smoothing the gaze trajectory itself, especially if using a lower-quality eye tracker or in noisy environmental conditions, a linear dynamical system may not be the right way to approach the much more challenging task of modeling visual saliency.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Handling Eye Blinks"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"In the MIT Eyetracking Database, raw tracking data includes times when the subject blinked. The way this is represented in the data stream is via negative pixel coordinate values.\n",
"\n",
"We could try to mitigate these samples by simply deleting them from the stream, though this introduces other issues. For instance, if each sample corresponds to a fixed time step, and you arbitrarily remove some samples, the integrity of that consistent timestep between samples is lost. It's sometimes better to flag data as missing rather than to pretend it was never there at all, especially with time series data.\n",
"\n",
"Another solution is to use masked arrays. In `numpy`, a [masked array](https://numpy.org/doc/stable/reference/maskedarray.generic.html#what-is-a-masked-array) is an `ndarray` with an additional embedded boolean masking array that indicates which elements should be masked. When computation is performed on the array, the masked elements are ignored. Both `matplotlib` and `pykalman` work with masked arrays, and, in fact, this is the approach taken with the data we explore in this notebook.\n",
"\n",
"In preparing the dataset for this notebook, the original dataset was preprocessed to set all gaze data as masked arrays, with the mask enabled for any pixel with a negative $x$ or $y$ coordinate."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Bonus"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Review on Gaussian joint, marginal and conditional distributions"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Assume\n",
"\n",
"\\begin{eqnarray}\n",
"z & = & \\begin{bmatrix}x \\\\y\\end{bmatrix}\\sim N\\left(\\begin{bmatrix}a \\\\b\\end{bmatrix}, \\begin{bmatrix}A & C \\\\C^\\mathsf{T} & B\\end{bmatrix}\\right)\n",
"\\end{eqnarray}\n",
"\n",
"then the marginal distributions are\n",
"\n",
"\\begin{eqnarray}\n",
"x & \\sim & \\mathcal{N}(a, A) \\\\\n",
"y & \\sim & \\mathcal{N}(b,B)\n",
"\\end{eqnarray}\n",
"\n",
"and the conditional distributions are\n",
"\n",
"\\begin{eqnarray}\n",
"x|y & \\sim & \\mathcal{N}(a+CB^{-1}(y-b), A-CB^{-1}C^\\mathsf{T}) \\\\\n",
"y|x & \\sim & \\mathcal{N}(b+C^\\mathsf{T} A^{-1}(x-a), B-C^\\mathsf{T} A^{-1}C)\n",
"\\end{eqnarray}\n",
"\n",
"*important take away: given the joint Gaussian distribution we can derive the conditionals*"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Kalman Smoothing"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Video 5: Kalman Smoothing and the EM Algorithm\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"#@title Video 5: Kalman Smoothing and the EM Algorithm\n",
"# Insert the ID of the corresponding youtube video\n",
"from IPython.display import YouTubeVideo\n",
"video = YouTubeVideo(id=\"4Ar2mYz1Nms\", width=730, height=410, fs=1)\n",
"print(\"Video available at https://youtu.be/\" + video.id)\n",
"video"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Kalman_Smoothing_and_the_EM_Algorithm_Bonus_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Obtain estimates by propagating from $y_T$ back to $y_0$ using results of forward pass ($\\hat{\\mu}_t^{\\rm filter}, \\hat{\\Sigma}_t^{\\rm filter}, P_t=\\hat{\\Sigma}_{t+1}^{\\rm pred}$)\n",
"\n",
"\\begin{eqnarray}\n",
"s_t & \\sim & \\mathcal{N}(\\hat{\\mu}_t^{\\rm smooth}, \\hat{\\Sigma}_t^{\\rm smooth}) \\\\\n",
"\\hat{\\mu}_t^{\\rm smooth} & = & \\hat{\\mu}_t^{\\rm filter}+J_t(\\hat{\\mu}_{t+1}^{\\rm smooth}-D\\hat{\\mu}_t^{\\rm filter}) \\\\\n",
"\\hat{\\Sigma}_t^{\\rm smooth} & = & \\hat{\\Sigma}_t^{\\rm filter}+J_t(\\hat{\\Sigma}_{t+1}^{\\rm smooth}-P_t)J_t^\\mathsf{T} \\\\\n",
"J_t & = & \\hat{\\Sigma}_t^{\\rm filter}D^\\mathsf{T} P_t^{-1}\n",
"\\end{eqnarray}\n",
"\n",
"This gives us the final estimate for $z_t$.\n",
"\n",
"\\begin{eqnarray}\n",
"\\hat{\\mu}_t & = & \\hat{\\mu}_t^{\\rm smooth} \\\\\n",
"\\hat{\\Sigma}_t & = & \\hat{\\Sigma}_t^{\\rm smooth}\n",
"\\end{eqnarray}"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Coding Exercise 3: Implement Kalman smoothing\n",
"\n",
"In this exercise you will implement the Kalman smoothing (backward) process. Again you will focus on writing the expressions for computing the smoothed mean, smoothed covariance, and $J_t$ values."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def kalman_smooth(data, params):\n",
" \"\"\" Perform Kalman smoothing (backward pass) on the data given the provided\n",
" system parameters.\n",
"\n",
" Args:\n",
" data (ndarray): a sequence of observations of shape(n_timesteps, n_dim_obs)\n",
" params (dict): a dictionary of model parameters: (D, Q, H, R, mu_0, sigma_0)\n",
"\n",
" Returns:\n",
" ndarray, ndarray: the smoothed system means and noise covariance values\n",
" \"\"\"\n",
" # pulled out of the params dict for convenience\n",
" D= params['D']\n",
" Q = params['Q']\n",
" H = params['H']\n",
" R = params['R']\n",
"\n",
" n_dim_state = D.shape[0]\n",
" n_dim_obs = H.shape[0]\n",
"\n",
" # first run the forward pass to get the filtered means and covariances\n",
" mu, sigma = kalman_filter(data, params)\n",
"\n",
" # initialize state mean and covariance estimates\n",
" mu_hat = np.zeros_like(mu)\n",
" sigma_hat = np.zeros_like(sigma)\n",
" mu_hat[-1] = mu[-1]\n",
" sigma_hat[-1] = sigma[-1]\n",
"\n",
" # smooth the data\n",
" for t in reversed(range(len(data)-1)):\n",
" sigma_pred = D@ sigma[t] @ D.T + Q # sigma_pred at t+1\n",
" ###########################################################################\n",
" ## TODO for students: compute the smoothed state mean and covariance values\n",
" # Fill out function and remove\n",
" raise NotImplementedError(\"Student exercise: compute the smoothed state mean and covariance values\")\n",
" ###########################################################################\n",
"\n",
" # write the expression to compute the Kalman gain for the backward process\n",
" J = ...\n",
" # write the expression to compute the smoothed state mean estimate\n",
" mu_hat[t] = ...\n",
" # write the expression to compute the smoothed state noise covariance estimate\n",
" sigma_hat[t] = ...\n",
"\n",
" return mu_hat, sigma_hat\n",
"\n",
"\n",
"smoothed_state_means, smoothed_state_covariances = kalman_smooth(obs, params)\n",
"axes = plot_kalman(state, obs, filtered_state_means, color=\"r\",\n",
" label=\"my kf-filter\")\n",
"plot_kalman(state, obs, smoothed_state_means, color=\"b\",\n",
" label=\"my kf-smoothed\", axes=axes)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D2_HiddenDynamics/solutions/W3D2_Tutorial4_Solution_a7cea8e4.py)\n",
"\n",
"*Example output:*\n",
"\n",
"
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Implement_Kalman_filtering_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 3: Fitting Eye Gaze Data"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 4: Fitting Eye Gaze Data\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"#@title Video 4: Fitting Eye Gaze Data\n",
"# Insert the ID of the corresponding youtube video\n",
"from IPython.display import YouTubeVideo\n",
"video = YouTubeVideo(id=\"M7OuXmVWHGI\", width=730, height=410, fs=1)\n",
"print(\"Video available at https://youtu.be/\" + video.id)\n",
"video"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Fitting_Eye_Gaze_Data_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Tracking eye gaze is used in both experimental and user interface applications. Getting an accurate estimation of where someone is looking on a screen in pixel coordinates can be challenging, however, due to the various sources of noise inherent in obtaining these measurements. A main source of noise is the general accuracy of the eye tracker device itself and how well it maintains calibration over time. Changes in ambient light or subject position can further reduce accuracy of the sensor. Eye blinks introduce a different form of noise as interruptions in the data stream which also need to be addressed.\n",
"\n",
"Fortunately we have a candidate solution for handling noisy eye gaze data in the Kalman filter we just learned about. Let's look at how we can apply these methods to a small subset of data taken from the [MIT Eyetracking Database](http://people.csail.mit.edu/tjudd/WherePeopleLook/index.html) [[Judd et al. 2009](http://people.csail.mit.edu/tjudd/WherePeopleLook/Docs/wherepeoplelook.pdf)]. This data was collected as part of an effort to model [visual saliency](http://www.scholarpedia.org/article/Visual_salience) -- given an image, can we predict where a person is most likely going to look."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# load eyetracking data\n",
"subjects, images = load_eyetracking_data()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Interactive Demo 2: Tracking Eye Gaze\n",
"\n",
"We have three stimulus images and five different subjects' gaze data. Each subject fixated in the center of the screen before the image appeared, then had a few seconds to freely look around. You can use the widget below to see how different subjects visually scanned the presented image. A subject ID of -1 will show the stimulus images without any overlaid gaze trace.\n",
"\n",
"Note that the images are rescaled below for display purposes, they were in their original aspect ratio during the task itself."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Make sure you execute this cell to enable the widget!\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Make sure you execute this cell to enable the widget!\n",
"\n",
"@widgets.interact(subject_id=widgets.IntSlider(-1, min=-1, max=4),\n",
" image_id=widgets.IntSlider(0, min=0, max=2))\n",
"def plot_subject_trace(subject_id=-1, image_id=0):\n",
" if subject_id == -1:\n",
" subject = np.zeros((3, 0, 2))\n",
" else:\n",
" subject = subjects[subject_id]\n",
" data = subject[image_id]\n",
" img = images[image_id]\n",
"\n",
" fig, ax = plt.subplots()\n",
" ax.imshow(img, aspect='auto')\n",
" ax.scatter(data[:, 0], data[:, 1], c='m', s=100, alpha=0.7)\n",
" ax.set(xlim=(0, img.shape[1]), ylim=(img.shape[0], 0))\n",
" plt.show(fig)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Tracking_Eye_Gaze_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 3.1: Fitting data with `pykalman`\n",
"\n",
"Now that we have data, we'd like to use Kalman filtering to give us a better estimate of the true gaze. Up until this point we've known the parameters of our LDS, but here we need to estimate them from data directly. We will use the `pykalman` package to handle this estimation using the EM algorithm, a useful and influential learning algorithm described briefly in the bonus material.\n",
"\n",
"Before exploring fitting models with `pykalman` it's worth pointing out some naming conventions used by the library:\n",
"\n",
"\\begin{align}\n",
"D &: \\texttt{transition_matrices} &\n",
"Q &: \\texttt{transition_covariance} \\\\\n",
"H &: \\texttt{observation_matrices} &\n",
"R &: \\texttt{observation_covariance} \\\\\n",
"\\mu_0 &: \\texttt{initial_state_mean} & \\Sigma_0 &: \\texttt{initial_state_covariance}\n",
"\\end{align}"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The first thing we need to do is provide a guess at the dimensionality of the latent state. Let's start by assuming the dynamics line-up directly with the observation data (pixel x,y-coordinates), and so we have a state dimension of 2.\n",
"\n",
"We also need to decide which parameters we want the EM algorithm to fit. In this case, we will let the EM algorithm discover the dynamics parameters i.e. the $D$, $Q$, $H$, and $R$ matrices.\n",
"\n",
"We set up our `pykalman` `KalmanFilter` object with these settings using the code below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# set up our KalmanFilter object and tell it which parameters we want to\n",
"# estimate\n",
"np.random.seed(1)\n",
"\n",
"n_dim_obs = 2\n",
"n_dim_state = 2\n",
"\n",
"kf = pykalman.KalmanFilter(\n",
" n_dim_state=n_dim_state,\n",
" n_dim_obs=n_dim_obs,\n",
" em_vars=['transition_matrices', 'transition_covariance',\n",
" 'observation_matrices', 'observation_covariance']\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Because we know from the reported experimental design that subjects fixated in the center of the screen right before the image appears, we can set the initial starting state estimate $\\mu_0$ as being the center pixel of the stimulus image (the first data point in this sample dataset) with a correspondingly low initial noise covariance $\\Sigma_0$. Once we have everything set, it's time to fit some data."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Choose a subject and stimulus image\n",
"subject_id = 1\n",
"image_id = 2\n",
"data = subjects[subject_id][image_id]\n",
"\n",
"# Provide the initial states\n",
"kf.initial_state_mean = data[0]\n",
"kf.initial_state_covariance = 0.1*np.eye(n_dim_state)\n",
"\n",
"# Estimate the parameters from data using the EM algorithm\n",
"kf.em(data)\n",
"\n",
"print(f'D=\\n{kf.transition_matrices}')\n",
"print(f'Q =\\n{kf.transition_covariance}')\n",
"print(f'H =\\n{kf.observation_matrices}')\n",
"print(f'R =\\n{kf.observation_covariance}')"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We see that the EM algorithm has found fits for the various dynamics parameters. One thing you will note is that both the state and observation matrices are close to the identity matrix, which means the x- and y-coordinate dynamics are independent of each other and primarily impacted by the noise covariances.\n",
"\n",
"We can now use this model to smooth the observed data from the subject. In addition to the source image, we can also see how this model will work with the gaze recorded by the same subject on the other images as well, or even with different subjects.\n",
"\n",
"Below are the three stimulus images overlaid with recorded gaze in magenta and smoothed state from the filter in green, with gaze begin (orange triangle) and gaze end (orange square) markers."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Make sure you execute this cell to enable the widget!\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Make sure you execute this cell to enable the widget!\n",
"\n",
"@widgets.interact(subject_id=widgets.IntSlider(1, min=0, max=4))\n",
"def plot_smoothed_traces(subject_id=0):\n",
" subject = subjects[subject_id]\n",
" fig, axes = plt.subplots(ncols=3, figsize=(18, 4))\n",
" for data, img, ax in zip(subject, images, axes):\n",
" ax = plot_gaze_data(data, img=img, ax=ax)\n",
" plot_kf_state(kf, data, ax, show=False)\n",
" plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_DaySummary\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Discussion questions\n",
"\n",
"1. Why do you think one trace from one subject was sufficient to provide a decent fit across all subjects? If you were to go back and change the subject_id and/or image_id for when we fit the data using EM, do you think the fits would be different?\n",
"\n",
"2. We don't think the eye is exactly following a linear dynamical system. Nonetheless that is what we assumed for this exercise when we applied a Kalman filter. Despite the mismatch, these algorithms do perform well. Discuss what differences we might find between the true and assumed processes. What mistakes might be likely consequences of these differences?\n",
"\n",
"3. Finally, recall that the original task was to use this data to help develop models of visual salience. While our Kalman filter is able to provide smooth estimates of observed gaze data, it's not telling us anything about *why* the gaze is going in a certain direction. In fact, if we sample data from our parameters and plot them, we get what amounts to a random walk."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"kf_state, kf_data = kf.sample(len(data))\n",
"ax = plot_gaze_data(kf_data, img=images[2])\n",
"plot_kf_state(kf, kf_data, ax)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"This should not be surprising, as we have given the model no other observed data beyond the pixels at which gaze was detected. We expect there is some other aspect driving the latent state of where to look next other than just the previous fixation location.\n",
"\n",
"In summary, while the Kalman filter is a good option for smoothing the gaze trajectory itself, especially if using a lower-quality eye tracker or in noisy environmental conditions, a linear dynamical system may not be the right way to approach the much more challenging task of modeling visual saliency.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Handling Eye Blinks"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"In the MIT Eyetracking Database, raw tracking data includes times when the subject blinked. The way this is represented in the data stream is via negative pixel coordinate values.\n",
"\n",
"We could try to mitigate these samples by simply deleting them from the stream, though this introduces other issues. For instance, if each sample corresponds to a fixed time step, and you arbitrarily remove some samples, the integrity of that consistent timestep between samples is lost. It's sometimes better to flag data as missing rather than to pretend it was never there at all, especially with time series data.\n",
"\n",
"Another solution is to use masked arrays. In `numpy`, a [masked array](https://numpy.org/doc/stable/reference/maskedarray.generic.html#what-is-a-masked-array) is an `ndarray` with an additional embedded boolean masking array that indicates which elements should be masked. When computation is performed on the array, the masked elements are ignored. Both `matplotlib` and `pykalman` work with masked arrays, and, in fact, this is the approach taken with the data we explore in this notebook.\n",
"\n",
"In preparing the dataset for this notebook, the original dataset was preprocessed to set all gaze data as masked arrays, with the mask enabled for any pixel with a negative $x$ or $y$ coordinate."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Bonus"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Review on Gaussian joint, marginal and conditional distributions"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Assume\n",
"\n",
"\\begin{eqnarray}\n",
"z & = & \\begin{bmatrix}x \\\\y\\end{bmatrix}\\sim N\\left(\\begin{bmatrix}a \\\\b\\end{bmatrix}, \\begin{bmatrix}A & C \\\\C^\\mathsf{T} & B\\end{bmatrix}\\right)\n",
"\\end{eqnarray}\n",
"\n",
"then the marginal distributions are\n",
"\n",
"\\begin{eqnarray}\n",
"x & \\sim & \\mathcal{N}(a, A) \\\\\n",
"y & \\sim & \\mathcal{N}(b,B)\n",
"\\end{eqnarray}\n",
"\n",
"and the conditional distributions are\n",
"\n",
"\\begin{eqnarray}\n",
"x|y & \\sim & \\mathcal{N}(a+CB^{-1}(y-b), A-CB^{-1}C^\\mathsf{T}) \\\\\n",
"y|x & \\sim & \\mathcal{N}(b+C^\\mathsf{T} A^{-1}(x-a), B-C^\\mathsf{T} A^{-1}C)\n",
"\\end{eqnarray}\n",
"\n",
"*important take away: given the joint Gaussian distribution we can derive the conditionals*"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Kalman Smoothing"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Video 5: Kalman Smoothing and the EM Algorithm\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"#@title Video 5: Kalman Smoothing and the EM Algorithm\n",
"# Insert the ID of the corresponding youtube video\n",
"from IPython.display import YouTubeVideo\n",
"video = YouTubeVideo(id=\"4Ar2mYz1Nms\", width=730, height=410, fs=1)\n",
"print(\"Video available at https://youtu.be/\" + video.id)\n",
"video"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Kalman_Smoothing_and_the_EM_Algorithm_Bonus_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Obtain estimates by propagating from $y_T$ back to $y_0$ using results of forward pass ($\\hat{\\mu}_t^{\\rm filter}, \\hat{\\Sigma}_t^{\\rm filter}, P_t=\\hat{\\Sigma}_{t+1}^{\\rm pred}$)\n",
"\n",
"\\begin{eqnarray}\n",
"s_t & \\sim & \\mathcal{N}(\\hat{\\mu}_t^{\\rm smooth}, \\hat{\\Sigma}_t^{\\rm smooth}) \\\\\n",
"\\hat{\\mu}_t^{\\rm smooth} & = & \\hat{\\mu}_t^{\\rm filter}+J_t(\\hat{\\mu}_{t+1}^{\\rm smooth}-D\\hat{\\mu}_t^{\\rm filter}) \\\\\n",
"\\hat{\\Sigma}_t^{\\rm smooth} & = & \\hat{\\Sigma}_t^{\\rm filter}+J_t(\\hat{\\Sigma}_{t+1}^{\\rm smooth}-P_t)J_t^\\mathsf{T} \\\\\n",
"J_t & = & \\hat{\\Sigma}_t^{\\rm filter}D^\\mathsf{T} P_t^{-1}\n",
"\\end{eqnarray}\n",
"\n",
"This gives us the final estimate for $z_t$.\n",
"\n",
"\\begin{eqnarray}\n",
"\\hat{\\mu}_t & = & \\hat{\\mu}_t^{\\rm smooth} \\\\\n",
"\\hat{\\Sigma}_t & = & \\hat{\\Sigma}_t^{\\rm smooth}\n",
"\\end{eqnarray}"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Bonus Coding Exercise 3: Implement Kalman smoothing\n",
"\n",
"In this exercise you will implement the Kalman smoothing (backward) process. Again you will focus on writing the expressions for computing the smoothed mean, smoothed covariance, and $J_t$ values."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def kalman_smooth(data, params):\n",
" \"\"\" Perform Kalman smoothing (backward pass) on the data given the provided\n",
" system parameters.\n",
"\n",
" Args:\n",
" data (ndarray): a sequence of observations of shape(n_timesteps, n_dim_obs)\n",
" params (dict): a dictionary of model parameters: (D, Q, H, R, mu_0, sigma_0)\n",
"\n",
" Returns:\n",
" ndarray, ndarray: the smoothed system means and noise covariance values\n",
" \"\"\"\n",
" # pulled out of the params dict for convenience\n",
" D= params['D']\n",
" Q = params['Q']\n",
" H = params['H']\n",
" R = params['R']\n",
"\n",
" n_dim_state = D.shape[0]\n",
" n_dim_obs = H.shape[0]\n",
"\n",
" # first run the forward pass to get the filtered means and covariances\n",
" mu, sigma = kalman_filter(data, params)\n",
"\n",
" # initialize state mean and covariance estimates\n",
" mu_hat = np.zeros_like(mu)\n",
" sigma_hat = np.zeros_like(sigma)\n",
" mu_hat[-1] = mu[-1]\n",
" sigma_hat[-1] = sigma[-1]\n",
"\n",
" # smooth the data\n",
" for t in reversed(range(len(data)-1)):\n",
" sigma_pred = D@ sigma[t] @ D.T + Q # sigma_pred at t+1\n",
" ###########################################################################\n",
" ## TODO for students: compute the smoothed state mean and covariance values\n",
" # Fill out function and remove\n",
" raise NotImplementedError(\"Student exercise: compute the smoothed state mean and covariance values\")\n",
" ###########################################################################\n",
"\n",
" # write the expression to compute the Kalman gain for the backward process\n",
" J = ...\n",
" # write the expression to compute the smoothed state mean estimate\n",
" mu_hat[t] = ...\n",
" # write the expression to compute the smoothed state noise covariance estimate\n",
" sigma_hat[t] = ...\n",
"\n",
" return mu_hat, sigma_hat\n",
"\n",
"\n",
"smoothed_state_means, smoothed_state_covariances = kalman_smooth(obs, params)\n",
"axes = plot_kalman(state, obs, filtered_state_means, color=\"r\",\n",
" label=\"my kf-filter\")\n",
"plot_kalman(state, obs, smoothed_state_means, color=\"b\",\n",
" label=\"my kf-smoothed\", axes=axes)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D2_HiddenDynamics/solutions/W3D2_Tutorial4_Solution_a7cea8e4.py)\n",
"\n",
"*Example output:*\n",
"\n",
"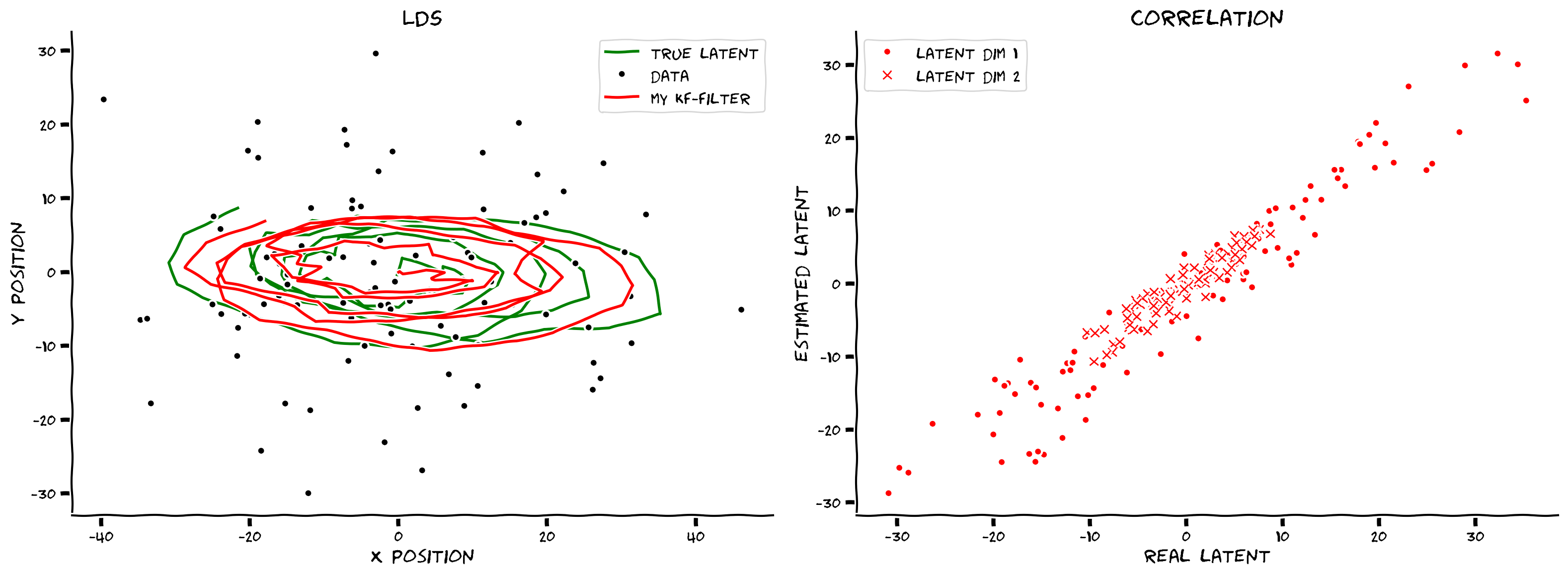 \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Implement_Kalman_smoothing_Bonus_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Forward vs Backward**\n",
"\n",
"Now that we have implementations for both, let's compare their performance by computing the MSE between the filtered (forward) and smoothed (backward) estimated states and the true latent state."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"print(f\"Filtered MSE: {np.mean((state - filtered_state_means)**2):.3f}\")\n",
"print(f\"Smoothed MSE: {np.mean((state - smoothed_state_means)**2):.3f}\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"In this example, the smoothed estimate is clearly superior to the filtered one. This makes sense as the forward pass uses only the past measurements, whereas the backward pass can use future measurement too, correcting the forward pass estimates given all the data we've collected.\n",
"\n",
"So why would you ever use Kalman filtering alone, without smoothing? As Kalman filtering only depends on already observed data (i.e. the past) it can be run in a streaming, or on-line, setting. Kalman smoothing relies on future data as it were, and as such can only be applied in a batch, or off-line, setting. So use Kalman filtering if you need real-time corrections and Kalman smoothing if you are considering already-collected data.\n",
"\n",
"This online case is typically what the brain faces."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## The Expectation-Maximization (EM) Algorithm"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"- want to maximize $\\log p(m|\\theta)$\n",
"\n",
"- need to marginalize out latent state *(which is not tractable)*\n",
"\n",
"\\begin{equation}\n",
"p(m|\\theta)=\\int p(m,s|\\theta)dz\n",
"\\end{equation}\n",
"\n",
"- add a probability distribution $q(s)$ which will approximate the latent state distribution\n",
"\n",
"$$\\log p(m|\\theta)\\int_s q(s)dz$$\n",
"\n",
"- can be rewritten as\n",
"\n",
"\\begin{equation}\n",
"\\mathcal{L}(q,\\theta)+KL\\left(q(s)||p(s|m),\\theta\\right)\n",
"\\end{equation}\n",
"\n",
"- $\\mathcal{L}(q,\\theta)$ contains the joint distribution of $m$ and $s$\n",
"\n",
"- $KL(q||p)$ contains the conditional distribution of $s|m$\n",
"\n",
"#### Expectation step\n",
"- parameters are kept fixed\n",
"- find a good approximation $q(s)$: maximize lower bound $\\mathcal{L}(q,\\theta)$ with respect to $q(s)$\n",
"- (already implemented Kalman filter+smoother)\n",
"\n",
"#### Maximization step\n",
"- keep distribution $q(s)$ fixed\n",
"- change parameters to maximize the lower bound $\\mathcal{L}(q,\\theta)$\n",
"\n",
"As mentioned, we have already effectively solved for the E-Step with our Kalman filter and smoother. The M-step requires further derivation, which is covered in the Appendix. Rather than having you implement the M-Step yourselves, let's instead turn to using a library that has already implemented EM for exploring some experimental data from cognitive neuroscience."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### The M-step for a LDS\n",
"\n",
"*(see Bishop, chapter 13.3.2 Learning in LDS)*\n",
"Update parameters of the probability distribution\n",
"\n",
"For the updates in the M-step we will need the following posterior marginals obtained from the Kalman smoothing results* $\\hat{\\mu}_t^{\\rm smooth}, \\hat{\\Sigma}_t^{\\rm smooth}$\n",
"\n",
"\\begin{eqnarray}\n",
"\\mathbb{E}[s_t] &=& \\hat{\\mu}_t \\\\\n",
"\\mathbb{E}[s_ts_{t-1}^\\mathsf{T}] &=& J_{t-1}\\hat{\\Sigma}_t+\\hat{\\mu}_t\\hat{\\mu}_{t-1}^\\mathsf{T}\\\\\n",
"\\mathbb{E}[s_ts_{t}^\\mathsf{T}] &=& \\hat{\\Sigma}_t+\\hat{\\mu}_t\\hat{\\mu}_{t}^\\mathsf{T}\n",
"\\end{eqnarray}\n",
"\n",
"
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Implement_Kalman_smoothing_Bonus_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Forward vs Backward**\n",
"\n",
"Now that we have implementations for both, let's compare their performance by computing the MSE between the filtered (forward) and smoothed (backward) estimated states and the true latent state."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"print(f\"Filtered MSE: {np.mean((state - filtered_state_means)**2):.3f}\")\n",
"print(f\"Smoothed MSE: {np.mean((state - smoothed_state_means)**2):.3f}\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"In this example, the smoothed estimate is clearly superior to the filtered one. This makes sense as the forward pass uses only the past measurements, whereas the backward pass can use future measurement too, correcting the forward pass estimates given all the data we've collected.\n",
"\n",
"So why would you ever use Kalman filtering alone, without smoothing? As Kalman filtering only depends on already observed data (i.e. the past) it can be run in a streaming, or on-line, setting. Kalman smoothing relies on future data as it were, and as such can only be applied in a batch, or off-line, setting. So use Kalman filtering if you need real-time corrections and Kalman smoothing if you are considering already-collected data.\n",
"\n",
"This online case is typically what the brain faces."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## The Expectation-Maximization (EM) Algorithm"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"- want to maximize $\\log p(m|\\theta)$\n",
"\n",
"- need to marginalize out latent state *(which is not tractable)*\n",
"\n",
"\\begin{equation}\n",
"p(m|\\theta)=\\int p(m,s|\\theta)dz\n",
"\\end{equation}\n",
"\n",
"- add a probability distribution $q(s)$ which will approximate the latent state distribution\n",
"\n",
"$$\\log p(m|\\theta)\\int_s q(s)dz$$\n",
"\n",
"- can be rewritten as\n",
"\n",
"\\begin{equation}\n",
"\\mathcal{L}(q,\\theta)+KL\\left(q(s)||p(s|m),\\theta\\right)\n",
"\\end{equation}\n",
"\n",
"- $\\mathcal{L}(q,\\theta)$ contains the joint distribution of $m$ and $s$\n",
"\n",
"- $KL(q||p)$ contains the conditional distribution of $s|m$\n",
"\n",
"#### Expectation step\n",
"- parameters are kept fixed\n",
"- find a good approximation $q(s)$: maximize lower bound $\\mathcal{L}(q,\\theta)$ with respect to $q(s)$\n",
"- (already implemented Kalman filter+smoother)\n",
"\n",
"#### Maximization step\n",
"- keep distribution $q(s)$ fixed\n",
"- change parameters to maximize the lower bound $\\mathcal{L}(q,\\theta)$\n",
"\n",
"As mentioned, we have already effectively solved for the E-Step with our Kalman filter and smoother. The M-step requires further derivation, which is covered in the Appendix. Rather than having you implement the M-Step yourselves, let's instead turn to using a library that has already implemented EM for exploring some experimental data from cognitive neuroscience."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### The M-step for a LDS\n",
"\n",
"*(see Bishop, chapter 13.3.2 Learning in LDS)*\n",
"Update parameters of the probability distribution\n",
"\n",
"For the updates in the M-step we will need the following posterior marginals obtained from the Kalman smoothing results* $\\hat{\\mu}_t^{\\rm smooth}, \\hat{\\Sigma}_t^{\\rm smooth}$\n",
"\n",
"\\begin{eqnarray}\n",
"\\mathbb{E}[s_t] &=& \\hat{\\mu}_t \\\\\n",
"\\mathbb{E}[s_ts_{t-1}^\\mathsf{T}] &=& J_{t-1}\\hat{\\Sigma}_t+\\hat{\\mu}_t\\hat{\\mu}_{t-1}^\\mathsf{T}\\\\\n",
"\\mathbb{E}[s_ts_{t}^\\mathsf{T}] &=& \\hat{\\Sigma}_t+\\hat{\\mu}_t\\hat{\\mu}_{t}^\\mathsf{T}\n",
"\\end{eqnarray}\n",
"\n",
"
\n",
"\n",
"**Update parameters**\n",
"\n",
"Initial parameters\n",
"\n",
"\\begin{eqnarray}\n",
"\\mu_0^{\\rm new}&=& \\mathbb{E}[s_0] \\\\\n",
"Q_0^{\\rm new} &=& \\mathbb{E}[s_0s_0^\\mathsf{T}]-\\mathbb{E}[s_0]\\mathbb{E}[s_0^\\mathsf{T}] \\\\\n",
"\\end{eqnarray}\n",
"\n",
"
\n",
"\n",
"Hidden (latent) state parameters\n",
"\n",
"\\begin{eqnarray}\n",
"D^{\\rm new} &=& \\left(\\sum_{t=2}^N \\mathbb{E}[s_ts_{t-1}^\\mathsf{T}]\\right)\\left(\\sum_{t=2}^N \\mathbb{E}[s_{t-1}s_{t-1}^\\mathsf{T}]\\right)^{-1} \\\\\n",
"Q^{\\rm new} &=& \\frac{1}{T-1} \\sum_{t=2}^N \\mathbb{E}\\big[s_ts_t^\\mathsf{T} \\big] - D^{\\rm new}\\mathbb{E}\\big[s_{t-1}s_{t}^\\mathsf{T} \\big] - \\mathbb{E}\\big[s_ts_{t-1}^\\mathsf{T} \\big] D^{\\rm new} + D^{\\rm new}\\mathbb{E}\\big[s_{t-1}s_{t-1}^\\mathsf{T} \\big]\\big(D^{\\rm new}\\big)^\\mathsf{T}\n",
"\\end{eqnarray}\n",
"\n",
"
\n",
"\n",
"Observable (measured) space parameters\n",
"\n",
"\\begin{eqnarray}\n",
"H^{\\rm new} &=& \\left(\\sum_{t=1}^N y_t \\mathbb{E}[s_t^T]\\right)\\left(\\sum_{t=1}^N \\mathbb{E}[s_t s_t^\\mathsf{T}]\\right)^{-1}\\\\\n",
"R^{\\rm new} &=& \\frac{1}{T}\\sum_{t=1}^Ny_ty_t^\\mathsf{T}-H^{\\rm new}\\mathbb{E}[s_t]y_t^\\mathsf{T} - y_t \\mathbb{E}[s_t^\\mathsf{T}]H^{\\rm new}+H^{\\rm new}\\mathbb{E}[s_ts_t^\\mathsf{T}]H_{\\rm new}\n",
"\\end{eqnarray}"
]
}
],
"metadata": {
"anaconda-cloud": {},
"colab": {
"collapsed_sections": [
"YzYwGWQ_9n0b",
"UAULHM66gC-K",
"zSbYugiGgC-K",
"9jc8DvOIgC-K",
"m2dENRgggC-M"
],
"include_colab_link": true,
"name": "W3D2_Tutorial4",
"provenance": [],
"toc_visible": true
},
"kernel": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.21"
},
"pycharm": {
"stem_cell": {
"cell_type": "raw",
"metadata": {
"collapsed": false
},
"source": []
}
}
},
"nbformat": 4,
"nbformat_minor": 0
}