{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {},
"id": "view-in-github"
},
"source": [
"
 "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial 1: Bayes with a binary hidden state\n",
"\n",
"**Week 3, Day 1: Bayesian Decisions**\n",
"\n",
"**By Neuromatch Academy**\n",
"\n",
"**Content creators:** Eric DeWitt, Xaq Pitkow, Ella Batty, Saeed Salehi\n",
"\n",
"**Content reviewers:** Hyosub Kim, Zahra Arjmandi, Anoop Kulkarni\n",
"\n",
"**Production editors:** Ella Batty, Gagana B, Spiros Chavlis"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial Objectives\n",
"\n",
"*Estimated timing of tutorial: 1 hour, 30 minutes*\n",
"\n",
"This is the first of two core tutorials on Bayesian statistics. In these tutorials, we will explore the fundamental concepts of the Bayesian approach. In this tutorial you will work through an example of Bayesian inference and decision making using a binary hidden state. The second tutorial extends these concepts to a continuous hidden state. In the related NMA days, each of these basic ideas will be extended. In Hidden Dynamics, we consider these ideas through time as you explore what happens when we infer a hidden state using repeated observations and when the hidden state changes across time. On the Optimal Control day, we will introduce the notion of how to use inference and decisions to select actions for optimal control.\n",
"\n",
"This notebook will introduce the fundamental building blocks for Bayesian statistics:\n",
"\n",
"1. How do we combine the possible loss (or gain) for making a decision with our probabilistic knowledge?\n",
"2. How do we use probability distributions to represent hidden states?\n",
"3. How does marginalization work and how can we use it?\n",
"4. How do we combine new information with our prior knowledge?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @markdown\n",
"from IPython.display import IFrame\n",
"from ipywidgets import widgets\n",
"out = widgets.Output()\n",
"with out:\n",
" print(f\"If you want to download the slides: https://osf.io/download/dx7jt/\")\n",
" display(IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/dx7jt/?direct%26mode=render%26action=download%26mode=render\", width=730, height=410))\n",
"display(out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Setup\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install and import feedback gadget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install and import feedback gadget\n",
"\n",
"!pip3 install vibecheck datatops --quiet\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
" return DatatopsContentReviewContainer(\n",
" \"\", # No text prompt\n",
" notebook_section,\n",
" {\n",
" \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
" \"name\": \"neuromatch_cn\",\n",
" \"user_key\": \"y1x3mpx5\",\n",
" },\n",
" ).render()\n",
"\n",
"\n",
"feedback_prefix = \"W3D1_T1\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Imports\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"from matplotlib import patches, transforms, gridspec\n",
"from scipy.optimize import fsolve\n",
"from collections import namedtuple"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Figure Settings\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Figure Settings\n",
"import logging\n",
"logging.getLogger('matplotlib.font_manager').disabled = True\n",
"\n",
"import ipywidgets as widgets # interactive display\n",
"from ipywidgets import GridspecLayout, HBox, VBox, FloatSlider, Layout, ToggleButtons\n",
"from ipywidgets import interactive, interactive_output, Checkbox, Select\n",
"from IPython.display import clear_output\n",
"%config InlineBackend.figure_format = 'retina'\n",
"plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")\n",
"\n",
"import warnings\n",
"warnings.filterwarnings(\"ignore\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Plotting Functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Plotting Functions\n",
"from matplotlib import colors\n",
"\n",
"def plot_joint_probs(P, ):\n",
" assert np.all(P >= 0), \"probabilities should be >= 0\"\n",
" # normalize if not\n",
" P = P / np.sum(P)\n",
" marginal_y = np.sum(P,axis=1)\n",
" marginal_x = np.sum(P,axis=0)\n",
"\n",
" # definitions for the axes\n",
" left, width = 0.1, 0.65\n",
" bottom, height = 0.1, 0.65\n",
" spacing = 0.005\n",
"\n",
" # start with a square Figure\n",
" fig = plt.figure(figsize=(5, 5))\n",
"\n",
" joint_prob = [left, bottom, width, height]\n",
" rect_histx = [left, bottom + height + spacing, width, 0.2]\n",
" rect_histy = [left + width + spacing, bottom, 0.2, height]\n",
"\n",
" rect_x_cmap = plt.cm.Blues\n",
" rect_y_cmap = plt.cm.Reds\n",
"\n",
" # Show joint probs and marginals\n",
" ax = fig.add_axes(joint_prob)\n",
" ax_x = fig.add_axes(rect_histx, sharex=ax)\n",
" ax_y = fig.add_axes(rect_histy, sharey=ax)\n",
"\n",
" # Show joint probs and marginals\n",
" ax.matshow(P,vmin=0., vmax=1., cmap='Greys')\n",
" ax_x.bar(0, marginal_x[0], facecolor=rect_x_cmap(marginal_x[0]))\n",
" ax_x.bar(1, marginal_x[1], facecolor=rect_x_cmap(marginal_x[1]))\n",
" ax_y.barh(0, marginal_y[0], facecolor=rect_y_cmap(marginal_y[0]))\n",
" ax_y.barh(1, marginal_y[1], facecolor=rect_y_cmap(marginal_y[1]))\n",
" # set limits\n",
" ax_x.set_ylim([0, 1])\n",
" ax_y.set_xlim([0, 1])\n",
"\n",
" # show values\n",
" ind = np.arange(2)\n",
" x,y = np.meshgrid(ind,ind)\n",
" for i,j in zip(x.flatten(), y.flatten()):\n",
" c = f\"{P[i, j]:.2f}\"\n",
" ax.text(j,i, c, va='center', ha='center', color='black')\n",
" for i in ind:\n",
" v = marginal_x[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_x.text(i, v +0.1, c, va='center', ha='center', color='black')\n",
" v = marginal_y[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_y.text(v+0.2, i, c, va='center', ha='center', color='black')\n",
"\n",
" # set up labels\n",
" ax.xaxis.tick_bottom()\n",
" ax.yaxis.tick_left()\n",
" ax.set_xticks([0,1])\n",
" ax.set_yticks([0,1])\n",
" ax.set_xticklabels(['Silver', 'Gold'])\n",
" ax.set_yticklabels(['Small', 'Large'])\n",
" ax.set_xlabel('color')\n",
" ax.set_ylabel('size')\n",
" ax_x.axis('off')\n",
" ax_y.axis('off')\n",
" return fig\n",
"\n",
"\n",
"def plot_prior_likelihood_posterior(prior, likelihood, posterior):\n",
" # definitions for the axes\n",
" left, width = 0.05, 0.3\n",
" bottom, height = 0.05, 0.9\n",
" padding = 0.12\n",
" small_width = 0.1\n",
" left_space = left + small_width + padding\n",
" added_space = padding + width\n",
"\n",
" fig = plt.figure(figsize=(12, 4))\n",
"\n",
" rect_prior = [left, bottom, small_width, height]\n",
" rect_likelihood = [left_space , bottom , width, height]\n",
" rect_posterior = [left_space + added_space, bottom , width, height]\n",
"\n",
" ax_prior = fig.add_axes(rect_prior)\n",
" ax_likelihood = fig.add_axes(rect_likelihood, sharey=ax_prior)\n",
" ax_posterior = fig.add_axes(rect_posterior, sharey = ax_prior)\n",
"\n",
" rect_colormap = plt.cm.Blues\n",
"\n",
" # Show posterior probs and marginals\n",
" ax_prior.barh(0, prior[0], facecolor=rect_colormap(prior[0, 0]))\n",
" ax_prior.barh(1, prior[1], facecolor=rect_colormap(prior[1, 0]))\n",
" ax_likelihood.matshow(likelihood, vmin=0., vmax=1., cmap='Reds')\n",
" ax_posterior.matshow(posterior, vmin=0., vmax=1., cmap='Greens')\n",
"\n",
" # Probabilities plot details\n",
" ax_prior.set(xlim=[1, 0], xticks=[], yticks=[0, 1],\n",
" yticklabels=['left', 'right'], title=\"Prior p(s)\")\n",
" ax_prior.yaxis.tick_right()\n",
" ax_prior.spines['left'].set_visible(False)\n",
" ax_prior.spines['bottom'].set_visible(False)\n",
"\n",
" # Likelihood plot details\n",
" ax_likelihood.set(xticks=[0, 1], xticklabels=['fish', 'no fish'],\n",
" yticks=[0, 1], yticklabels=['left', 'right'],\n",
" ylabel='state (s)', xlabel='measurement (m)',\n",
" title='Likelihood p(m (left) | s)')\n",
" ax_likelihood.xaxis.set_ticks_position('bottom')\n",
" ax_likelihood.spines['left'].set_visible(False)\n",
" ax_likelihood.spines['bottom'].set_visible(False)\n",
"\n",
" # Posterior plot details\n",
" ax_posterior.set(xticks=[0, 1], xticklabels=['fish', 'no fish'],\n",
" yticks=[0, 1], yticklabels=['left', 'right'],\n",
" ylabel='state (s)', xlabel='measurement (m)',\n",
" title='Posterior p(s | m)')\n",
" ax_posterior.xaxis.set_ticks_position('bottom')\n",
" ax_posterior.spines['left'].set_visible(False)\n",
" ax_posterior.spines['bottom'].set_visible(False)\n",
"\n",
" # show values\n",
" ind = np.arange(2)\n",
" x,y = np.meshgrid(ind,ind)\n",
" for i,j in zip(x.flatten(), y.flatten()):\n",
" c = f\"{posterior[i, j]:.2f}\"\n",
" ax_posterior.text(j, i, c, va='center', ha='center', color='black')\n",
" for i,j in zip(x.flatten(), y.flatten()):\n",
" c = f\"{likelihood[i, j]:.2f}\"\n",
" ax_likelihood.text(j, i, c, va='center', ha='center', color='black')\n",
" for i in ind:\n",
" v = prior[i, 0]\n",
" c = f\"{v:.2f}\"\n",
" ax_prior.text(v+0.2, i, c, va='center', ha='center', color='black')\n",
"\n",
"\n",
"def plot_prior_likelihood(ps, p_a_s1, p_a_s0, measurement):\n",
" likelihood = np.asarray([[p_a_s1, 1-p_a_s1], [p_a_s0, 1-p_a_s0]])\n",
" assert 0.0 <= ps <= 1.0\n",
" prior = np.asarray([ps, 1 - ps])\n",
" if measurement == \"Fish\":\n",
" posterior = likelihood[:, 0] * prior\n",
" else:\n",
" posterior = (likelihood[:, 1] * prior).reshape(-1)\n",
" posterior /= np.sum(posterior)\n",
"\n",
" # definitions for the axes\n",
" left, width = 0.05, 0.3\n",
" bottom, height = 0.05, 0.9\n",
" padding = 0.12\n",
" small_width = 0.2\n",
" left_space = left + small_width + padding\n",
" small_padding = 0.05\n",
"\n",
" fig = plt.figure(figsize=(12, 4))\n",
"\n",
" rect_prior = [left, bottom, small_width, height]\n",
" rect_likelihood = [left_space , bottom , width, height]\n",
" rect_posterior = [left_space + width + small_padding, bottom , small_width, height]\n",
"\n",
" ax_prior = fig.add_axes(rect_prior)\n",
" ax_likelihood = fig.add_axes(rect_likelihood, sharey=ax_prior)\n",
" ax_posterior = fig.add_axes(rect_posterior, sharey=ax_prior)\n",
"\n",
" prior_colormap = plt.cm.Blues\n",
" posterior_colormap = plt.cm.Greens\n",
"\n",
" # Show posterior probs and marginals\n",
" ax_prior.barh(0, prior[0], facecolor=prior_colormap(prior[0]))\n",
" ax_prior.barh(1, prior[1], facecolor=prior_colormap(prior[1]))\n",
" ax_likelihood.matshow(likelihood, vmin=0., vmax=1., cmap='Reds')\n",
" ax_posterior.barh(0, posterior[0], facecolor=posterior_colormap(posterior[0]))\n",
" ax_posterior.barh(1, posterior[1], facecolor=posterior_colormap(posterior[1]))\n",
"\n",
" # Probabilities plot details\n",
" ax_prior.set(xlim=[1, 0], yticks=[0, 1], yticklabels=['left', 'right'],\n",
" title=\"Prior p(s)\", xticks=[])\n",
" ax_prior.yaxis.tick_right()\n",
" ax_prior.spines['left'].set_visible(False)\n",
" ax_prior.spines['bottom'].set_visible(False)\n",
"\n",
" # Likelihood plot details\n",
" ax_likelihood.set(xticks=[0, 1], xticklabels=['fish', 'no fish'],\n",
" yticks=[0, 1], yticklabels=['left', 'right'],\n",
" ylabel='state (s)', xlabel='measurement (m)',\n",
" title='Likelihood p(m | s)')\n",
" ax_likelihood.xaxis.set_ticks_position('bottom')\n",
" ax_likelihood.spines['left'].set_visible(False)\n",
" ax_likelihood.spines['bottom'].set_visible(False)\n",
"\n",
" # Posterior plot details\n",
" ax_posterior.set(xlim=[0, 1], xticks=[], yticks=[0, 1],\n",
" yticklabels=['left', 'right'],\n",
" title=\"Posterior p(s | m)\")\n",
" ax_posterior.spines['left'].set_visible(False)\n",
" ax_posterior.spines['bottom'].set_visible(False)\n",
"\n",
" # show values\n",
" ind = np.arange(2)\n",
" x,y = np.meshgrid(ind, ind)\n",
" for i in ind:\n",
" v = posterior[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_posterior.text(v+0.2, i, c, va='center', ha='center', color='black')\n",
" for i,j in zip(x.flatten(), y.flatten()):\n",
" c = f\"{likelihood[i, j]:.2f}\"\n",
" ax_likelihood.text(j, i, c, va='center', ha='center', color='black')\n",
" for i in ind:\n",
" v = prior[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_prior.text(v+0.2, i, c, va='center', ha='center', color='black')\n",
" plt.show()\n",
" return fig\n",
"\n",
"\n",
"def plot_utility(ps):\n",
" prior = np.asarray([ps, 1 - ps])\n",
"\n",
" utility = np.array([[2, -3], [-2, 1]])\n",
"\n",
" expected = prior @ utility\n",
"\n",
" # definitions for the axes\n",
" left, width = 0.05, 0.16\n",
" bottom, height = 0.05, 0.9\n",
" padding = 0.02\n",
" small_width = 0.1\n",
" left_space = left + small_width + padding\n",
" added_space = padding + width\n",
"\n",
" fig = plt.figure(figsize=(17, 3))\n",
"\n",
" rect_prior = [left, bottom, small_width, height]\n",
" rect_utility = [left + added_space , bottom , width, height]\n",
" rect_expected = [left + 2* added_space, bottom , width, height]\n",
"\n",
" ax_prior = fig.add_axes(rect_prior)\n",
" ax_utility = fig.add_axes(rect_utility, sharey=ax_prior)\n",
" ax_expected = fig.add_axes(rect_expected)\n",
"\n",
" rect_colormap = plt.cm.Blues\n",
"\n",
" # Data of plots\n",
" ax_prior.barh(0, prior[0], facecolor=rect_colormap(prior[0]))\n",
" ax_prior.barh(1, prior[1], facecolor=rect_colormap(prior[1]))\n",
" ax_utility.matshow(utility, cmap='cool')\n",
" norm = colors.Normalize(vmin=-3, vmax=3)\n",
" ax_expected.bar(0, expected[0], facecolor=rect_colormap(norm(expected[0])))\n",
" ax_expected.bar(1, expected[1], facecolor=rect_colormap(norm(expected[1])))\n",
"\n",
" # Probabilities plot details\n",
" ax_prior.set(xlim=[1, 0], xticks=[], yticks=[0, 1],\n",
" yticklabels=['left', 'right'], title=\"Probability of state\")\n",
" ax_prior.yaxis.tick_right()\n",
" ax_prior.spines['left'].set_visible(False)\n",
" ax_prior.spines['bottom'].set_visible(False)\n",
"\n",
" # Utility plot details\n",
" ax_utility.set(xticks=[0, 1], xticklabels=['left', 'right'],\n",
" yticks=[0, 1], yticklabels=['left', 'right'],\n",
" ylabel='state (s)', xlabel='action (a)',\n",
" title='Utility')\n",
" ax_utility.xaxis.set_ticks_position('bottom')\n",
" ax_utility.spines['left'].set_visible(False)\n",
" ax_utility.spines['bottom'].set_visible(False)\n",
"\n",
" # Expected utility plot details\n",
" ax_expected.set(title='Expected utility', ylim=[-3, 3],\n",
" xticks=[0, 1], xticklabels=['left', 'right'],\n",
" xlabel='action (a)', yticks=[])\n",
" ax_expected.xaxis.set_ticks_position('bottom')\n",
" ax_expected.spines['left'].set_visible(False)\n",
" ax_expected.spines['bottom'].set_visible(False)\n",
"\n",
" # show values\n",
" ind = np.arange(2)\n",
" x,y = np.meshgrid(ind,ind)\n",
"\n",
" for i,j in zip(x.flatten(), y.flatten()):\n",
" c = f\"{utility[i, j]:.2f}\"\n",
" ax_utility.text(j, i, c, va='center', ha='center', color='black')\n",
" for i in ind:\n",
" v = prior[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_prior.text(v+0.2, i, c, va='center', ha='center', color='black')\n",
" for i in ind:\n",
" v = expected[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_expected.text(i, 2.5, c, va='center', ha='center', color='black')\n",
"\n",
" return fig\n",
"\n",
"\n",
"def plot_prior_likelihood_utility(ps, p_a_s1, p_a_s0, measurement):\n",
" assert 0.0 <= ps <= 1.0\n",
" assert 0.0 <= p_a_s1 <= 1.0\n",
" assert 0.0 <= p_a_s0 <= 1.0\n",
" prior = np.asarray([ps, 1 - ps])\n",
" likelihood = np.asarray([[p_a_s1, 1-p_a_s1],[p_a_s0, 1-p_a_s0]])\n",
" utility = np.array([[2.0, -3.0], [-2.0, 1.0]])\n",
"\n",
" if measurement == \"Fish\":\n",
" posterior = likelihood[:, 0] * prior\n",
" else:\n",
" posterior = (likelihood[:, 1] * prior).reshape(-1)\n",
" posterior /= np.sum(posterior)\n",
" expected = posterior @ utility\n",
"\n",
" # definitions for the axes\n",
" left, width = 0.05, 0.3\n",
" bottom, height = 0.05, 0.3\n",
" padding = 0.12\n",
" small_width = 0.2\n",
" left_space = left + small_width + padding\n",
" small_padding = 0.05\n",
"\n",
" fig = plt.figure(figsize=(10, 9))\n",
"\n",
" rect_prior = [left, bottom + height + padding, small_width, height]\n",
" rect_likelihood = [left_space , bottom + height + padding , width, height]\n",
" rect_posterior = [left_space + width + small_padding,\n",
" bottom + height + padding,\n",
" small_width, height]\n",
"\n",
" rect_utility = [padding, bottom, width, height]\n",
" rect_expected = [padding + width + padding + left, bottom, width, height]\n",
"\n",
" ax_likelihood = fig.add_axes(rect_likelihood)\n",
" ax_prior = fig.add_axes(rect_prior, sharey=ax_likelihood)\n",
" ax_posterior = fig.add_axes(rect_posterior, sharey=ax_likelihood)\n",
" ax_utility = fig.add_axes(rect_utility)\n",
" ax_expected = fig.add_axes(rect_expected)\n",
"\n",
" prior_colormap = plt.cm.Blues\n",
" posterior_colormap = plt.cm.Greens\n",
" expected_colormap = plt.cm.Wistia\n",
"\n",
" # Show posterior probs and marginals\n",
" ax_prior.barh(0, prior[0], facecolor=prior_colormap(prior[0]))\n",
" ax_prior.barh(1, prior[1], facecolor=prior_colormap(prior[1]))\n",
" ax_likelihood.matshow(likelihood, vmin=0., vmax=1., cmap='Reds')\n",
" ax_posterior.barh(0, posterior[0], facecolor=posterior_colormap(posterior[0]))\n",
" ax_posterior.barh(1, posterior[1], facecolor=posterior_colormap(posterior[1]))\n",
" ax_utility.matshow(utility, vmin=0., vmax=1., cmap='cool')\n",
" ax_expected.bar(0, expected[0], facecolor=expected_colormap(expected[0]))\n",
" ax_expected.bar(1, expected[1], facecolor=expected_colormap(expected[1]))\n",
"\n",
" # Probabilities plot details\n",
" ax_prior.set(xlim=[1, 0], yticks=[0, 1], yticklabels=['left', 'right'],\n",
" title=\"Prior p(s)\", xticks=[])\n",
" ax_prior.yaxis.tick_right()\n",
" ax_prior.spines['left'].set_visible(False)\n",
" ax_prior.spines['bottom'].set_visible(False)\n",
"\n",
" # Likelihood plot details\n",
" ax_likelihood.set(xticks=[0, 1], xticklabels=['fish', 'no fish'],\n",
" yticks=[0, 1], yticklabels=['left', 'right'],\n",
" ylabel='state (s)', xlabel='measurement (m)',\n",
" title='Likelihood p(m | s)')\n",
" ax_likelihood.xaxis.set_ticks_position('bottom')\n",
" ax_likelihood.spines['left'].set_visible(False)\n",
" ax_likelihood.spines['bottom'].set_visible(False)\n",
"\n",
" # Posterior plot details\n",
" ax_posterior.set(xlim=[0, 1], xticks=[], yticks=[0, 1],\n",
" yticklabels=['left', 'right'],\n",
" title=\"Posterior p(s | m)\")\n",
" ax_posterior.spines['left'].set_visible(False)\n",
" ax_posterior.spines['bottom'].set_visible(False)\n",
"\n",
" # Utility plot details\n",
" ax_utility.set(xticks=[0, 1], xticklabels=['left', 'right'],\n",
" xlabel='action (a)', yticks=[0, 1],\n",
" yticklabels=['left', 'right'],\n",
" title='Utility', ylabel='state (s)')\n",
" ax_utility.xaxis.set_ticks_position('bottom')\n",
" ax_utility.spines['left'].set_visible(False)\n",
" ax_utility.spines['bottom'].set_visible(False)\n",
"\n",
" # Expected Utility plot details\n",
" ax_expected.set(ylim=[-2, 2], xticks=[0, 1],\n",
" xticklabels=['left', 'right'],\n",
" xlabel='action (a)',\n",
" title='Expected utility', yticks=[])\n",
" ax_expected.spines['left'].set_visible(False)\n",
"\n",
" # show values\n",
" ind = np.arange(2)\n",
" x,y = np.meshgrid(ind,ind)\n",
" for i in ind:\n",
" v = posterior[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_posterior.text(v+0.2, i, c, va='center', ha='center', color='black')\n",
" for i,j in zip(x.flatten(), y.flatten()):\n",
" c = f\"{likelihood[i,j]:.2f}\"\n",
" ax_likelihood.text(j, i, c, va='center', ha='center', color='black')\n",
" for i,j in zip(x.flatten(), y.flatten()):\n",
" c = f\"{utility[i, j]:.2f}\"\n",
" ax_utility.text(j,i, c, va='center', ha='center', color='black')\n",
" for i in ind:\n",
" v = prior[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_prior.text(v+0.2, i, c, va='center', ha='center', color='black')\n",
" for i in ind:\n",
" v = expected[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_expected.text(i, v, c, va='center', ha='center', color='black')\n",
" plt.show()\n",
" return fig"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Helper Functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Helper Functions\n",
"\n",
"def compute_marginal(px, py, cor):\n",
" \"\"\" Calculate 2x2 joint probabilities given marginals p(x=1), p(y=1) and correlation\n",
"\n",
" Args:\n",
" px (scalar): marginal probability of x\n",
" py (scalar): marginal probability of y\n",
" cor (scalar): correlation value\n",
"\n",
" Returns:\n",
" ndarray of size (2, 2): joint probability array of x and y\n",
" \"\"\"\n",
"\n",
" p11 = px*py + cor*np.sqrt(px*py*(1-px)*(1-py))\n",
" p01 = px - p11\n",
" p10 = py - p11\n",
" p00 = 1.0 - p11 - p01 - p10\n",
"\n",
" return np.asarray([[p00, p01], [p10, p11]])\n",
"\n",
"\n",
"def compute_cor_range(px,py):\n",
" \"\"\" Calculate the allowed range of correlation values given marginals p(x=1)\n",
" and p(y=1)\n",
"\n",
" Args:\n",
" px (scalar): marginal probability of x\n",
" py (scalar): marginal probability of y\n",
"\n",
" Returns:\n",
" scalar, scalar: minimum and maximum possible values of correlation\n",
" \"\"\"\n",
"\n",
" def p11(corr):\n",
" return px*py + corr*np.sqrt(px*py*(1-px)*(1-py))\n",
" def p01(corr):\n",
" return px - p11(corr)\n",
" def p10(corr):\n",
" return py - p11(corr)\n",
" def p00(corr):\n",
" return 1.0 - p11(corr) - p01(corr) - p10(corr)\n",
" Cmax = min(fsolve(p01, 0.0), fsolve(p10, 0.0))\n",
" Cmin = max(fsolve(p11, 0.0), fsolve(p00, 0.0))\n",
" return Cmin, Cmax"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 0: Introduction"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 1: Introduction to Bayesian Statistics and Decisions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 1: Introduction to Bayesian Statistics and Decisions\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'Hcx2_JTpf2M'), ('Bilibili', 'BV1Ch41167jN')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Introduction_to_Bayesian_Statistics_and_Decisions_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 1: Gone Fishin'\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 2: Gone Fishin'\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 2: Gone Fishin'\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'kAdBjWOI_yE'), ('Bilibili', 'BV1TP4y147pJ')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Gone_Fishin_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"This video covers the example problem of fishing that we will cover in this tutorial.\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial 1: Bayes with a binary hidden state\n",
"\n",
"**Week 3, Day 1: Bayesian Decisions**\n",
"\n",
"**By Neuromatch Academy**\n",
"\n",
"**Content creators:** Eric DeWitt, Xaq Pitkow, Ella Batty, Saeed Salehi\n",
"\n",
"**Content reviewers:** Hyosub Kim, Zahra Arjmandi, Anoop Kulkarni\n",
"\n",
"**Production editors:** Ella Batty, Gagana B, Spiros Chavlis"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial Objectives\n",
"\n",
"*Estimated timing of tutorial: 1 hour, 30 minutes*\n",
"\n",
"This is the first of two core tutorials on Bayesian statistics. In these tutorials, we will explore the fundamental concepts of the Bayesian approach. In this tutorial you will work through an example of Bayesian inference and decision making using a binary hidden state. The second tutorial extends these concepts to a continuous hidden state. In the related NMA days, each of these basic ideas will be extended. In Hidden Dynamics, we consider these ideas through time as you explore what happens when we infer a hidden state using repeated observations and when the hidden state changes across time. On the Optimal Control day, we will introduce the notion of how to use inference and decisions to select actions for optimal control.\n",
"\n",
"This notebook will introduce the fundamental building blocks for Bayesian statistics:\n",
"\n",
"1. How do we combine the possible loss (or gain) for making a decision with our probabilistic knowledge?\n",
"2. How do we use probability distributions to represent hidden states?\n",
"3. How does marginalization work and how can we use it?\n",
"4. How do we combine new information with our prior knowledge?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @markdown\n",
"from IPython.display import IFrame\n",
"from ipywidgets import widgets\n",
"out = widgets.Output()\n",
"with out:\n",
" print(f\"If you want to download the slides: https://osf.io/download/dx7jt/\")\n",
" display(IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/dx7jt/?direct%26mode=render%26action=download%26mode=render\", width=730, height=410))\n",
"display(out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Setup\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install and import feedback gadget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install and import feedback gadget\n",
"\n",
"!pip3 install vibecheck datatops --quiet\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
" return DatatopsContentReviewContainer(\n",
" \"\", # No text prompt\n",
" notebook_section,\n",
" {\n",
" \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
" \"name\": \"neuromatch_cn\",\n",
" \"user_key\": \"y1x3mpx5\",\n",
" },\n",
" ).render()\n",
"\n",
"\n",
"feedback_prefix = \"W3D1_T1\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Imports\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"from matplotlib import patches, transforms, gridspec\n",
"from scipy.optimize import fsolve\n",
"from collections import namedtuple"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Figure Settings\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Figure Settings\n",
"import logging\n",
"logging.getLogger('matplotlib.font_manager').disabled = True\n",
"\n",
"import ipywidgets as widgets # interactive display\n",
"from ipywidgets import GridspecLayout, HBox, VBox, FloatSlider, Layout, ToggleButtons\n",
"from ipywidgets import interactive, interactive_output, Checkbox, Select\n",
"from IPython.display import clear_output\n",
"%config InlineBackend.figure_format = 'retina'\n",
"plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")\n",
"\n",
"import warnings\n",
"warnings.filterwarnings(\"ignore\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Plotting Functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Plotting Functions\n",
"from matplotlib import colors\n",
"\n",
"def plot_joint_probs(P, ):\n",
" assert np.all(P >= 0), \"probabilities should be >= 0\"\n",
" # normalize if not\n",
" P = P / np.sum(P)\n",
" marginal_y = np.sum(P,axis=1)\n",
" marginal_x = np.sum(P,axis=0)\n",
"\n",
" # definitions for the axes\n",
" left, width = 0.1, 0.65\n",
" bottom, height = 0.1, 0.65\n",
" spacing = 0.005\n",
"\n",
" # start with a square Figure\n",
" fig = plt.figure(figsize=(5, 5))\n",
"\n",
" joint_prob = [left, bottom, width, height]\n",
" rect_histx = [left, bottom + height + spacing, width, 0.2]\n",
" rect_histy = [left + width + spacing, bottom, 0.2, height]\n",
"\n",
" rect_x_cmap = plt.cm.Blues\n",
" rect_y_cmap = plt.cm.Reds\n",
"\n",
" # Show joint probs and marginals\n",
" ax = fig.add_axes(joint_prob)\n",
" ax_x = fig.add_axes(rect_histx, sharex=ax)\n",
" ax_y = fig.add_axes(rect_histy, sharey=ax)\n",
"\n",
" # Show joint probs and marginals\n",
" ax.matshow(P,vmin=0., vmax=1., cmap='Greys')\n",
" ax_x.bar(0, marginal_x[0], facecolor=rect_x_cmap(marginal_x[0]))\n",
" ax_x.bar(1, marginal_x[1], facecolor=rect_x_cmap(marginal_x[1]))\n",
" ax_y.barh(0, marginal_y[0], facecolor=rect_y_cmap(marginal_y[0]))\n",
" ax_y.barh(1, marginal_y[1], facecolor=rect_y_cmap(marginal_y[1]))\n",
" # set limits\n",
" ax_x.set_ylim([0, 1])\n",
" ax_y.set_xlim([0, 1])\n",
"\n",
" # show values\n",
" ind = np.arange(2)\n",
" x,y = np.meshgrid(ind,ind)\n",
" for i,j in zip(x.flatten(), y.flatten()):\n",
" c = f\"{P[i, j]:.2f}\"\n",
" ax.text(j,i, c, va='center', ha='center', color='black')\n",
" for i in ind:\n",
" v = marginal_x[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_x.text(i, v +0.1, c, va='center', ha='center', color='black')\n",
" v = marginal_y[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_y.text(v+0.2, i, c, va='center', ha='center', color='black')\n",
"\n",
" # set up labels\n",
" ax.xaxis.tick_bottom()\n",
" ax.yaxis.tick_left()\n",
" ax.set_xticks([0,1])\n",
" ax.set_yticks([0,1])\n",
" ax.set_xticklabels(['Silver', 'Gold'])\n",
" ax.set_yticklabels(['Small', 'Large'])\n",
" ax.set_xlabel('color')\n",
" ax.set_ylabel('size')\n",
" ax_x.axis('off')\n",
" ax_y.axis('off')\n",
" return fig\n",
"\n",
"\n",
"def plot_prior_likelihood_posterior(prior, likelihood, posterior):\n",
" # definitions for the axes\n",
" left, width = 0.05, 0.3\n",
" bottom, height = 0.05, 0.9\n",
" padding = 0.12\n",
" small_width = 0.1\n",
" left_space = left + small_width + padding\n",
" added_space = padding + width\n",
"\n",
" fig = plt.figure(figsize=(12, 4))\n",
"\n",
" rect_prior = [left, bottom, small_width, height]\n",
" rect_likelihood = [left_space , bottom , width, height]\n",
" rect_posterior = [left_space + added_space, bottom , width, height]\n",
"\n",
" ax_prior = fig.add_axes(rect_prior)\n",
" ax_likelihood = fig.add_axes(rect_likelihood, sharey=ax_prior)\n",
" ax_posterior = fig.add_axes(rect_posterior, sharey = ax_prior)\n",
"\n",
" rect_colormap = plt.cm.Blues\n",
"\n",
" # Show posterior probs and marginals\n",
" ax_prior.barh(0, prior[0], facecolor=rect_colormap(prior[0, 0]))\n",
" ax_prior.barh(1, prior[1], facecolor=rect_colormap(prior[1, 0]))\n",
" ax_likelihood.matshow(likelihood, vmin=0., vmax=1., cmap='Reds')\n",
" ax_posterior.matshow(posterior, vmin=0., vmax=1., cmap='Greens')\n",
"\n",
" # Probabilities plot details\n",
" ax_prior.set(xlim=[1, 0], xticks=[], yticks=[0, 1],\n",
" yticklabels=['left', 'right'], title=\"Prior p(s)\")\n",
" ax_prior.yaxis.tick_right()\n",
" ax_prior.spines['left'].set_visible(False)\n",
" ax_prior.spines['bottom'].set_visible(False)\n",
"\n",
" # Likelihood plot details\n",
" ax_likelihood.set(xticks=[0, 1], xticklabels=['fish', 'no fish'],\n",
" yticks=[0, 1], yticklabels=['left', 'right'],\n",
" ylabel='state (s)', xlabel='measurement (m)',\n",
" title='Likelihood p(m (left) | s)')\n",
" ax_likelihood.xaxis.set_ticks_position('bottom')\n",
" ax_likelihood.spines['left'].set_visible(False)\n",
" ax_likelihood.spines['bottom'].set_visible(False)\n",
"\n",
" # Posterior plot details\n",
" ax_posterior.set(xticks=[0, 1], xticklabels=['fish', 'no fish'],\n",
" yticks=[0, 1], yticklabels=['left', 'right'],\n",
" ylabel='state (s)', xlabel='measurement (m)',\n",
" title='Posterior p(s | m)')\n",
" ax_posterior.xaxis.set_ticks_position('bottom')\n",
" ax_posterior.spines['left'].set_visible(False)\n",
" ax_posterior.spines['bottom'].set_visible(False)\n",
"\n",
" # show values\n",
" ind = np.arange(2)\n",
" x,y = np.meshgrid(ind,ind)\n",
" for i,j in zip(x.flatten(), y.flatten()):\n",
" c = f\"{posterior[i, j]:.2f}\"\n",
" ax_posterior.text(j, i, c, va='center', ha='center', color='black')\n",
" for i,j in zip(x.flatten(), y.flatten()):\n",
" c = f\"{likelihood[i, j]:.2f}\"\n",
" ax_likelihood.text(j, i, c, va='center', ha='center', color='black')\n",
" for i in ind:\n",
" v = prior[i, 0]\n",
" c = f\"{v:.2f}\"\n",
" ax_prior.text(v+0.2, i, c, va='center', ha='center', color='black')\n",
"\n",
"\n",
"def plot_prior_likelihood(ps, p_a_s1, p_a_s0, measurement):\n",
" likelihood = np.asarray([[p_a_s1, 1-p_a_s1], [p_a_s0, 1-p_a_s0]])\n",
" assert 0.0 <= ps <= 1.0\n",
" prior = np.asarray([ps, 1 - ps])\n",
" if measurement == \"Fish\":\n",
" posterior = likelihood[:, 0] * prior\n",
" else:\n",
" posterior = (likelihood[:, 1] * prior).reshape(-1)\n",
" posterior /= np.sum(posterior)\n",
"\n",
" # definitions for the axes\n",
" left, width = 0.05, 0.3\n",
" bottom, height = 0.05, 0.9\n",
" padding = 0.12\n",
" small_width = 0.2\n",
" left_space = left + small_width + padding\n",
" small_padding = 0.05\n",
"\n",
" fig = plt.figure(figsize=(12, 4))\n",
"\n",
" rect_prior = [left, bottom, small_width, height]\n",
" rect_likelihood = [left_space , bottom , width, height]\n",
" rect_posterior = [left_space + width + small_padding, bottom , small_width, height]\n",
"\n",
" ax_prior = fig.add_axes(rect_prior)\n",
" ax_likelihood = fig.add_axes(rect_likelihood, sharey=ax_prior)\n",
" ax_posterior = fig.add_axes(rect_posterior, sharey=ax_prior)\n",
"\n",
" prior_colormap = plt.cm.Blues\n",
" posterior_colormap = plt.cm.Greens\n",
"\n",
" # Show posterior probs and marginals\n",
" ax_prior.barh(0, prior[0], facecolor=prior_colormap(prior[0]))\n",
" ax_prior.barh(1, prior[1], facecolor=prior_colormap(prior[1]))\n",
" ax_likelihood.matshow(likelihood, vmin=0., vmax=1., cmap='Reds')\n",
" ax_posterior.barh(0, posterior[0], facecolor=posterior_colormap(posterior[0]))\n",
" ax_posterior.barh(1, posterior[1], facecolor=posterior_colormap(posterior[1]))\n",
"\n",
" # Probabilities plot details\n",
" ax_prior.set(xlim=[1, 0], yticks=[0, 1], yticklabels=['left', 'right'],\n",
" title=\"Prior p(s)\", xticks=[])\n",
" ax_prior.yaxis.tick_right()\n",
" ax_prior.spines['left'].set_visible(False)\n",
" ax_prior.spines['bottom'].set_visible(False)\n",
"\n",
" # Likelihood plot details\n",
" ax_likelihood.set(xticks=[0, 1], xticklabels=['fish', 'no fish'],\n",
" yticks=[0, 1], yticklabels=['left', 'right'],\n",
" ylabel='state (s)', xlabel='measurement (m)',\n",
" title='Likelihood p(m | s)')\n",
" ax_likelihood.xaxis.set_ticks_position('bottom')\n",
" ax_likelihood.spines['left'].set_visible(False)\n",
" ax_likelihood.spines['bottom'].set_visible(False)\n",
"\n",
" # Posterior plot details\n",
" ax_posterior.set(xlim=[0, 1], xticks=[], yticks=[0, 1],\n",
" yticklabels=['left', 'right'],\n",
" title=\"Posterior p(s | m)\")\n",
" ax_posterior.spines['left'].set_visible(False)\n",
" ax_posterior.spines['bottom'].set_visible(False)\n",
"\n",
" # show values\n",
" ind = np.arange(2)\n",
" x,y = np.meshgrid(ind, ind)\n",
" for i in ind:\n",
" v = posterior[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_posterior.text(v+0.2, i, c, va='center', ha='center', color='black')\n",
" for i,j in zip(x.flatten(), y.flatten()):\n",
" c = f\"{likelihood[i, j]:.2f}\"\n",
" ax_likelihood.text(j, i, c, va='center', ha='center', color='black')\n",
" for i in ind:\n",
" v = prior[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_prior.text(v+0.2, i, c, va='center', ha='center', color='black')\n",
" plt.show()\n",
" return fig\n",
"\n",
"\n",
"def plot_utility(ps):\n",
" prior = np.asarray([ps, 1 - ps])\n",
"\n",
" utility = np.array([[2, -3], [-2, 1]])\n",
"\n",
" expected = prior @ utility\n",
"\n",
" # definitions for the axes\n",
" left, width = 0.05, 0.16\n",
" bottom, height = 0.05, 0.9\n",
" padding = 0.02\n",
" small_width = 0.1\n",
" left_space = left + small_width + padding\n",
" added_space = padding + width\n",
"\n",
" fig = plt.figure(figsize=(17, 3))\n",
"\n",
" rect_prior = [left, bottom, small_width, height]\n",
" rect_utility = [left + added_space , bottom , width, height]\n",
" rect_expected = [left + 2* added_space, bottom , width, height]\n",
"\n",
" ax_prior = fig.add_axes(rect_prior)\n",
" ax_utility = fig.add_axes(rect_utility, sharey=ax_prior)\n",
" ax_expected = fig.add_axes(rect_expected)\n",
"\n",
" rect_colormap = plt.cm.Blues\n",
"\n",
" # Data of plots\n",
" ax_prior.barh(0, prior[0], facecolor=rect_colormap(prior[0]))\n",
" ax_prior.barh(1, prior[1], facecolor=rect_colormap(prior[1]))\n",
" ax_utility.matshow(utility, cmap='cool')\n",
" norm = colors.Normalize(vmin=-3, vmax=3)\n",
" ax_expected.bar(0, expected[0], facecolor=rect_colormap(norm(expected[0])))\n",
" ax_expected.bar(1, expected[1], facecolor=rect_colormap(norm(expected[1])))\n",
"\n",
" # Probabilities plot details\n",
" ax_prior.set(xlim=[1, 0], xticks=[], yticks=[0, 1],\n",
" yticklabels=['left', 'right'], title=\"Probability of state\")\n",
" ax_prior.yaxis.tick_right()\n",
" ax_prior.spines['left'].set_visible(False)\n",
" ax_prior.spines['bottom'].set_visible(False)\n",
"\n",
" # Utility plot details\n",
" ax_utility.set(xticks=[0, 1], xticklabels=['left', 'right'],\n",
" yticks=[0, 1], yticklabels=['left', 'right'],\n",
" ylabel='state (s)', xlabel='action (a)',\n",
" title='Utility')\n",
" ax_utility.xaxis.set_ticks_position('bottom')\n",
" ax_utility.spines['left'].set_visible(False)\n",
" ax_utility.spines['bottom'].set_visible(False)\n",
"\n",
" # Expected utility plot details\n",
" ax_expected.set(title='Expected utility', ylim=[-3, 3],\n",
" xticks=[0, 1], xticklabels=['left', 'right'],\n",
" xlabel='action (a)', yticks=[])\n",
" ax_expected.xaxis.set_ticks_position('bottom')\n",
" ax_expected.spines['left'].set_visible(False)\n",
" ax_expected.spines['bottom'].set_visible(False)\n",
"\n",
" # show values\n",
" ind = np.arange(2)\n",
" x,y = np.meshgrid(ind,ind)\n",
"\n",
" for i,j in zip(x.flatten(), y.flatten()):\n",
" c = f\"{utility[i, j]:.2f}\"\n",
" ax_utility.text(j, i, c, va='center', ha='center', color='black')\n",
" for i in ind:\n",
" v = prior[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_prior.text(v+0.2, i, c, va='center', ha='center', color='black')\n",
" for i in ind:\n",
" v = expected[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_expected.text(i, 2.5, c, va='center', ha='center', color='black')\n",
"\n",
" return fig\n",
"\n",
"\n",
"def plot_prior_likelihood_utility(ps, p_a_s1, p_a_s0, measurement):\n",
" assert 0.0 <= ps <= 1.0\n",
" assert 0.0 <= p_a_s1 <= 1.0\n",
" assert 0.0 <= p_a_s0 <= 1.0\n",
" prior = np.asarray([ps, 1 - ps])\n",
" likelihood = np.asarray([[p_a_s1, 1-p_a_s1],[p_a_s0, 1-p_a_s0]])\n",
" utility = np.array([[2.0, -3.0], [-2.0, 1.0]])\n",
"\n",
" if measurement == \"Fish\":\n",
" posterior = likelihood[:, 0] * prior\n",
" else:\n",
" posterior = (likelihood[:, 1] * prior).reshape(-1)\n",
" posterior /= np.sum(posterior)\n",
" expected = posterior @ utility\n",
"\n",
" # definitions for the axes\n",
" left, width = 0.05, 0.3\n",
" bottom, height = 0.05, 0.3\n",
" padding = 0.12\n",
" small_width = 0.2\n",
" left_space = left + small_width + padding\n",
" small_padding = 0.05\n",
"\n",
" fig = plt.figure(figsize=(10, 9))\n",
"\n",
" rect_prior = [left, bottom + height + padding, small_width, height]\n",
" rect_likelihood = [left_space , bottom + height + padding , width, height]\n",
" rect_posterior = [left_space + width + small_padding,\n",
" bottom + height + padding,\n",
" small_width, height]\n",
"\n",
" rect_utility = [padding, bottom, width, height]\n",
" rect_expected = [padding + width + padding + left, bottom, width, height]\n",
"\n",
" ax_likelihood = fig.add_axes(rect_likelihood)\n",
" ax_prior = fig.add_axes(rect_prior, sharey=ax_likelihood)\n",
" ax_posterior = fig.add_axes(rect_posterior, sharey=ax_likelihood)\n",
" ax_utility = fig.add_axes(rect_utility)\n",
" ax_expected = fig.add_axes(rect_expected)\n",
"\n",
" prior_colormap = plt.cm.Blues\n",
" posterior_colormap = plt.cm.Greens\n",
" expected_colormap = plt.cm.Wistia\n",
"\n",
" # Show posterior probs and marginals\n",
" ax_prior.barh(0, prior[0], facecolor=prior_colormap(prior[0]))\n",
" ax_prior.barh(1, prior[1], facecolor=prior_colormap(prior[1]))\n",
" ax_likelihood.matshow(likelihood, vmin=0., vmax=1., cmap='Reds')\n",
" ax_posterior.barh(0, posterior[0], facecolor=posterior_colormap(posterior[0]))\n",
" ax_posterior.barh(1, posterior[1], facecolor=posterior_colormap(posterior[1]))\n",
" ax_utility.matshow(utility, vmin=0., vmax=1., cmap='cool')\n",
" ax_expected.bar(0, expected[0], facecolor=expected_colormap(expected[0]))\n",
" ax_expected.bar(1, expected[1], facecolor=expected_colormap(expected[1]))\n",
"\n",
" # Probabilities plot details\n",
" ax_prior.set(xlim=[1, 0], yticks=[0, 1], yticklabels=['left', 'right'],\n",
" title=\"Prior p(s)\", xticks=[])\n",
" ax_prior.yaxis.tick_right()\n",
" ax_prior.spines['left'].set_visible(False)\n",
" ax_prior.spines['bottom'].set_visible(False)\n",
"\n",
" # Likelihood plot details\n",
" ax_likelihood.set(xticks=[0, 1], xticklabels=['fish', 'no fish'],\n",
" yticks=[0, 1], yticklabels=['left', 'right'],\n",
" ylabel='state (s)', xlabel='measurement (m)',\n",
" title='Likelihood p(m | s)')\n",
" ax_likelihood.xaxis.set_ticks_position('bottom')\n",
" ax_likelihood.spines['left'].set_visible(False)\n",
" ax_likelihood.spines['bottom'].set_visible(False)\n",
"\n",
" # Posterior plot details\n",
" ax_posterior.set(xlim=[0, 1], xticks=[], yticks=[0, 1],\n",
" yticklabels=['left', 'right'],\n",
" title=\"Posterior p(s | m)\")\n",
" ax_posterior.spines['left'].set_visible(False)\n",
" ax_posterior.spines['bottom'].set_visible(False)\n",
"\n",
" # Utility plot details\n",
" ax_utility.set(xticks=[0, 1], xticklabels=['left', 'right'],\n",
" xlabel='action (a)', yticks=[0, 1],\n",
" yticklabels=['left', 'right'],\n",
" title='Utility', ylabel='state (s)')\n",
" ax_utility.xaxis.set_ticks_position('bottom')\n",
" ax_utility.spines['left'].set_visible(False)\n",
" ax_utility.spines['bottom'].set_visible(False)\n",
"\n",
" # Expected Utility plot details\n",
" ax_expected.set(ylim=[-2, 2], xticks=[0, 1],\n",
" xticklabels=['left', 'right'],\n",
" xlabel='action (a)',\n",
" title='Expected utility', yticks=[])\n",
" ax_expected.spines['left'].set_visible(False)\n",
"\n",
" # show values\n",
" ind = np.arange(2)\n",
" x,y = np.meshgrid(ind,ind)\n",
" for i in ind:\n",
" v = posterior[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_posterior.text(v+0.2, i, c, va='center', ha='center', color='black')\n",
" for i,j in zip(x.flatten(), y.flatten()):\n",
" c = f\"{likelihood[i,j]:.2f}\"\n",
" ax_likelihood.text(j, i, c, va='center', ha='center', color='black')\n",
" for i,j in zip(x.flatten(), y.flatten()):\n",
" c = f\"{utility[i, j]:.2f}\"\n",
" ax_utility.text(j,i, c, va='center', ha='center', color='black')\n",
" for i in ind:\n",
" v = prior[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_prior.text(v+0.2, i, c, va='center', ha='center', color='black')\n",
" for i in ind:\n",
" v = expected[i]\n",
" c = f\"{v:.2f}\"\n",
" ax_expected.text(i, v, c, va='center', ha='center', color='black')\n",
" plt.show()\n",
" return fig"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Helper Functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Helper Functions\n",
"\n",
"def compute_marginal(px, py, cor):\n",
" \"\"\" Calculate 2x2 joint probabilities given marginals p(x=1), p(y=1) and correlation\n",
"\n",
" Args:\n",
" px (scalar): marginal probability of x\n",
" py (scalar): marginal probability of y\n",
" cor (scalar): correlation value\n",
"\n",
" Returns:\n",
" ndarray of size (2, 2): joint probability array of x and y\n",
" \"\"\"\n",
"\n",
" p11 = px*py + cor*np.sqrt(px*py*(1-px)*(1-py))\n",
" p01 = px - p11\n",
" p10 = py - p11\n",
" p00 = 1.0 - p11 - p01 - p10\n",
"\n",
" return np.asarray([[p00, p01], [p10, p11]])\n",
"\n",
"\n",
"def compute_cor_range(px,py):\n",
" \"\"\" Calculate the allowed range of correlation values given marginals p(x=1)\n",
" and p(y=1)\n",
"\n",
" Args:\n",
" px (scalar): marginal probability of x\n",
" py (scalar): marginal probability of y\n",
"\n",
" Returns:\n",
" scalar, scalar: minimum and maximum possible values of correlation\n",
" \"\"\"\n",
"\n",
" def p11(corr):\n",
" return px*py + corr*np.sqrt(px*py*(1-px)*(1-py))\n",
" def p01(corr):\n",
" return px - p11(corr)\n",
" def p10(corr):\n",
" return py - p11(corr)\n",
" def p00(corr):\n",
" return 1.0 - p11(corr) - p01(corr) - p10(corr)\n",
" Cmax = min(fsolve(p01, 0.0), fsolve(p10, 0.0))\n",
" Cmin = max(fsolve(p11, 0.0), fsolve(p00, 0.0))\n",
" return Cmin, Cmax"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 0: Introduction"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 1: Introduction to Bayesian Statistics and Decisions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 1: Introduction to Bayesian Statistics and Decisions\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'Hcx2_JTpf2M'), ('Bilibili', 'BV1Ch41167jN')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Introduction_to_Bayesian_Statistics_and_Decisions_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 1: Gone Fishin'\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 2: Gone Fishin'\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 2: Gone Fishin'\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'kAdBjWOI_yE'), ('Bilibili', 'BV1TP4y147pJ')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Gone_Fishin_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"This video covers the example problem of fishing that we will cover in this tutorial.\n",
"\n",
"\n",
" Click here for text recap of video
\n",
"\n",
"You were just introduced to the **binary hidden state problem** we are going to explore. You need to decide which side to fish on--the hidden state. We know fish like to school together. On different days the school of fish is either on the left or right side, but we don’t know what the case is today. We define our knowledge about the fish location as a distribution over the random hidden state variable. Using our probabilistic knowledge, also called our **belief** about the hidden state, we will explore how to make the decision about where to fish today, based on what to expect in terms of gains or losses for the decision.\n",
"The gains and losss are defined by the utility of choosing an action, which is fishing on the left or right. The details of the utilities are described\n",
" \n",
"\n",
"In the next two sections we will consider just the probability of where the fish might be and what you gain or lose by choosing where to fish (leaving Bayesian approaches to the last few sections).\n",
"\n",
"Remember, you can either think of yourself as a scientist conducting an experiment or as a brain trying to make a decision. The Bayesian approach is the same!\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 2: Deciding where to fish\n",
"\n",
"*Estimated timing to here from start of tutorial: 10 min*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 3: Utility\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 3: Utility\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', '8-5RM0k3IKE'), ('Bilibili', 'BV1uL411H7ZE')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Utility_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"This video covers utility and expected utility.\n",
"\n",
"\n",
" Click here for text recap of video
\n",
"\n",
"You need to decide where to fish. It may seem obvious - you could just fish on the side where the probability of the fish being is higher! Unfortunately, decisions and actions are always a little more complicated. Deciding to fish may be influenced by more than just the probability of the school of fish being there as we saw by the potential issues of submarines and sunburn. The consequences of the action you take is based on the true (but hidden) state of the world and the action you choose! In our example, fishing on the wrong side, where there aren't many fish, is likely to lead to you spending your afternoon not catching fish and therefore getting a sunburn. The submarine represents a risk to fishing on the right side that is greater than the left side. If you want to know what to expect from taking the action of fishing on one side or the other, you need to calculate the expected utility.\n",
"\n",
"You know the (prior) probability that the school of fish is on the left side of the dock today, $P(s = \\textrm{left})$. So, you also know the probability the school is on the right, $P(s = \\textrm{right})$, because these two probabilities must add up to 1.\n",
"\n",
"We quantify gains and losses numerically using a **utility** function $U(s,a)$, which describes the consequences of your actions: how much value you gain (or if negative, lose) given the state of the world ($s$) and the action you take ($a$). In our example, our utility can be summarized as:\n",
"\n",
"| Utility: U(s,a) | a = left | a = right |\n",
"| ----------------- |------------|------------|\n",
"| s = Left | +2 | -3 |\n",
"| s = right | -2 | +1 |\n",
"\n",
"To use possible gains and losses to choose an action, we calculate the **expected utility** of that action by weighing these utilities with the probability of that state occurring. This allows us to choose actions by taking probabilities of events into account: we don't care if the outcome of an action-state pair is a loss if the probability of that state is very low. We can formalize this as:\n",
"\n",
"\\begin{equation}\n",
"\\text{Expected utility of action a} = \\sum_{s}U(s,a)P(s)\n",
"\\end{equation}\n",
"\n",
"In other words, the expected utility of an action a is the sum over possible states of the utility of that action and state times the probability of that state.\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Interactive Demo 2: Exploring the decision\n",
"\n",
"Let's start to get a sense of how all this works using the interactive demo below. You can change the probability that the school of fish is on the left side,$p(s = \\textrm{left})$, using the slider. You will see the utility function (a matrix) in the middle and the corresponding expected utility for each action on the right.\n",
"\n",
"First, make sure you understand how the expected utility of each action is being computed from the probabilities and the utility values. In the initial state: the probability of the fish being on the left is 0.9 and on the right is 0.1. The expected utility of the action of fishing on the left is then $U(s = \\textrm{left},a = \\textrm{left})p(s = \\textrm{left}) + U(s = \\textrm{right},a = \\textrm{left})p(s = \\textrm{right}) = 2(0.9) + -2(0.1) = 1.6$. Essentially, to get the expected utility of action $a$, you are doing a weighted sum over the relevant column of the utility matrix (corresponding to action $a$) where the weights are the state probabilities.\n",
"\n",
"For each of these scenarios, think and discuss first. Then use the demo to try out each and see if your action would have been correct (that is, if the expected value of that action is the highest).\n",
"\n",
"\n",
"1. You just arrived at the dock for the first time and have no sense of where the fish might be. So you guess that the probability of the school being on the left side is 0.5 (so the probability on the right side is also 0.5). Which side would you choose to fish on given our utility values?\n",
"2. You think that the probability of the school being on the left side is very low (0.1) and correspondingly high on the right side (0.9). Which side would you choose to fish on given our utility values?\n",
"3. What would you choose if the probability of the school being on the left side is slightly lower than on the right side (0. 4 vs 0.6)?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute this cell to use the widget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute this cell to use the widget\n",
"ps_widget = widgets.FloatSlider(0.9, description='p(s = left)',\n",
" min=0.0, max=1.0, step=0.01)\n",
"\n",
"@widgets.interact(\n",
" ps = ps_widget,\n",
")\n",
"def make_utility_plot(ps):\n",
" fig = plot_utility(ps)\n",
" plt.show(fig)\n",
" plt.close(fig)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D1_BayesianDecisions/solutions/W3D1_Tutorial1_Solution_01d5c2c5.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Exploring_the_decision_Interactive_Demo_and_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Video 4: Utility Demo Discussion\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 4: Utility Demo Discussion\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'GHQbmsEyQjE'), ('Bilibili', 'BV1po4y1D7Fu')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Utility_demo_discussion_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"In this section, you have seen that both the utility of various state and action pairs and our knowledge of the probability of each state affects your decision. Importantly, we want our knowledge of the probability of each state to be as accurate as possible!\n",
"\n",
"So how do we know these probabilities? We may have prior knowledge from years of fishing at the same dock, learning that the fish are more likely to be on the left side, for example. Of course, we need to update our knowledge (our belief)! To do this, we need to collect more information, or take some measurements! In the next few sections, we will focus on how we improve our knowledge of the probabilities."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 3: Likelihood of the fish being on either side\n",
"\n",
"*Estimated timing to here from start of tutorial: 25 min*\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 5: Likelihood\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 5: Likelihood\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'Yv8MDjdm1l4'), ('Bilibili', 'BV1EK4y1u7AV')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
"\n",
" Click here for text recap of video
\n",
"\n",
"First, we'll think about what it means to take a measurement (also often called an observation or just data) and what it tells you about what the hidden state may be. Specifically, we'll be looking at the **likelihood**, which is the probability of your measurement ($m$) given the hidden state ($s$): $P(m | s)$. Remember that in this case, the hidden state is which side of the dock the school of fish is on.\n",
"We will watch someone fish (for let's say 10 minutes) and our measurement is whether they catch a fish or not. We know something about what catching a fish means for the likelihood of the fish being on one side or the other.\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Likelihood_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Think! 3: Guessing the location of the fish\n",
"\n",
"Let's say we go to a different dock to fish. Here, there are different probabilities of catching fish given the state of the world. At this dock, if you fish on the side of the dock where the fish are, you have a 70% chance of catching a fish. If you fish on the wrong side, you will catch a fish with only 20% probability. These are the likelihoods of observing someone catching a fish! That is, you are taking a measurement by seeing if someone else catches a fish!\n",
"\n",
"You see a fisher-person is fishing on the left side.\n",
"\n",
"1) Please figure out each of the following (might be easiest to do this separately and then compare notes):\n",
"- probability of catching a fish given that the school of fish is on the left side, $P(m = \\textrm{catch fish} | s = \\textrm{left} )$\n",
"- probability of not catching a fish given that the school of fish is on the left side, $P(m = \\textrm{no fish} | s = \\textrm{left})$\n",
"- probability of catching a fish given that the school of fish is on the right side, $P(m = \\textrm{catch fish} | s = \\textrm{right})$\n",
"- probability of not catching a fish given that the school of fish is on the right side, $P(m = \\textrm{no fish} | s = \\textrm{right})$\n",
"\n",
"2) If the fisher-person catches a fish, which side would you guess the school is on? Why?\n",
"\n",
"3) If the fisher-person does not catch a fish, which side would you guess the school is on? Why?\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D1_BayesianDecisions/solutions/W3D1_Tutorial1_Solution_fdd90301.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Guessing_the_location_of_the_fish_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"In the prior exercise, you tried to guess where the school of fish was based on the measurement you took (watching someone fish). You did this by choosing the state (side where you think the fish are) that maximized the probability of the measurement. In other words, you estimated the state by maximizing the likelihood (the side with the highest probability of measurement given state $P(m|s$)). This is called maximum likelihood estimation (MLE) and you've encountered it before during this course, in the [pre-reqs statistics day](https://compneuro.neuromatch.io/tutorials/W0D5_Statistics/student/W0D5_Tutorial2.html#section-2-2-maximum-likelihood) and on [Model Fitting day](https://compneuro.neuromatch.io/tutorials/W1D3_ModelFitting/student/W1D3_Tutorial2.html)!\n",
"\n",
"But, what if you had been going to this dock for years and you knew that the fish were almost always on the left side? This should probably affect how you make your estimate -- you would rely less on the single new measurement and more on your prior knowledge. This is the fundamental idea behind Bayesian inference, as we will see later in this tutorial!"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 4: Correlation and marginalization\n",
"\n",
"*Estimated timing to here from start of tutorial: 35 min*\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 6: Correlation and marginalization\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 6: Correlation and marginalization\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'iprFMHch2_g'), ('Bilibili', 'BV1Zq4y1p7N6')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Correlation_and_marginalization_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 4.1: Correlation"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"In this section, we are going to take a step back for a bit and think more generally about the amount of information shared between two random variables. We want to know how much information you gain when you observe one variable (take a measurement) if you know something about another. We will see that the fundamental concept is the same if we think about two attributes, for example the size and color of the fish, or the prior information and the likelihood.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! 4.1: Covarying probability distributions\n",
"\n",
"The relationship between the marginal probabilities and the joint probabilities is determined by the correlation between the two random variables - a normalized measure of how much the variables covary. We can also think of this as gaining some information about one of the variables when we observe a measurement from the other. We will think about this more formally in Tutorial 2.\n",
"\n",
"Here, we want to think about how the correlation between size and color of these fish changes how much information we gain about one attribute based on the other. See Bonus Section 1 for the formula for correlation.\n",
"\n",
"Use the widget below and answer the following questions:\n",
"\n",
"1. When the correlation is zero, $\\rho = 0$, what does the distribution of size tell you about color?\n",
"2. Set $\\rho$ to something small. As you change the probability of golden fish, what happens to the ratio of size probabilities? Set $\\rho$ larger (can be negative). Can you explain the pattern of changes in the probabilities of size as you change the probability of golden fish?\n",
"3. Set the probability of golden fish and of large fish to around 65%. As the correlation goes towards 1, how often will you see silver large fish?\n",
"4. What is increasing the (absolute) correlation telling you about how likely you are to see one of the properties if you see a fish with the other?\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute this cell to enable the widget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute this cell to enable the widget\n",
"style = {'description_width': 'initial'}\n",
"gs = GridspecLayout(2,2)\n",
"\n",
"cor_widget = widgets.FloatSlider(0.0, description='ρ',\n",
" min=-1, max=1, step=0.01)\n",
"px_widget = widgets.FloatSlider(0.5, description='p(color=golden)',\n",
" min=0.01, max=0.99, step=0.01,\n",
" style=style)\n",
"py_widget = widgets.FloatSlider(0.5, description='p(size=large)',\n",
" min=0.01, max=0.99, step=0.01,\n",
" style=style)\n",
"gs[0, 0] = cor_widget\n",
"gs[0, 1] = px_widget\n",
"gs[1, 0] = py_widget\n",
"\n",
"\n",
"@widgets.interact(\n",
" px=px_widget,\n",
" py=py_widget,\n",
" cor=cor_widget,\n",
")\n",
"\n",
"\n",
"def make_corr_plot(px, py, cor):\n",
" Cmin, Cmax = compute_cor_range(px, py) # allow correlation values\n",
" cor_widget.min, cor_widget.max = Cmin+0.01, Cmax-0.01\n",
" if cor_widget.value > Cmax:\n",
" cor_widget.value = Cmax\n",
" if cor_widget.value < Cmin:\n",
" cor_widget.value = Cmin\n",
" cor = cor_widget.value\n",
" P = compute_marginal(px,py,cor)\n",
" fig = plot_joint_probs(P)\n",
" plt.show(fig)\n",
" plt.close(fig)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D1_BayesianDecisions/solutions/W3D1_Tutorial1_Solution_eb6596af.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Covarying_probability_distributions_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We have just seen how two random variables can be more or less independent. The more correlated, the less independent, and the more shared information. We also learned that we can marginalize to determine the marginal likelihood of a measurement or to find the marginal probability distribution of two random variables. We are going to now complete our journey towards being fully Bayesian!"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 4.2: Marginalization"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
"\n",
" Click here for text recap of relevant part of video
\n",
"\n",
"We may want to find the probability of one variable while ignoring another: we will do this by averaging out, or marginalizing, the irrelevant variable.\n",
"\n",
"We will think of this in two different ways.\n",
"\n",
"In the first math exercise, you will think about the case where you know the joint probabilities of two variables and want to figure out the probability of just one variable. To make this explicit, let's assume that a fish has a color that is either gold or silver (our first variable) and a size that is either small or large (our second). We could write out the the **joint probabilities**: the probability of both specific attributes occurring together. For example, the probability of a fish being small and silver, $P(X = \\textrm{small}, Y = \\textrm{silver})$, is 0.4. The following table summarizes our joint probabilities:\n",
"\n",
"| P(X, Y) | Y = silver | Y = gold |\n",
"| -------------- |-------------|-----------|\n",
"| X = small | 0.4 | 0.2 |\n",
"| X = large | 0.1 | 0.3 |\n",
"\n",
"\n",
"We want to know what the probability of a fish being small regardless of color. Since the fish are either silver or gold, this would be the probability of a fish being small and silver plus the probability of a fish being small and gold. This is an example of marginalizing, or averaging out, the variable we are not interested in across the rows or columns.. In math speak: $P(X = \\textrm{small}) = \\sum_y{P(X = \\textrm{small}, Y)}$. This gives us a **marginal probability**, a probability of a variable outcome (in this case size), regardless of the other variables (in this case color).\n",
"\n",
"More generally, we can marginalize out a second irrelevant variable $y$ by summing over the relevant joint probabilities:\n",
"\n",
"\\begin{equation}\n",
"p(x) = \\sum_y p(x, y)\n",
"\\end{equation}\n",
"\n",
"In the second math exercise, you will remove an unknown (the hidden state) to find the marginal probability of a measurement. You will do this by marginalizing out the hidden state. In this case, you know the conditional probabilities of the measurement given state and the probabilities of each state. You can marginalize using:\n",
"\n",
"\\begin{equation}\n",
"p(m) = \\sum_s p(m | s) p(s)\n",
"\\end{equation}\n",
"\n",
"These two ways of thinking about marginalization (as averaging over joint probabilities or conditioning on some variable) are equivalent because the joint probability of two variables equals the conditional probability of the first given the second times the marginal probability of the second:\n",
"\n",
"\\begin{equation}\n",
"p(x, y) = p(x|y)p(y)\n",
"\\end{equation}\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Math Exercise 4.2.1: Computing marginal probabilities\n",
"\n",
"To understand the information between two variables, let's first consider the joint probabilities over the size and color of the fish.\n",
"\n",
"| P(X, Y) | Y = silver | Y = gold |\n",
"| -------------- |-------------|-----------|\n",
"| X = small | 0.4 | 0.2 |\n",
"| X = large | 0.1 | 0.3 |\n",
"\n",
"Please complete the following math problems to further practice thinking through probabilities:\n",
"\n",
"1. Calculate the probability of a fish being silver.\n",
"2. Calculate the probability of a fish being small, large, silver, or gold.\n",
"3. Calculate the probability of a fish being small OR gold. **Hint:** $P(A\\ \\textrm{or}\\ B) = P(A) + P(B) - P(A\\ \\textrm{and}\\ B)$.\n",
"\n",
"**We don't typically have math exercises in NMA but feel it is important for you to really compute this out yourself. Feel free to use the next cell to write out the math if helpful, or use paper and pen. We recommend doing this exercise individually first and then comparing notes and discussing.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"\"\"\"\n",
"Joint probabilities\n",
"\n",
"P( X = small, Y = silver) = 0.4\n",
"P( X = large, Y = silver) = 0.1\n",
"P( X = small, Y = gold) = 0.2\n",
"P( X = large, Y = gold) = 0.3\n",
"\n",
"\n",
"1. P(Y = silver) = ...\n",
"\n",
"2. P(X = small or large, Y = silver or gold) = ...\n",
"\n",
"3. P( X = small or Y = gold) = ...\n",
"\n",
"\"\"\""
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D1_BayesianDecisions/solutions/W3D1_Tutorial1_Solution_b60a0fd3.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Computing_marginal_probabilities_Math_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Math Exercise 4.2.2: Computing marginal likelihood\n",
"\n",
"When we normalize to find the posterior, we need to determine the marginal likelihood--or evidence--for the measurement we observed. To do this, we need to marginalize as we just did above to find the probabilities of a color or size. Only, in this case, we are marginalizing to remove a conditioning variable! In this case, let's consider the likelihood of fish (if we observed a fisher-person fishing on the **right**).\n",
"\n",
"| p(m\\|s) | m = fish | m = no fish |\n",
"| ------------ | ---------- | -------------- |\n",
"| s = left | 0.1 | 0.9 |\n",
"| s = right | 0.5 | 0.5 |\n",
"\n",
"\n",
"The table above shows us the **likelihoods**, just as we explored earlier.\n",
"\n",
"You want to know the total probability of a fish being caught, $P(m = \\textrm{fish})$, by the fisher-person fishing on the right. (You would need this to calculate the posterior.) To do this, you will need to consider the prior probability, $p(s)$, and marginalize over the hidden states!\n",
"\n",
"This is an example of marginalizing, or conditioning away, the variable we are not interested in as well.\n",
"\n",
"Please complete the following math problems to further practice thinking through probabilities:\n",
"\n",
"1. Calculate the marginal likelihood of the fish being caught, $P(m = \\textrm{fish})$, if the priors are: $p(s = \\textrm{left}) = 0.3$ and $p(s = \\textrm{right}) = 0.7$.\n",
"2. Calculate the marginal likelihood of the fish being caught, $P(m = \\textrm{fish})$, if the priors are: $p(s = \\textrm{left}) = 0.6$ and $p(s = \\textrm{right}) = 0.4$.\n",
"\n",
"**We don't typically have math exercises in NMA but feel it is important for you to really compute this out yourself. Feel free to use the next cell to write out the math if helpful, or use paper and pen. We recommend doing this exercise individually first and then comparing notes and discussing.**\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"\"\"\"\n",
"\n",
"Priors\n",
"P(s = left) = 0.3\n",
"P(s = right) = 0.7\n",
"\n",
"Likelihoods\n",
"P(m = fish | s = left) = 0.1\n",
"P(m = fish | s = right) = 0.5\n",
"P(m = no fish | s = left) = 0.9\n",
"P(m = no fish | s = right) = 0.5\n",
"\n",
"1. P(m = fish) = ...\n",
"\n",
"2. P(m = fish) = ...\n",
"\n",
"\"\"\""
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D1_BayesianDecisions/solutions/W3D1_Tutorial1_Solution_63e04b30.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Computing_marginal_likelihood_Math_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 5: Bayes' Rule and the Posterior\n",
"\n",
"*Estimated timing to here from start of tutorial: 55 min*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 7: Posterior Beliefs\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 7: Posterior Beliefs\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'cOAJQ4utwD0'), ('Bilibili', 'BV1fK4y1M7EC')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Posterior_Beliefs_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Marginalization is going to be used to combine our prior knowledge, which we call the **prior**, and our new information from a measurement, the **likelihood**. Only in this case, the information we gain about the hidden state we are interested in, where the fish are, is based on the relationship between the probabilities of the measurement and our prior.\n",
"\n",
"We can now calculate the full posterior distribution for the hidden state ($s$) using Bayes' Rule. As we've seen, the posterior is proportional to the prior times the likelihood. This means that the posterior probability of the hidden state ($s$) given a measurement ($m$) is proportional to the likelihood of the measurement given the state times the prior probability of that state:\n",
"\n",
"\\begin{equation}\n",
"P(s | m) \\propto P(m | s) P(s)\n",
"\\end{equation}\n",
"\n",
"We say proportional to instead of equal because we need to normalize to produce a full probability distribution:\n",
"\n",
"\\begin{equation}\n",
"P(s | m) = \\frac{P(m | s) P(s)}{P(m)}\n",
"\\end{equation}\n",
"\n",
"Normalizing by this $P(m)$ means that our posterior is a complete probability distribution that sums or integrates to 1 appropriately. We now can use this new, complete probability distribution for any future inference or decisions we like! In fact, as we will see tomorrow, we can use it as a new prior! Finally, we often call this probability distribution our beliefs over the hidden states, to emphasize that it is our subjective knowledge about the hidden state.\n",
"\n",
"For many complicated cases, like those we might be using to model behavioral or brain inferences, the normalization term can be intractable or extremely complex to calculate. We can be careful to choose probability distributions whfere we can analytically calculate the posterior probability or numerical approximation is reliable. Better yet, we sometimes don't need to bother with this normalization! The normalization term, $P(m)$, is the probability of the measurement. This does not depend on state so is essentially a constant we can often ignore. We can compare the unnormalized posterior distribution values for different states because how they relate to each other is unchanged when divided by the same constant. We will see how to do this to compare evidence for different hypotheses tomorrow. (It's also used to compare the likelihood of models fit using maximum likelihood estimation)\n",
"\n",
"In this relatively simple example, we can compute the marginal likelihood $P(m)$ easily by using:\n",
"\n",
"\\begin{equation}\n",
"P(m) = \\sum_s P(m | s) P(s)\n",
"\\end{equation}\n",
"\n",
"We can then normalize so that we deal with the full posterior distribution."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Math Exercise 5: Calculating a posterior probability\n",
"\n",
"Our prior is $p(s = \\textrm{left}) = 0.3$ and $p(s = \\textrm{right}) = 0.7$. In the video, we learned that the chance of catching a fish given they fish on the same side as the school was 50%. Otherwise, it was 10%. We observe a person fishing on the left side. Our likelihood is:\n",
"\n",
"\n",
"| Likelihood: p(m \\| s) | m = fish | m = no fish |\n",
"| ----------------- |----------|----------|\n",
"| s = left | 0.5 | 0.5 |\n",
"| s = right | 0.1 | 0.9 |\n",
"\n",
"\n",
"Calculate the posterior probability (on paper) that:\n",
"\n",
"1. The school is on the left if the fisher-person catches a fish: $p(s = \\textrm{left} | m = \\textrm{fish})$ (hint: normalize by computing $p(m = \\textrm{fish})$)\n",
"2. The school is on the right if the fisher-person does not catch a fish: $p(s = \\textrm{right} | m = \\textrm{no fish})$\n",
"\n",
"
\n",
"\n",
"**We don't typically have math exercises in NMA but feel it is important for you to really compute this out yourself. Feel free to use the next cell to write out the math if helpful, or use paper and pen. We recommend doing this exercise individually first and then comparing notes and discussing.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"\"\"\"\n",
"Priors\n",
"p(s = left) = 0.3\n",
"p(s = right) = 0.7\n",
"\n",
"Likelihoods\n",
"P(m = fish | s = left) = 0.5\n",
"P(m = fish | s = right) = 0.1\n",
"P(m = no fish | s = left) = 0.5\n",
"P(m = no fish | s = right) = 0.9\n",
"\n",
"1. p( s = left | m = fish) = ...\n",
"\n",
"2. p( s = right | m = no fish ) = ...\n",
"\n",
"\"\"\""
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D1_BayesianDecisions/solutions/W3D1_Tutorial1_Solution_ef5710ed.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Calculating_a_posterior_probability_Math_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Coding Exercise 5: Computing Posteriors\n",
"\n",
"Let's implement our above math to be able to compute posteriors for different priors and likelihoods.\n",
"\n",
"As before, our prior is $p(s = \\textrm{left}) = 0.3$ and $p(s = \\textrm{right}) = 0.7$. In the video, we learned that the chance of catching a fish given they fish on the same side as the school was 50%. Otherwise, it was 10%. We observe a person fishing on the left side. Our likelihood is:\n",
"\n",
"\n",
"| Likelihood: p(m \\| s) | m = fish | m = no fish |\n",
"| ----------------- |----------|----------|\n",
"| s = left | 0.5 | 0.5 |\n",
"| s = right | 0.1 | 0.9 |\n",
"\n",
"\n",
"We want our full posterior to take the same 2 by 2 form. Make sure the outputs match your math answers!\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def compute_posterior(likelihood, prior):\n",
" \"\"\" Use Bayes' Rule to compute posterior from likelihood and prior\n",
"\n",
" Args:\n",
" likelihood (ndarray): i x j array with likelihood probabilities where i is\n",
" number of state options, j is number of measurement options\n",
" prior (ndarray): i x 1 array with prior probability of each state\n",
"\n",
" Returns:\n",
" ndarray: i x j array with posterior probabilities where i is\n",
" number of state options, j is number of measurement options\n",
"\n",
" \"\"\"\n",
"\n",
" #################################################\n",
" ## TODO for students ##\n",
" # Fill out function and remove\n",
" raise NotImplementedError(\"Student exercise: implement compute_posterior\")\n",
" #################################################\n",
"\n",
" # Compute unnormalized posterior (likelihood times prior)\n",
" posterior = ... # first row is s = left, second row is s = right\n",
"\n",
" # Compute p(m)\n",
" p_m = np.sum(posterior, axis = 0)\n",
"\n",
" # Normalize posterior (divide elements by p_m)\n",
" posterior /= ...\n",
"\n",
" return posterior\n",
"\n",
"\n",
"# Make prior\n",
"prior = np.array([0.3, 0.7]).reshape((2, 1)) # first row is s = left, second row is s = right\n",
"\n",
"# Make likelihood\n",
"likelihood = np.array([[0.5, 0.5], [0.1, 0.9]]) # first row is s = left, second row is s = right\n",
"\n",
"# Compute posterior\n",
"posterior = compute_posterior(likelihood, prior)\n",
"\n",
"# Visualize\n",
"plot_prior_likelihood_posterior(prior, likelihood, posterior)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D1_BayesianDecisions/solutions/W3D1_Tutorial1_Solution_1a2cc907.py)\n",
"\n",
"*Example output:*\n",
"\n",
"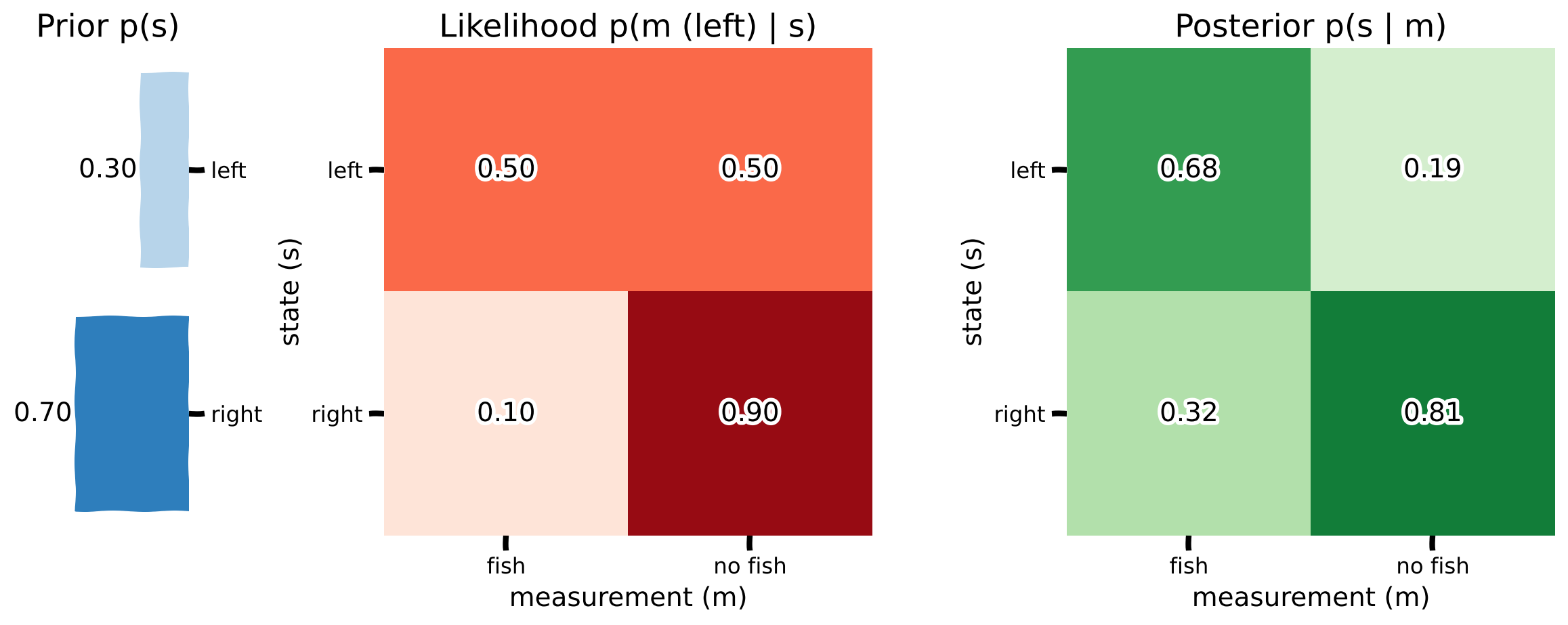 \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Computing_Posteriors_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Interactive Demo 5: What affects the posterior?\n",
"\n",
"Now that we can understand the implementation of *Bayes rule*, let's vary the parameters of the prior and likelihood to see how changing the prior and likelihood affect the posterior.\n",
"\n",
"In the demo below, you can change the prior by playing with the slider for $p( s = left)$. You can also change the likelihood by changing the probability of catching a fish given that the school is on the left and the probability of catching a fish given that the school is on the right. The fisher-person you are observing is fishing on the left.\n",
"\n",
"\n",
"1. Keeping the likelihood constant, when does the prior have the strongest influence over the posterior? Meaning, when does the posterior look most like the prior no matter whether a fish was caught or not?\n",
"2. What happens if the likelihoods for catching a fish are similar when you fish on the correct or incorrect side?\n",
"3. Set the prior probability of the state = left to 0.6 and play with the likelihood. When does the likelihood exert the most influence over the posterior?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute this cell to enable the widget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute this cell to enable the widget\n",
"# style = {'description_width': 'initial'}\n",
"ps_widget = widgets.FloatSlider(0.3, description='p(s = left)',\n",
" min=0.01, max=0.99, step=0.01)\n",
"p_a_s1_widget = widgets.FloatSlider(0.5,\n",
" description='p(fish on left | state = left)',\n",
" min=0.01, max=0.99, step=0.01, style=style,\n",
" layout=Layout(width='370px'))\n",
"p_a_s0_widget = widgets.FloatSlider(0.1,\n",
" description='p(fish on left | state = right)',\n",
" min=0.01, max=0.99, step=0.01, style=style,\n",
" layout=Layout(width='370px'))\n",
"\n",
"observed_widget = ToggleButtons(options=['Fish', 'No Fish'],\n",
" description='Observation (m) on the left:', disabled=False, button_style='',\n",
" layout=Layout(width='auto', display=\"flex\"),\n",
" style={'description_width': 'initial'}\n",
")\n",
"\n",
"widget_ui = VBox([ps_widget,\n",
" HBox([p_a_s1_widget, p_a_s0_widget]),\n",
" observed_widget])\n",
"widget_out = interactive_output(plot_prior_likelihood,\n",
" {'ps': ps_widget,\n",
" 'p_a_s1': p_a_s1_widget,\n",
" 'p_a_s0': p_a_s0_widget,\n",
" 'measurement': observed_widget})\n",
"display(widget_ui, widget_out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D1_BayesianDecisions/solutions/W3D1_Tutorial1_Solution_b12db064.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_What_affects_the_posterior_Interactive_Demo_and_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Video 8: Posterior Beliefs Exercises Discussion\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 8: Posterior Beliefs Exercises Discussion\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'YPQgLVolvBs'), ('Bilibili', 'BV1TU4y1G7SM')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Posterior_Beliefs_Exercises_Discussion_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Section 6: Making Bayesian fishing decisions\n",
"\n",
"*Estimated timing to here from start of tutorial: 1 hr, 15 min*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 9: Bayesian Decisions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 9: Bayesian Decisions\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'tz9zsmTHR68'), ('Bilibili', 'BV1954y1n7uH')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Bayesian_Decisions_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
"We will explore how to consider the expected utility of an action based on our belief (the posterior distribution) about where we think the fish are. Now we have all the components of a Bayesian decision: our prior information, the likelihood given a measurement, the posterior distribution (belief) and our utility (the gains and losses). This allows us to consider the relationship between the true value of the hidden state, $s$, and what we *expect* to get if we take action, $a$, based on our belief!\n",
"\n",
"Let's use the following widget to think about the relationship between these probability distributions and utility function."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Interactive Demo! 6: What is more important, the probabilities or the utilities?\n",
"\n",
"We are now going to put everything we've learned together to gain some intuitions for how each of the elements that goes into a Bayesian decision comes together. Remember, the common assumption in neuroscience, psychology, economics, ecology, etc. is that we (humans and animals) are trying to maximize our expected utility. There is a lot going on in this demo as it brings everything in this tutorial together in one place - please spend time making sure you understand the controls and the plots, especially how everything relates together.\n",
"\n",
"1. Can you find a situation where the expected utility is the same for both actions?\n",
"2. What is more important for determining the expected utility: the prior or a new measurement (the likelihood)?\n",
"3. Why is this a normative model?\n",
"4. Can you think of ways in which this model would need to be extended to describe human or animal behavior?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute this cell to enable the widget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute this cell to enable the widget\n",
"# style = {'description_width': 'initial'}\n",
"\n",
"ps_widget = widgets.FloatSlider(0.3, description='p(s = left)',\n",
" min=0.01, max=0.99, step=0.01,\n",
" layout=Layout(width='300px'))\n",
"p_a_s1_widget = widgets.FloatSlider(0.5,\n",
" description='p(fish on left | state = left)',\n",
" min=0.01, max=0.99, step=0.01,\n",
" style=style, layout=Layout(width='370px'))\n",
"p_a_s0_widget = widgets.FloatSlider(0.1,\n",
" description='p(fish on left | state = right)',\n",
" min=0.01, max=0.99, step=0.01,\n",
" style=style, layout=Layout(width='370px'))\n",
"\n",
"observed_widget = ToggleButtons(options=['Fish', 'No Fish'],\n",
" description='Observation (m) on the left:', disabled=False, button_style='',\n",
" layout=Layout(width='auto', display=\"flex\"),\n",
" style={'description_width': 'initial'}\n",
")\n",
"\n",
"widget_ui = VBox([ps_widget,\n",
" HBox([p_a_s1_widget, p_a_s0_widget]),\n",
" observed_widget])\n",
"\n",
"widget_out = interactive_output(plot_prior_likelihood_utility,\n",
" {'ps': ps_widget,\n",
" 'p_a_s1': p_a_s1_widget,\n",
" 'p_a_s0': p_a_s0_widget,\n",
" 'measurement': observed_widget})\n",
"display(widget_ui, widget_out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D1_BayesianDecisions/solutions/W3D1_Tutorial1_Solution_fb91b9f9.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Probabilities_vs_utilities_Interactive_Demo_and_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Video 10: Bayesian Decisions Demo Discussion\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 10: Bayesian Decisions Demo Discussion\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'h9L0EYmUpHs'), ('Bilibili', 'BV1QU4y137BS')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Bayesian_Decisions_Demo_Discussion_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Summary\n",
"\n",
"*Estimated timing of tutorial: 1 hour, 30 minutes*\n",
"\n",
"In this tutorial, you learned about combining prior information with new measurements to update your knowledge using Bayes Rule, in the context of a fishing problem.\n",
"\n",
"Specifically, we covered:\n",
"\n",
"* That the likelihood is the probability of the measurement given some hidden state\n",
"\n",
"* That how the prior and likelihood interact to create the posterior, the probability of the hidden state given a measurement, depends on how they covary\n",
"\n",
"* That utility is the gain from each action and state pair, and the expected utility for an action is the sum of the utility for all state pairs, weighted by the probability of that state happening. You can then choose the action with the highest expected utility.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Bonus"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus Section 1: Correlation Formula\n",
"\n",
"To understand the way we calculate the correlation, we need to review the definition of covariance and correlation.\n",
"\n",
"
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Computing_Posteriors_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Interactive Demo 5: What affects the posterior?\n",
"\n",
"Now that we can understand the implementation of *Bayes rule*, let's vary the parameters of the prior and likelihood to see how changing the prior and likelihood affect the posterior.\n",
"\n",
"In the demo below, you can change the prior by playing with the slider for $p( s = left)$. You can also change the likelihood by changing the probability of catching a fish given that the school is on the left and the probability of catching a fish given that the school is on the right. The fisher-person you are observing is fishing on the left.\n",
"\n",
"\n",
"1. Keeping the likelihood constant, when does the prior have the strongest influence over the posterior? Meaning, when does the posterior look most like the prior no matter whether a fish was caught or not?\n",
"2. What happens if the likelihoods for catching a fish are similar when you fish on the correct or incorrect side?\n",
"3. Set the prior probability of the state = left to 0.6 and play with the likelihood. When does the likelihood exert the most influence over the posterior?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute this cell to enable the widget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute this cell to enable the widget\n",
"# style = {'description_width': 'initial'}\n",
"ps_widget = widgets.FloatSlider(0.3, description='p(s = left)',\n",
" min=0.01, max=0.99, step=0.01)\n",
"p_a_s1_widget = widgets.FloatSlider(0.5,\n",
" description='p(fish on left | state = left)',\n",
" min=0.01, max=0.99, step=0.01, style=style,\n",
" layout=Layout(width='370px'))\n",
"p_a_s0_widget = widgets.FloatSlider(0.1,\n",
" description='p(fish on left | state = right)',\n",
" min=0.01, max=0.99, step=0.01, style=style,\n",
" layout=Layout(width='370px'))\n",
"\n",
"observed_widget = ToggleButtons(options=['Fish', 'No Fish'],\n",
" description='Observation (m) on the left:', disabled=False, button_style='',\n",
" layout=Layout(width='auto', display=\"flex\"),\n",
" style={'description_width': 'initial'}\n",
")\n",
"\n",
"widget_ui = VBox([ps_widget,\n",
" HBox([p_a_s1_widget, p_a_s0_widget]),\n",
" observed_widget])\n",
"widget_out = interactive_output(plot_prior_likelihood,\n",
" {'ps': ps_widget,\n",
" 'p_a_s1': p_a_s1_widget,\n",
" 'p_a_s0': p_a_s0_widget,\n",
" 'measurement': observed_widget})\n",
"display(widget_ui, widget_out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D1_BayesianDecisions/solutions/W3D1_Tutorial1_Solution_b12db064.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_What_affects_the_posterior_Interactive_Demo_and_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Video 8: Posterior Beliefs Exercises Discussion\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 8: Posterior Beliefs Exercises Discussion\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'YPQgLVolvBs'), ('Bilibili', 'BV1TU4y1G7SM')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Posterior_Beliefs_Exercises_Discussion_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Section 6: Making Bayesian fishing decisions\n",
"\n",
"*Estimated timing to here from start of tutorial: 1 hr, 15 min*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 9: Bayesian Decisions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 9: Bayesian Decisions\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'tz9zsmTHR68'), ('Bilibili', 'BV1954y1n7uH')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Bayesian_Decisions_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
"We will explore how to consider the expected utility of an action based on our belief (the posterior distribution) about where we think the fish are. Now we have all the components of a Bayesian decision: our prior information, the likelihood given a measurement, the posterior distribution (belief) and our utility (the gains and losses). This allows us to consider the relationship between the true value of the hidden state, $s$, and what we *expect* to get if we take action, $a$, based on our belief!\n",
"\n",
"Let's use the following widget to think about the relationship between these probability distributions and utility function."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Interactive Demo! 6: What is more important, the probabilities or the utilities?\n",
"\n",
"We are now going to put everything we've learned together to gain some intuitions for how each of the elements that goes into a Bayesian decision comes together. Remember, the common assumption in neuroscience, psychology, economics, ecology, etc. is that we (humans and animals) are trying to maximize our expected utility. There is a lot going on in this demo as it brings everything in this tutorial together in one place - please spend time making sure you understand the controls and the plots, especially how everything relates together.\n",
"\n",
"1. Can you find a situation where the expected utility is the same for both actions?\n",
"2. What is more important for determining the expected utility: the prior or a new measurement (the likelihood)?\n",
"3. Why is this a normative model?\n",
"4. Can you think of ways in which this model would need to be extended to describe human or animal behavior?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute this cell to enable the widget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute this cell to enable the widget\n",
"# style = {'description_width': 'initial'}\n",
"\n",
"ps_widget = widgets.FloatSlider(0.3, description='p(s = left)',\n",
" min=0.01, max=0.99, step=0.01,\n",
" layout=Layout(width='300px'))\n",
"p_a_s1_widget = widgets.FloatSlider(0.5,\n",
" description='p(fish on left | state = left)',\n",
" min=0.01, max=0.99, step=0.01,\n",
" style=style, layout=Layout(width='370px'))\n",
"p_a_s0_widget = widgets.FloatSlider(0.1,\n",
" description='p(fish on left | state = right)',\n",
" min=0.01, max=0.99, step=0.01,\n",
" style=style, layout=Layout(width='370px'))\n",
"\n",
"observed_widget = ToggleButtons(options=['Fish', 'No Fish'],\n",
" description='Observation (m) on the left:', disabled=False, button_style='',\n",
" layout=Layout(width='auto', display=\"flex\"),\n",
" style={'description_width': 'initial'}\n",
")\n",
"\n",
"widget_ui = VBox([ps_widget,\n",
" HBox([p_a_s1_widget, p_a_s0_widget]),\n",
" observed_widget])\n",
"\n",
"widget_out = interactive_output(plot_prior_likelihood_utility,\n",
" {'ps': ps_widget,\n",
" 'p_a_s1': p_a_s1_widget,\n",
" 'p_a_s0': p_a_s0_widget,\n",
" 'measurement': observed_widget})\n",
"display(widget_ui, widget_out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W3D1_BayesianDecisions/solutions/W3D1_Tutorial1_Solution_fb91b9f9.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Probabilities_vs_utilities_Interactive_Demo_and_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Video 10: Bayesian Decisions Demo Discussion\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 10: Bayesian Decisions Demo Discussion\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'h9L0EYmUpHs'), ('Bilibili', 'BV1QU4y137BS')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Bayesian_Decisions_Demo_Discussion_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Summary\n",
"\n",
"*Estimated timing of tutorial: 1 hour, 30 minutes*\n",
"\n",
"In this tutorial, you learned about combining prior information with new measurements to update your knowledge using Bayes Rule, in the context of a fishing problem.\n",
"\n",
"Specifically, we covered:\n",
"\n",
"* That the likelihood is the probability of the measurement given some hidden state\n",
"\n",
"* That how the prior and likelihood interact to create the posterior, the probability of the hidden state given a measurement, depends on how they covary\n",
"\n",
"* That utility is the gain from each action and state pair, and the expected utility for an action is the sum of the utility for all state pairs, weighted by the probability of that state happening. You can then choose the action with the highest expected utility.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Bonus"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus Section 1: Correlation Formula\n",
"\n",
"To understand the way we calculate the correlation, we need to review the definition of covariance and correlation.\n",
"\n",
"
\n",
"\n",
"Covariance:\n",
"\n",
"\\begin{align}\n",
"\\text{cov}(X,Y) \\equiv \\sigma_{XY} &= \\mathbb{E} [ (X - \\mathbb{E}[X])(Y - \\mathbb{E}[Y]) ] \\\\\n",
"&= \\mathbb{E}[ XY - X\\mathbb{E}[Y] - \\mathbb{E}[X]Y + \\mathbb{E}[X]\\mathbb{E}[Y] ] \\\\\n",
"&= \\mathbb{E}[XY] - \\mathbb{E}[X]\\mathbb{E}[Y] - \\mathbb{E}[X]\\mathbb{E}[Y] + \\mathbb{E}[X]\\mathbb{E}[Y]\\\\\n",
"&= \\mathbb{E}[XY] - \\mathbb{E}[X]\\mathbb{E}[Y].\n",
"\\end{align}\n",
"\n",
"Correlation:\n",
"\n",
"\\begin{equation}\n",
"\\rho_{XY} = \\frac{\\text{cov}(X,Y)}{\\sqrt{\\text{var}(X)\\text{var}(Y)}} = \\frac{\\sigma_{XY}}{\\sigma_{X}\\sigma_{Y}}\n",
"\\end{equation}"
]
}
],
"metadata": {
"colab": {
"collapsed_sections": [
"jWmfLbhzBpfz"
],
"include_colab_link": true,
"name": "W3D1_Tutorial1",
"provenance": [],
"toc_visible": true
},
"interpreter": {
"hash": "3e19903e646247cead5404f55ff575624523d45cf244c3f93aaf5fa10367032a"
},
"kernel": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"kernelspec": {
"display_name": "Python 3.7.10 64-bit ('nma': conda)",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.21"
}
},
"nbformat": 4,
"nbformat_minor": 0
}