{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {},
"id": "view-in-github"
},
"source": [
"
 "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial 2: Markov Processes\n",
"\n",
"**Week 2, Day 2: Linear Systems**\n",
"\n",
"**By Neuromatch Academy**\n",
"\n",
"**Content Creators**: Bing Wen Brunton, Ellie Stradquist\n",
"\n",
"**Content Reviewers**: Norma Kuhn, Karolina Stosio, John Butler, Matthew Krause, Ella Batty, Richard Gao, Michael Waskom, Ethan Cheng\n",
"\n",
"**Production editors:** Gagana B, Spiros Chavlis"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Tutorial Objectives\n",
"\n",
"*Estimated timing of tutorial: 45 minutes*\n",
"\n",
"In this tutorial, we will look at the dynamical systems introduced in the first tutorial through a different lens.\n",
"\n",
"In Tutorial 1, we studied dynamical systems as a deterministic process. For Tutorial 2, we will look at **probabilistic** dynamical systems. You may sometimes hear these systems called _stochastic_. In a probabilistic process, elements of randomness are involved. Every time you observe some probabilistic dynamical system, starting from the same initial conditions, the outcome will likely be different. Put another way, dynamical systems that involve probability will incorporate random variations in their behavior.\n",
"\n",
"For some probabilistic dynamical systems, the differential equations express a relationship between $\\dot{x}$ and $x$ at every time $t$, so that the direction of $x$ at _every_ time depends entirely on the value of $x$. Said a different way, knowledge of the value of the state variables $x$ at time t is _all_ the information needed to determine $\\dot{x}$ and therefore $x$ at the next time.\n",
"\n",
"This property --- that the present state entirely determines the transition to the next state --- is what defines a **Markov process** and systems obeying this property can be described as **Markovian**.\n",
"\n",
"The goal of Tutorial 2 is to consider this type of Markov process in a simple example where the state transitions are probabilistic. In particular, we will:\n",
"\n",
"* Understand Markov processes and history dependence.\n",
"* Explore the behavior of a two-state telegraph process and understand how its equilibrium distribution is dependent on its parameters."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @markdown\n",
"from IPython.display import IFrame\n",
"from ipywidgets import widgets\n",
"out = widgets.Output()\n",
"with out:\n",
" print(f\"If you want to download the slides: https://osf.io/download/snv4m/\")\n",
" display(IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/snv4m/?direct%26mode=render%26action=download%26mode=render\", width=730, height=410))\n",
"display(out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Setup"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install and import feedback gadget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install and import feedback gadget\n",
"\n",
"!pip3 install vibecheck datatops --quiet\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
" return DatatopsContentReviewContainer(\n",
" \"\", # No text prompt\n",
" notebook_section,\n",
" {\n",
" \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
" \"name\": \"neuromatch_cn\",\n",
" \"user_key\": \"y1x3mpx5\",\n",
" },\n",
" ).render()\n",
"\n",
"\n",
"feedback_prefix = \"W2D2_T2\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Imports\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Figure Settings\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Figure Settings\n",
"import logging\n",
"logging.getLogger('matplotlib.font_manager').disabled = True\n",
"import ipywidgets as widgets # interactive display\n",
"%config InlineBackend.figure_format = 'retina'\n",
"plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Plotting Functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Plotting Functions\n",
"\n",
"def plot_switch_simulation(t, x):\n",
" plt.figure()\n",
" plt.plot(t, x)\n",
" plt.title('State-switch simulation')\n",
" plt.xlabel('Time')\n",
" plt.xlim((0, 300)) # zoom in time\n",
" plt.ylabel('State of ion channel 0/1', labelpad=-60)\n",
" plt.yticks([0, 1], ['Closed (0)', 'Open (1)'])\n",
" plt.show()\n",
"\n",
"\n",
"def plot_interswitch_interval_histogram(inter_switch_intervals):\n",
" plt.figure()\n",
" plt.hist(inter_switch_intervals)\n",
" plt.title('Inter-switch Intervals Distribution')\n",
" plt.ylabel('Interval Count')\n",
" plt.xlabel('time')\n",
" plt.show()\n",
"\n",
"\n",
"def plot_state_probabilities(time, states):\n",
" plt.figure()\n",
" plt.plot(time, states[:, 0], label='Closed')\n",
" plt.plot(time, states[:, 1], label='Open')\n",
" plt.xlabel('time')\n",
" plt.ylabel('prob(open OR closed)')\n",
" plt.legend()\n",
" plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 1: Telegraph Process"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 1: Markov Process\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 1: Markov Process\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'xZO6GbU48ns'), ('Bilibili', 'BV11C4y1h7Eu')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Markov_Process_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"This video covers a definition of Markov processes and an introduction to ion channels opening/closing as an example of a telegraph process.\n",
"\n",
"Let's consider a Markov process with two states, where switches between each two states are probabilistic (known as a telegraph process). To be concrete, let's say we are modeling an **ion channel in a neuron that can be in one of two states: Closed (0) or Open (1)**.\n",
"\n",
"If the ion channel is Closed, it may transition to the Open state with probability $P(0 \\rightarrow 1 | x = 0) = \\mu_{c2o}$. Likewise, If the ion channel is Open, it transitions to Closed with probability $P(1 \\rightarrow 0 | x=1) = \\mu_{o2c}$.\n",
"\n",
"We simulate the process of changing states as a **Poisson process**. You have seen the Poisson process in the [pre-reqs statistics day](https://compneuro.neuromatch.io/tutorials/W0D5_Statistics/student/W0D5_Tutorial1.html). The Poisson process is a way to model discrete events where the average time between event occurrences is known but the exact time of some event is not known. Importantly, the Poisson process dictates the following points:\n",
"1. The probability of some event occurring is _independent from all other events_.\n",
"2. The average rate of events within a given time period is constant.\n",
"3. Two events cannot occur at the same moment. Our ion channel can either be in an open or closed state, but not both simultaneously.\n",
"\n",
"In the simulation below, we will use the Poisson process to model the state of our ion channel at all points $t$ within the total simulation time $T$.\n",
"\n",
"As we simulate the state change process, we also track at which times throughout the simulation the state makes a switch. We can use those times to measure the distribution of the time _intervals_ between state switches.\n",
"\n",
"You briefly saw a Markov process in the [pre-reqs statistics day](https://compneuro.neuromatch.io/tutorials/W0D5_Statistics/student/W0D5_Tutorial2.html#section-1-2-markov-chains).\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Run the cell below to show the state-change simulation process. Note that a random seed was set in the code block, so re-running the code will produce the same plot. Commenting out that line will produce a different simulation each run."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute to simulate and plot state changes\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute to simulate and plot state changes\n",
"\n",
"# parameters\n",
"T = 5000 # total Time duration\n",
"dt = 0.001 # timestep of our simulation\n",
"\n",
"# simulate state of our ion channel in time\n",
"# the two parameters that govern transitions are\n",
"# c2o: closed to open rate\n",
"# o2c: open to closed rate\n",
"def ion_channel_opening(c2o, o2c, T, dt):\n",
" # initialize variables\n",
" t = np.arange(0, T, dt)\n",
" x = np.zeros_like(t)\n",
" switch_times = []\n",
"\n",
" # assume we always start in Closed state\n",
" x[0] = 0\n",
"\n",
" # generate a bunch of random uniformly distributed numbers\n",
" # between zero and unity: [0, 1),\n",
" # one for each dt in our simulation.\n",
" # we will use these random numbers to model the\n",
" # closed/open transitions\n",
" myrand = np.random.random_sample(size=len(t))\n",
"\n",
"\n",
" # walk through time steps of the simulation\n",
" for k in range(len(t)-1):\n",
" # switching between closed/open states are\n",
" # Poisson processes\n",
" if x[k] == 0 and myrand[k] < c2o*dt: # remember to scale by dt!\n",
" x[k+1:] = 1\n",
" switch_times.append(k*dt)\n",
" elif x[k] == 1 and myrand[k] < o2c*dt:\n",
" x[k+1:] = 0\n",
" switch_times.append(k*dt)\n",
"\n",
" return t, x, switch_times\n",
"\n",
"\n",
"c2o = 0.02\n",
"o2c = 0.1\n",
"np.random.seed(0) # set random seed\n",
"t, x, switch_times = ion_channel_opening(c2o, o2c, T, .1)\n",
"plot_switch_simulation(t, x)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Coding Exercise 1: Computing intervals between switches\n",
"\n",
"*Referred to in video as exercise 2A*\n",
"\n",
"We now have `switch_times`, which is a list consisting of times when the state switched. Using this, calculate the time intervals between each state switch and store these in a list called `inter_switch_intervals`.\n",
"\n",
"We will then plot the distribution of these intervals. How would you describe the shape of the distribution?\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"##############################################################################\n",
"## TODO: Insert your code here to calculate between-state-switch intervals\n",
"raise NotImplementedError(\"Student exercise: need to calculate switch intervals\")\n",
"##############################################################################\n",
"\n",
"# hint: see np.diff()\n",
"inter_switch_intervals = ...\n",
"\n",
"# plot inter-switch intervals\n",
"plot_interswitch_interval_histogram(inter_switch_intervals)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W2D2_LinearSystems/solutions/W2D2_Tutorial2_Solution_15275c81.py)\n",
"\n",
"*Example output:*\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial 2: Markov Processes\n",
"\n",
"**Week 2, Day 2: Linear Systems**\n",
"\n",
"**By Neuromatch Academy**\n",
"\n",
"**Content Creators**: Bing Wen Brunton, Ellie Stradquist\n",
"\n",
"**Content Reviewers**: Norma Kuhn, Karolina Stosio, John Butler, Matthew Krause, Ella Batty, Richard Gao, Michael Waskom, Ethan Cheng\n",
"\n",
"**Production editors:** Gagana B, Spiros Chavlis"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Tutorial Objectives\n",
"\n",
"*Estimated timing of tutorial: 45 minutes*\n",
"\n",
"In this tutorial, we will look at the dynamical systems introduced in the first tutorial through a different lens.\n",
"\n",
"In Tutorial 1, we studied dynamical systems as a deterministic process. For Tutorial 2, we will look at **probabilistic** dynamical systems. You may sometimes hear these systems called _stochastic_. In a probabilistic process, elements of randomness are involved. Every time you observe some probabilistic dynamical system, starting from the same initial conditions, the outcome will likely be different. Put another way, dynamical systems that involve probability will incorporate random variations in their behavior.\n",
"\n",
"For some probabilistic dynamical systems, the differential equations express a relationship between $\\dot{x}$ and $x$ at every time $t$, so that the direction of $x$ at _every_ time depends entirely on the value of $x$. Said a different way, knowledge of the value of the state variables $x$ at time t is _all_ the information needed to determine $\\dot{x}$ and therefore $x$ at the next time.\n",
"\n",
"This property --- that the present state entirely determines the transition to the next state --- is what defines a **Markov process** and systems obeying this property can be described as **Markovian**.\n",
"\n",
"The goal of Tutorial 2 is to consider this type of Markov process in a simple example where the state transitions are probabilistic. In particular, we will:\n",
"\n",
"* Understand Markov processes and history dependence.\n",
"* Explore the behavior of a two-state telegraph process and understand how its equilibrium distribution is dependent on its parameters."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @markdown\n",
"from IPython.display import IFrame\n",
"from ipywidgets import widgets\n",
"out = widgets.Output()\n",
"with out:\n",
" print(f\"If you want to download the slides: https://osf.io/download/snv4m/\")\n",
" display(IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/snv4m/?direct%26mode=render%26action=download%26mode=render\", width=730, height=410))\n",
"display(out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Setup"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install and import feedback gadget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install and import feedback gadget\n",
"\n",
"!pip3 install vibecheck datatops --quiet\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
" return DatatopsContentReviewContainer(\n",
" \"\", # No text prompt\n",
" notebook_section,\n",
" {\n",
" \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
" \"name\": \"neuromatch_cn\",\n",
" \"user_key\": \"y1x3mpx5\",\n",
" },\n",
" ).render()\n",
"\n",
"\n",
"feedback_prefix = \"W2D2_T2\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Imports\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Figure Settings\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Figure Settings\n",
"import logging\n",
"logging.getLogger('matplotlib.font_manager').disabled = True\n",
"import ipywidgets as widgets # interactive display\n",
"%config InlineBackend.figure_format = 'retina'\n",
"plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Plotting Functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Plotting Functions\n",
"\n",
"def plot_switch_simulation(t, x):\n",
" plt.figure()\n",
" plt.plot(t, x)\n",
" plt.title('State-switch simulation')\n",
" plt.xlabel('Time')\n",
" plt.xlim((0, 300)) # zoom in time\n",
" plt.ylabel('State of ion channel 0/1', labelpad=-60)\n",
" plt.yticks([0, 1], ['Closed (0)', 'Open (1)'])\n",
" plt.show()\n",
"\n",
"\n",
"def plot_interswitch_interval_histogram(inter_switch_intervals):\n",
" plt.figure()\n",
" plt.hist(inter_switch_intervals)\n",
" plt.title('Inter-switch Intervals Distribution')\n",
" plt.ylabel('Interval Count')\n",
" plt.xlabel('time')\n",
" plt.show()\n",
"\n",
"\n",
"def plot_state_probabilities(time, states):\n",
" plt.figure()\n",
" plt.plot(time, states[:, 0], label='Closed')\n",
" plt.plot(time, states[:, 1], label='Open')\n",
" plt.xlabel('time')\n",
" plt.ylabel('prob(open OR closed)')\n",
" plt.legend()\n",
" plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 1: Telegraph Process"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 1: Markov Process\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 1: Markov Process\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'xZO6GbU48ns'), ('Bilibili', 'BV11C4y1h7Eu')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Markov_Process_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"This video covers a definition of Markov processes and an introduction to ion channels opening/closing as an example of a telegraph process.\n",
"\n",
"Let's consider a Markov process with two states, where switches between each two states are probabilistic (known as a telegraph process). To be concrete, let's say we are modeling an **ion channel in a neuron that can be in one of two states: Closed (0) or Open (1)**.\n",
"\n",
"If the ion channel is Closed, it may transition to the Open state with probability $P(0 \\rightarrow 1 | x = 0) = \\mu_{c2o}$. Likewise, If the ion channel is Open, it transitions to Closed with probability $P(1 \\rightarrow 0 | x=1) = \\mu_{o2c}$.\n",
"\n",
"We simulate the process of changing states as a **Poisson process**. You have seen the Poisson process in the [pre-reqs statistics day](https://compneuro.neuromatch.io/tutorials/W0D5_Statistics/student/W0D5_Tutorial1.html). The Poisson process is a way to model discrete events where the average time between event occurrences is known but the exact time of some event is not known. Importantly, the Poisson process dictates the following points:\n",
"1. The probability of some event occurring is _independent from all other events_.\n",
"2. The average rate of events within a given time period is constant.\n",
"3. Two events cannot occur at the same moment. Our ion channel can either be in an open or closed state, but not both simultaneously.\n",
"\n",
"In the simulation below, we will use the Poisson process to model the state of our ion channel at all points $t$ within the total simulation time $T$.\n",
"\n",
"As we simulate the state change process, we also track at which times throughout the simulation the state makes a switch. We can use those times to measure the distribution of the time _intervals_ between state switches.\n",
"\n",
"You briefly saw a Markov process in the [pre-reqs statistics day](https://compneuro.neuromatch.io/tutorials/W0D5_Statistics/student/W0D5_Tutorial2.html#section-1-2-markov-chains).\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Run the cell below to show the state-change simulation process. Note that a random seed was set in the code block, so re-running the code will produce the same plot. Commenting out that line will produce a different simulation each run."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute to simulate and plot state changes\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute to simulate and plot state changes\n",
"\n",
"# parameters\n",
"T = 5000 # total Time duration\n",
"dt = 0.001 # timestep of our simulation\n",
"\n",
"# simulate state of our ion channel in time\n",
"# the two parameters that govern transitions are\n",
"# c2o: closed to open rate\n",
"# o2c: open to closed rate\n",
"def ion_channel_opening(c2o, o2c, T, dt):\n",
" # initialize variables\n",
" t = np.arange(0, T, dt)\n",
" x = np.zeros_like(t)\n",
" switch_times = []\n",
"\n",
" # assume we always start in Closed state\n",
" x[0] = 0\n",
"\n",
" # generate a bunch of random uniformly distributed numbers\n",
" # between zero and unity: [0, 1),\n",
" # one for each dt in our simulation.\n",
" # we will use these random numbers to model the\n",
" # closed/open transitions\n",
" myrand = np.random.random_sample(size=len(t))\n",
"\n",
"\n",
" # walk through time steps of the simulation\n",
" for k in range(len(t)-1):\n",
" # switching between closed/open states are\n",
" # Poisson processes\n",
" if x[k] == 0 and myrand[k] < c2o*dt: # remember to scale by dt!\n",
" x[k+1:] = 1\n",
" switch_times.append(k*dt)\n",
" elif x[k] == 1 and myrand[k] < o2c*dt:\n",
" x[k+1:] = 0\n",
" switch_times.append(k*dt)\n",
"\n",
" return t, x, switch_times\n",
"\n",
"\n",
"c2o = 0.02\n",
"o2c = 0.1\n",
"np.random.seed(0) # set random seed\n",
"t, x, switch_times = ion_channel_opening(c2o, o2c, T, .1)\n",
"plot_switch_simulation(t, x)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Coding Exercise 1: Computing intervals between switches\n",
"\n",
"*Referred to in video as exercise 2A*\n",
"\n",
"We now have `switch_times`, which is a list consisting of times when the state switched. Using this, calculate the time intervals between each state switch and store these in a list called `inter_switch_intervals`.\n",
"\n",
"We will then plot the distribution of these intervals. How would you describe the shape of the distribution?\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"##############################################################################\n",
"## TODO: Insert your code here to calculate between-state-switch intervals\n",
"raise NotImplementedError(\"Student exercise: need to calculate switch intervals\")\n",
"##############################################################################\n",
"\n",
"# hint: see np.diff()\n",
"inter_switch_intervals = ...\n",
"\n",
"# plot inter-switch intervals\n",
"plot_interswitch_interval_histogram(inter_switch_intervals)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W2D2_LinearSystems/solutions/W2D2_Tutorial2_Solution_15275c81.py)\n",
"\n",
"*Example output:*\n",
"\n",
"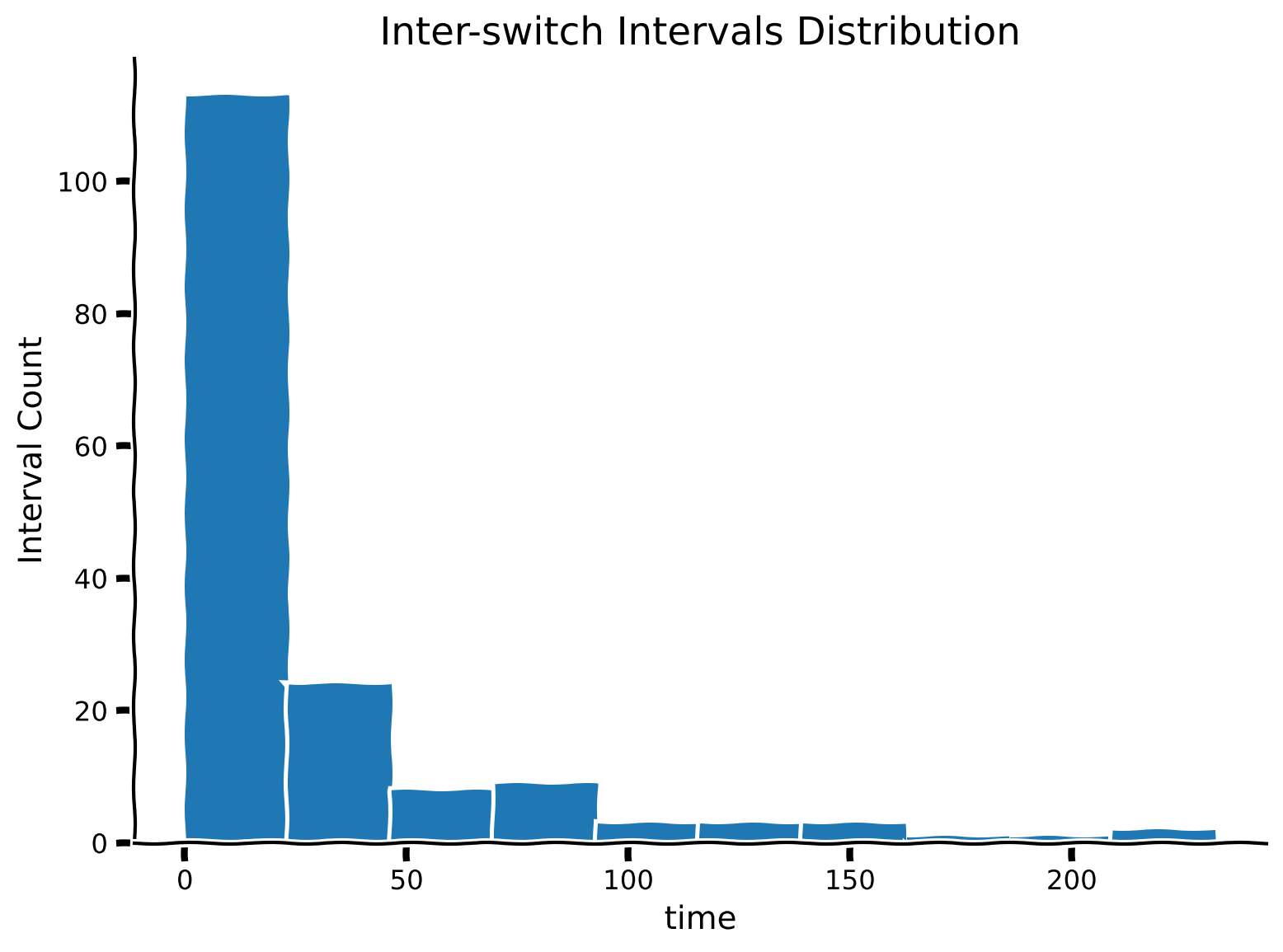 \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Computing_intervals_between_switches_Exercises\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"In the next cell, we generate a bar graph to visualize the distribution of the number of time-steps spent in each of the two possible system states during the simulation.\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute cell to visualize distribution of time spent in each state.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute cell to visualize distribution of time spent in each state.\n",
"\n",
"states = ['Closed', 'Open']\n",
"(unique, counts) = np.unique(x, return_counts=True)\n",
"\n",
"plt.figure()\n",
"plt.bar(states, counts)\n",
"plt.ylabel('Number of time steps')\n",
"plt.xlabel('State of ion channel')\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
"\n",
"Even though the state is _discrete_--the ion channel can only be either Closed or Open--we can still look at the **mean state** of the system, averaged over some window of time.\n",
"\n",
"Since we've coded Closed as $x=0$ and Open as $x=1$, conveniently, the mean of $x$ over some window of time has the interpretation of **fraction of time channel is Open**.\n",
"\n",
"Let's also take a look at the fraction of Open states as a cumulative mean of the state $x$. The cumulative mean tells us the average number of state-changes that the system will have undergone after a certain amount of time."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute to visualize cumulative mean of state\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute to visualize cumulative mean of state\n",
"plt.figure()\n",
"plt.plot(t, np.cumsum(x) / np.arange(1, len(t)+1))\n",
"plt.xlabel('time')\n",
"plt.ylabel('Cumulative mean of state')\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Notice in the plot above that, although the channel started in the Closed ($x=0$) state, gradually adopted some mean value after some time. This mean value is related to the transition probabilities $\\mu_{c2o}$\n",
"and $\\mu_{o2c}$."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Interactive Demo 1: Varying transition probability values & $T$\n",
"\n",
"Using the interactive demo below, explore the state-switch simulation for different transition probability values of states $\\mu_{c2o}$ and $\\mu_{o2c}$. Also, try different values for total simulation time length $T$.\n",
"\n",
"1. Does the general shape of the inter-switch interval distribution change or does it stay relatively the same?\n",
"2. How does the bar graph of system states change based on these values?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Make sure you execute this cell to enable the widget!\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Make sure you execute this cell to enable the widget!\n",
"\n",
"@widgets.interact\n",
"def plot_inter_switch_intervals(c2o=(0,1, .01), o2c=(0, 1, .01),\n",
" T=(1000, 10000, 1000)):\n",
"\n",
" t, x, switch_times = ion_channel_opening(c2o, o2c, T, .1)\n",
"\n",
" inter_switch_intervals = np.diff(switch_times)\n",
"\n",
" # plot inter-switch intervals\n",
" plt.hist(inter_switch_intervals)\n",
" plt.title('Inter-switch Intervals Distribution')\n",
" plt.ylabel('Interval Count')\n",
" plt.xlabel('time')\n",
" plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W2D2_LinearSystems/solutions/W2D2_Tutorial2_Solution_88c4ce10.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Varying_transition_probability_values_and_T_Interactive_Demo_and_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 2: Distributional Perspective\n",
"\n",
"*Estimated timing to here from start of tutorial: 18 min*\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 2: State Transitions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 2: State Transitions\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'U6YRhLuRhHg'), ('Bilibili', 'BV1uk4y1B7ru')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"This video serves as an introduction to the telegraph process of ion channels opening/closing with an alternative formulation as a matrix/vector representation of probabilistic state transitions.\n",
"\n",
"
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Computing_intervals_between_switches_Exercises\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"In the next cell, we generate a bar graph to visualize the distribution of the number of time-steps spent in each of the two possible system states during the simulation.\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute cell to visualize distribution of time spent in each state.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute cell to visualize distribution of time spent in each state.\n",
"\n",
"states = ['Closed', 'Open']\n",
"(unique, counts) = np.unique(x, return_counts=True)\n",
"\n",
"plt.figure()\n",
"plt.bar(states, counts)\n",
"plt.ylabel('Number of time steps')\n",
"plt.xlabel('State of ion channel')\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
"\n",
"Even though the state is _discrete_--the ion channel can only be either Closed or Open--we can still look at the **mean state** of the system, averaged over some window of time.\n",
"\n",
"Since we've coded Closed as $x=0$ and Open as $x=1$, conveniently, the mean of $x$ over some window of time has the interpretation of **fraction of time channel is Open**.\n",
"\n",
"Let's also take a look at the fraction of Open states as a cumulative mean of the state $x$. The cumulative mean tells us the average number of state-changes that the system will have undergone after a certain amount of time."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute to visualize cumulative mean of state\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute to visualize cumulative mean of state\n",
"plt.figure()\n",
"plt.plot(t, np.cumsum(x) / np.arange(1, len(t)+1))\n",
"plt.xlabel('time')\n",
"plt.ylabel('Cumulative mean of state')\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Notice in the plot above that, although the channel started in the Closed ($x=0$) state, gradually adopted some mean value after some time. This mean value is related to the transition probabilities $\\mu_{c2o}$\n",
"and $\\mu_{o2c}$."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Interactive Demo 1: Varying transition probability values & $T$\n",
"\n",
"Using the interactive demo below, explore the state-switch simulation for different transition probability values of states $\\mu_{c2o}$ and $\\mu_{o2c}$. Also, try different values for total simulation time length $T$.\n",
"\n",
"1. Does the general shape of the inter-switch interval distribution change or does it stay relatively the same?\n",
"2. How does the bar graph of system states change based on these values?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Make sure you execute this cell to enable the widget!\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Make sure you execute this cell to enable the widget!\n",
"\n",
"@widgets.interact\n",
"def plot_inter_switch_intervals(c2o=(0,1, .01), o2c=(0, 1, .01),\n",
" T=(1000, 10000, 1000)):\n",
"\n",
" t, x, switch_times = ion_channel_opening(c2o, o2c, T, .1)\n",
"\n",
" inter_switch_intervals = np.diff(switch_times)\n",
"\n",
" # plot inter-switch intervals\n",
" plt.hist(inter_switch_intervals)\n",
" plt.title('Inter-switch Intervals Distribution')\n",
" plt.ylabel('Interval Count')\n",
" plt.xlabel('time')\n",
" plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W2D2_LinearSystems/solutions/W2D2_Tutorial2_Solution_88c4ce10.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Varying_transition_probability_values_and_T_Interactive_Demo_and_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 2: Distributional Perspective\n",
"\n",
"*Estimated timing to here from start of tutorial: 18 min*\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 2: State Transitions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 2: State Transitions\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'U6YRhLuRhHg'), ('Bilibili', 'BV1uk4y1B7ru')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"This video serves as an introduction to the telegraph process of ion channels opening/closing with an alternative formulation as a matrix/vector representation of probabilistic state transitions.\n",
"\n",
"\n",
" Click here for text recap of video
\n",
"\n",
"We can run this simulation many times and gather empirical distributions of open/closed states. Alternatively, we can formulate the exact same system probabilistically, keeping track of the probability of being in each state.\n",
"\n",
"\n",
"\n",
"(see diagram in lecture)\n",
"\n",
"The same system of transitions can then be formulated using a vector of 2 elements as the state vector and a dynamics matrix $\\mathbf{A}$. The result of this formulation is a *state transition matrix*:\n",
"\n",
"\\begin{equation}\n",
"\\left[ \\begin{array}{c} C \\\\ O \\end{array} \\right]_{k+1} = \\mathbf{A} \\left[ \\begin{array}{c} C \\\\ O \\end{array} \\right]_k = \\left[ \\begin{array} & 1-\\mu_{\\text{c2o}} & \\mu_{\\text{o2c}} \\\\ \\mu_{\\text{c2o}} & 1-\\mu_{\\text{o2c}} \\end{array} \\right] \\left[ \\begin{array}{c} C \\\\ O \\end{array} \\right]_k.\n",
"\\end{equation}\n",
"\n",
"Each transition probability shown in the matrix is as follows:\n",
"1. $1-\\mu_{\\text{c2o}}$, the probability that the closed state remains closed.\n",
"2. $\\mu_{\\text{c2o}}$, the probability that the closed state transitions to the open state.\n",
"3. $\\mu_{\\text{o2c}}$, the probability that the open state transitions to the closed state.\n",
"4. $1-\\mu_{\\text{o2c}}$, the probability that the open state remains open.\n",
"\n",
" \n",
"\n",
"_Notice_ that this system is written as a discrete step in time, and $\\mathbf{A}$ describes the transition, mapping the state from step $k$ to step $k+1$. This is different from what we did in the exercises above where $\\mathbf{A}$ had described the function from the state to the time derivative of the state."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Coding Exercise 2: Probability Propagation\n",
"\n",
"*Referred to in video as exercise 2B*\n",
"\n",
"Complete the code below to simulate the propagation of probabilities of closed/open of the ion channel through time. A variable called `x_kp1` (short for, $x$ at timestep $k$ plus 1) should be calculated per each step *k* in the loop. However, you should plot $x$."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def simulate_prob_prop(A, x0, dt, T):\n",
" \"\"\" Simulate the propagation of probabilities given the transition matrix A,\n",
" with initial state x0, for a duration of T at timestep dt.\n",
"\n",
" Args:\n",
" A (ndarray): state transition matrix\n",
" x0 (ndarray): state probabilities at time 0\n",
" dt (scalar): timestep of the simulation\n",
" T (scalar): total duration of the simulation\n",
"\n",
" Returns:\n",
" ndarray, ndarray: `x` for all simulation steps and the time `t` at each step\n",
" \"\"\"\n",
"\n",
" # Initialize variables\n",
" t = np.arange(0, T, dt)\n",
" x = x0 # x at time t_0\n",
"\n",
" # Step through the system in time\n",
" for k in range(len(t)-1):\n",
" ###################################################################\n",
" ## TODO: Insert your code here to compute x_kp1 (x at k plus 1)\n",
" raise NotImplementedError(\"Student exercise: need to implement simulation\")\n",
" ## hint: use np.dot(a, b) function to compute the dot product\n",
" ## of the transition matrix A and the last state in x\n",
" ## hint 2: use np.vstack to append the latest state to x\n",
" ###################################################################\n",
"\n",
" # Compute the state of x at time k+1\n",
" x_kp1 = ...\n",
"\n",
" # Stack (append) this new state onto x to keep track of x through time steps\n",
" x = ...\n",
"\n",
" return x, t\n",
"\n",
"\n",
"# Set parameters\n",
"T = 500 # total Time duration\n",
"dt = 0.1 # timestep of our simulation\n",
"\n",
"# same parameters as above\n",
"# c: closed rate\n",
"# o: open rate\n",
"c = 0.02\n",
"o = 0.1\n",
"A = np.array([[1 - c*dt, o*dt],\n",
" [c*dt, 1 - o*dt]])\n",
"\n",
"# Initial condition: start as Closed\n",
"x0 = np.array([[1, 0]])\n",
"\n",
"# Simulate probabilities propagation\n",
"x, t = simulate_prob_prop(A, x0, dt, T)\n",
"\n",
"# Visualize\n",
"plot_state_probabilities(t, x)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W2D2_LinearSystems/solutions/W2D2_Tutorial2_Solution_41ec6e01.py)\n",
"\n",
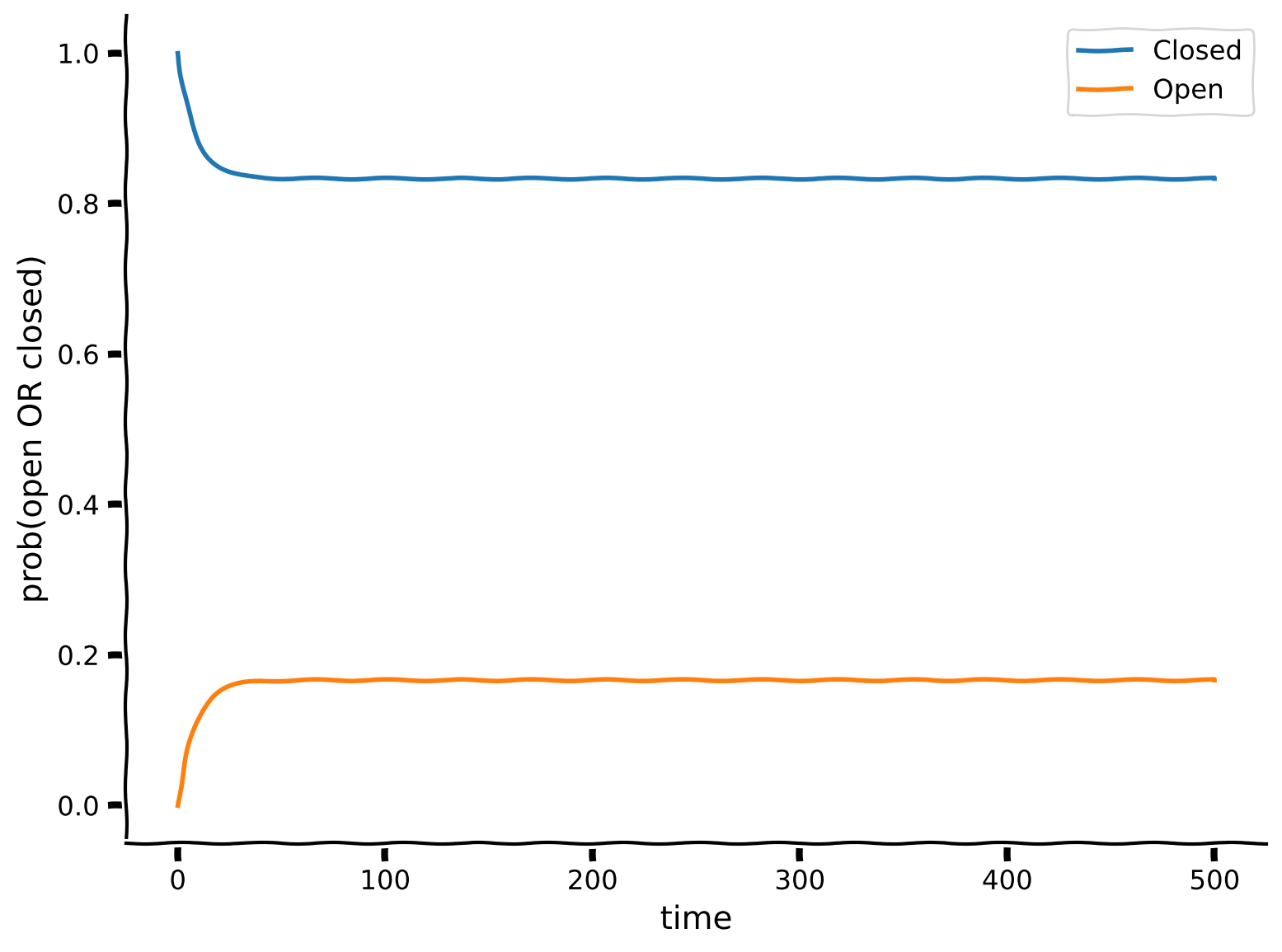
"*Example output:*\n",
"\n",
" \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Probability_propagation_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Here, we simulated the propagation of probabilities of the ion channel's state changing through time. Using this method is useful in that we can **run the simulation once** and see **how the probabilities propagate throughout time**, rather than re-running and empirically observing the telegraph simulation over and over again.\n",
"\n",
"Although the system started initially in the Closed ($x=0$) state, over time, it settles into a equilibrium distribution where we can predict what fraction of time it is Open as a function of the $\\mu$ parameters. We can say that the plot above shows this _relaxation towards equilibrium_.\n",
"\n",
"Re-calculating our value of the probability of $c2o$ again with this method, we see that this matches the simulation output from the telegraph process!\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"print(f\"Probability of state c2o: {(c2o / (c2o + o2c)):.3f}\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 3: Equilibrium of the telegraph process\n",
"\n",
"*Estimated timing to here from start of tutorial: 30 min*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 3: Continuous vs. Discrete Time Formulation\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 3: Continuous vs. Discrete Time Formulation\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'csetTTauIh8'), ('Bilibili', 'BV1di4y1g7Yc')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Continuous_vs_Discrete_time_fromulation_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Since we have now modeled the propagation of probabilities by the transition matrix $\\mathbf{A}$ in Section 2, let's connect the behavior of the system at equilibrium with the eigendecomposition of $\\mathbf{A}$.\n",
"\n",
"As introduced in the lecture video, the eigenvalues of $\\mathbf{A}$ tell us about the stability of the system, specifically in the directions of the corresponding eigenvectors."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# compute the eigendecomposition of A\n",
"lam, v = np.linalg.eig(A)\n",
"\n",
"# print the 2 eigenvalues\n",
"print(f\"Eigenvalues: {lam}\")\n",
"\n",
"# print the 2 eigenvectors\n",
"eigenvector1 = v[:, 0]\n",
"eigenvector2 = v[:, 1]\n",
"print(f\"Eigenvector 1: {eigenvector1}\")\n",
"print(f\"Eigenvector 2: {eigenvector2}\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Think! 3: Finding a stable state\n",
"\n",
"1. Which of these eigenvalues corresponds to the **stable** (equilibrium) solution?\n",
"2. What is the eigenvector of this eigenvalue?\n",
"3. How does that explain the equilibrium solutions in simulation in Section 2 of this tutorial?\n",
"\n",
"_hint_: our simulation is written in terms of probabilities, so they must sum to 1. Therefore, you may also want to rescale the elements of the eigenvector such that they also sum to 1. These can then be directly compared with the probabilities of the states in the simulation."
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W2D2_LinearSystems/solutions/W2D2_Tutorial2_Solution_37abbdad.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Finding_a_stable_state_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Summary\n",
"\n",
"*Estimated timing of tutorial: 45 minutes*\n",
"\n",
"\n",
"In this tutorial, we learned:\n",
"\n",
"* The definition of a Markov process with history dependence.\n",
"* The behavior of a simple 2-state Markov process --the telegraph process-- can be simulated either as a state-change simulation or as a propagation of probability distributions.\n",
"* The relationship between the stability analysis of a dynamical system expressed either in continuous or discrete time.\n",
"* The equilibrium behavior of a telegraph process is predictable and can be understood using the same strategy as for deterministic systems in Tutorial 1: by taking the eigendecomposition of the $\\mathbf{A}$ matrix."
]
}
],
"metadata": {
"colab": {
"collapsed_sections": [],
"include_colab_link": true,
"name": "W2D2_Tutorial2",
"provenance": [],
"toc_visible": true
},
"kernel": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.21"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Probability_propagation_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Here, we simulated the propagation of probabilities of the ion channel's state changing through time. Using this method is useful in that we can **run the simulation once** and see **how the probabilities propagate throughout time**, rather than re-running and empirically observing the telegraph simulation over and over again.\n",
"\n",
"Although the system started initially in the Closed ($x=0$) state, over time, it settles into a equilibrium distribution where we can predict what fraction of time it is Open as a function of the $\\mu$ parameters. We can say that the plot above shows this _relaxation towards equilibrium_.\n",
"\n",
"Re-calculating our value of the probability of $c2o$ again with this method, we see that this matches the simulation output from the telegraph process!\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"print(f\"Probability of state c2o: {(c2o / (c2o + o2c)):.3f}\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 3: Equilibrium of the telegraph process\n",
"\n",
"*Estimated timing to here from start of tutorial: 30 min*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 3: Continuous vs. Discrete Time Formulation\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 3: Continuous vs. Discrete Time Formulation\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'csetTTauIh8'), ('Bilibili', 'BV1di4y1g7Yc')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Continuous_vs_Discrete_time_fromulation_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Since we have now modeled the propagation of probabilities by the transition matrix $\\mathbf{A}$ in Section 2, let's connect the behavior of the system at equilibrium with the eigendecomposition of $\\mathbf{A}$.\n",
"\n",
"As introduced in the lecture video, the eigenvalues of $\\mathbf{A}$ tell us about the stability of the system, specifically in the directions of the corresponding eigenvectors."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# compute the eigendecomposition of A\n",
"lam, v = np.linalg.eig(A)\n",
"\n",
"# print the 2 eigenvalues\n",
"print(f\"Eigenvalues: {lam}\")\n",
"\n",
"# print the 2 eigenvectors\n",
"eigenvector1 = v[:, 0]\n",
"eigenvector2 = v[:, 1]\n",
"print(f\"Eigenvector 1: {eigenvector1}\")\n",
"print(f\"Eigenvector 2: {eigenvector2}\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Think! 3: Finding a stable state\n",
"\n",
"1. Which of these eigenvalues corresponds to the **stable** (equilibrium) solution?\n",
"2. What is the eigenvector of this eigenvalue?\n",
"3. How does that explain the equilibrium solutions in simulation in Section 2 of this tutorial?\n",
"\n",
"_hint_: our simulation is written in terms of probabilities, so they must sum to 1. Therefore, you may also want to rescale the elements of the eigenvector such that they also sum to 1. These can then be directly compared with the probabilities of the states in the simulation."
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W2D2_LinearSystems/solutions/W2D2_Tutorial2_Solution_37abbdad.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Finding_a_stable_state_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Summary\n",
"\n",
"*Estimated timing of tutorial: 45 minutes*\n",
"\n",
"\n",
"In this tutorial, we learned:\n",
"\n",
"* The definition of a Markov process with history dependence.\n",
"* The behavior of a simple 2-state Markov process --the telegraph process-- can be simulated either as a state-change simulation or as a propagation of probability distributions.\n",
"* The relationship between the stability analysis of a dynamical system expressed either in continuous or discrete time.\n",
"* The equilibrium behavior of a telegraph process is predictable and can be understood using the same strategy as for deterministic systems in Tutorial 1: by taking the eigendecomposition of the $\\mathbf{A}$ matrix."
]
}
],
"metadata": {
"colab": {
"collapsed_sections": [],
"include_colab_link": true,
"name": "W2D2_Tutorial2",
"provenance": [],
"toc_visible": true
},
"kernel": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.21"
}
},
"nbformat": 4,
"nbformat_minor": 0
}