{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {},
"id": "view-in-github"
},
"source": [
"
 "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial 5: Model Selection: Bias-variance trade-off\n",
"\n",
"**Week 1, Day 2: Model Fitting**\n",
"\n",
"**By Neuromatch Academy**\n",
"\n",
"**Content creators**: Pierre-Étienne Fiquet, Anqi Wu, Alex Hyafil with help from Ella Batty\n",
"\n",
"**Content reviewers**: Lina Teichmann, Patrick Mineault, Michael Waskom\n",
"\n",
"**Production editors:** Spiros Chavlis"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Tutorial Objectives\n",
"\n",
"*Estimated timing of tutorial: 25 minutes*\n",
"\n",
"This is Tutorial 5 of a series on fitting models to data. We start with simple linear regression, using least squares optimization (Tutorial 1) and Maximum Likelihood Estimation (Tutorial 2). We will use bootstrapping to build confidence intervals around the inferred linear model parameters (Tutorial 3). We'll finish our exploration of regression models by generalizing to multiple linear regression and polynomial regression (Tutorial 4). We end by learning how to choose between these various models. We discuss the bias-variance trade-off (Tutorial 5) and Cross Validation for model selection (Tutorial 6).\n",
"\n",
"In this tutorial, we will learn about the bias-variance tradeoff and see it in action using polynomial regression models.\n",
"\n",
"Tutorial objectives:\n",
"\n",
"* Understand difference between test and train data\n",
"* Compare train and test error for models of varying complexity\n",
"* Understand how bias-variance tradeoff relates to what model we choose"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @markdown\n",
"from IPython.display import IFrame\n",
"from ipywidgets import widgets\n",
"out = widgets.Output()\n",
"with out:\n",
" print(f\"If you want to download the slides: https://osf.io/download/2mkq4/\")\n",
" display(IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/2mkq4/?direct%26mode=render%26action=download%26mode=render\", width=730, height=410))\n",
"display(out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Setup"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install and import feedback gadget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install and import feedback gadget\n",
"\n",
"!pip3 install vibecheck datatops --quiet\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
" return DatatopsContentReviewContainer(\n",
" \"\", # No text prompt\n",
" notebook_section,\n",
" {\n",
" \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
" \"name\": \"neuromatch_cn\",\n",
" \"user_key\": \"y1x3mpx5\",\n",
" },\n",
" ).render()\n",
"\n",
"\n",
"feedback_prefix = \"W1D2_T5\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "both",
"execution": {}
},
"outputs": [],
"source": [
"# Imports\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Figure Settings\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Figure Settings\n",
"import logging\n",
"logging.getLogger('matplotlib.font_manager').disabled = True\n",
"\n",
"%config InlineBackend.figure_format = 'retina'\n",
"plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Plotting Functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Plotting Functions\n",
"\n",
"def plot_MSE_poly_fits(mse_train, mse_test, max_order):\n",
" \"\"\"\n",
" Plot the MSE values for various orders of polynomial fits on the same bar\n",
" graph\n",
"\n",
" Args:\n",
" mse_train (ndarray): an array of MSE values for each order of polynomial fit\n",
" over the training data\n",
" mse_test (ndarray): an array of MSE values for each order of polynomial fit\n",
" over the test data\n",
" max_order (scalar): max order of polynomial fit\n",
" \"\"\"\n",
" fig, ax = plt.subplots()\n",
" width = .35\n",
"\n",
" ax.bar(np.arange(max_order + 1) - width / 2,\n",
" mse_train, width, label=\"train MSE\")\n",
" ax.bar(np.arange(max_order + 1) + width / 2,\n",
" mse_test , width, label=\"test MSE\")\n",
"\n",
" ax.legend()\n",
" ax.set(xlabel='Polynomial order', ylabel='MSE',\n",
" title='Comparing polynomial fits')\n",
" plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Helper functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Helper functions\n",
"\n",
"def ordinary_least_squares(x, y):\n",
" \"\"\"Ordinary least squares estimator for linear regression.\n",
"\n",
" Args:\n",
" x (ndarray): design matrix of shape (n_samples, n_regressors)\n",
" y (ndarray): vector of measurements of shape (n_samples)\n",
"\n",
" Returns:\n",
" ndarray: estimated parameter values of shape (n_regressors)\n",
" \"\"\"\n",
"\n",
" return np.linalg.inv(x.T @ x) @ x.T @ y\n",
"\n",
"\n",
"def make_design_matrix(x, order):\n",
" \"\"\"Create the design matrix of inputs for use in polynomial regression\n",
"\n",
" Args:\n",
" x (ndarray): input vector of shape (n_samples)\n",
" order (scalar): polynomial regression order\n",
"\n",
" Returns:\n",
" ndarray: design matrix for polynomial regression of shape (samples, order+1)\n",
" \"\"\"\n",
"\n",
" # Broadcast to shape (n x 1) so dimensions work\n",
" if x.ndim == 1:\n",
" x = x[:, None]\n",
"\n",
" #if x has more than one feature, we don't want multiple columns of ones so we assign\n",
" # x^0 here\n",
" design_matrix = np.ones((x.shape[0],1))\n",
"\n",
" # Loop through rest of degrees and stack columns\n",
" for degree in range(1, order+1):\n",
" design_matrix = np.hstack((design_matrix, x**degree))\n",
"\n",
" return design_matrix\n",
"\n",
"\n",
"def solve_poly_reg(x, y, max_order):\n",
" \"\"\"Fit a polynomial regression model for each order 0 through max_order.\n",
"\n",
" Args:\n",
" x (ndarray): input vector of shape (n_samples)\n",
" y (ndarray): vector of measurements of shape (n_samples)\n",
" max_order (scalar): max order for polynomial fits\n",
"\n",
" Returns:\n",
" dict: fitted weights for each polynomial model (dict key is order)\n",
" \"\"\"\n",
"\n",
" # Create a dictionary with polynomial order as keys, and np array of theta\n",
" # (weights) as the values\n",
" theta_hats = {}\n",
"\n",
" # Loop over polynomial orders from 0 through max_order\n",
" for order in range(max_order+1):\n",
"\n",
" X = make_design_matrix(x, order)\n",
" this_theta = ordinary_least_squares(X, y)\n",
"\n",
" theta_hats[order] = this_theta\n",
"\n",
" return theta_hats"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 1: Train vs test data\n",
"\n",
"*Estimated timing to here from start of tutorial: 8 min*\n",
"\n",
" The data used for the fitting procedure for a given model is the **training data**. In tutorial 4, we computed MSE on the training data of our polynomial regression models and compared training MSE across models. An additional important type of data is **test data**. This is held-out data that is not used (in any way) during the fitting procedure. When fitting models, we often want to consider both the train error (the quality of prediction on the training data) and the test error (the quality of prediction on the test data) as we will see in the next section.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 1: Bias Variance Tradeoff\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 1: Bias Variance Tradeoff\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'NcUH_seBcVw'), ('Bilibili', 'BV1dg4y1v7wP')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Bias_Variance_Tradeoff_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We will generate some noisy data for use in this tutorial using a similar process as in Tutorial 4. However, now we will also generate test data. We want to see how our model generalizes beyond the range of values seen in the training phase. To accomplish this, we will generate x from a wider range of values ([-3, 3]). We then plot the train and test data together."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute this cell to simulate both training and test data\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute this cell to simulate both training and test data\n",
"\n",
"### Generate training data\n",
"np.random.seed(0)\n",
"n_train_samples = 50\n",
"x_train = np.random.uniform(-2, 2.5, n_train_samples) # sample from a uniform distribution over [-2, 2.5)\n",
"noise = np.random.randn(n_train_samples) # sample from a standard normal distribution\n",
"y_train = x_train**2 - x_train - 2 + noise\n",
"\n",
"### Generate testing data\n",
"n_test_samples = 20\n",
"x_test = np.random.uniform(-3, 3, n_test_samples) # sample from a uniform distribution over [-2, 2.5)\n",
"noise = np.random.randn(n_test_samples) # sample from a standard normal distribution\n",
"y_test = x_test**2 - x_test - 2 + noise\n",
"\n",
"## Plot both train and test data\n",
"fig, ax = plt.subplots()\n",
"plt.title('Training & Test Data')\n",
"plt.plot(x_train, y_train, '.', markersize=15, label='Training')\n",
"plt.plot(x_test, y_test, 'g+', markersize=15, label='Test')\n",
"plt.legend()\n",
"plt.xlabel('x')\n",
"plt.ylabel('y');"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 2: Bias-variance tradeoff\n",
"\n",
"*Estimated timing to here from start of tutorial: 10 min*\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial 5: Model Selection: Bias-variance trade-off\n",
"\n",
"**Week 1, Day 2: Model Fitting**\n",
"\n",
"**By Neuromatch Academy**\n",
"\n",
"**Content creators**: Pierre-Étienne Fiquet, Anqi Wu, Alex Hyafil with help from Ella Batty\n",
"\n",
"**Content reviewers**: Lina Teichmann, Patrick Mineault, Michael Waskom\n",
"\n",
"**Production editors:** Spiros Chavlis"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Tutorial Objectives\n",
"\n",
"*Estimated timing of tutorial: 25 minutes*\n",
"\n",
"This is Tutorial 5 of a series on fitting models to data. We start with simple linear regression, using least squares optimization (Tutorial 1) and Maximum Likelihood Estimation (Tutorial 2). We will use bootstrapping to build confidence intervals around the inferred linear model parameters (Tutorial 3). We'll finish our exploration of regression models by generalizing to multiple linear regression and polynomial regression (Tutorial 4). We end by learning how to choose between these various models. We discuss the bias-variance trade-off (Tutorial 5) and Cross Validation for model selection (Tutorial 6).\n",
"\n",
"In this tutorial, we will learn about the bias-variance tradeoff and see it in action using polynomial regression models.\n",
"\n",
"Tutorial objectives:\n",
"\n",
"* Understand difference between test and train data\n",
"* Compare train and test error for models of varying complexity\n",
"* Understand how bias-variance tradeoff relates to what model we choose"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @markdown\n",
"from IPython.display import IFrame\n",
"from ipywidgets import widgets\n",
"out = widgets.Output()\n",
"with out:\n",
" print(f\"If you want to download the slides: https://osf.io/download/2mkq4/\")\n",
" display(IFrame(src=f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/2mkq4/?direct%26mode=render%26action=download%26mode=render\", width=730, height=410))\n",
"display(out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Setup"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install and import feedback gadget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install and import feedback gadget\n",
"\n",
"!pip3 install vibecheck datatops --quiet\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
" return DatatopsContentReviewContainer(\n",
" \"\", # No text prompt\n",
" notebook_section,\n",
" {\n",
" \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
" \"name\": \"neuromatch_cn\",\n",
" \"user_key\": \"y1x3mpx5\",\n",
" },\n",
" ).render()\n",
"\n",
"\n",
"feedback_prefix = \"W1D2_T5\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "both",
"execution": {}
},
"outputs": [],
"source": [
"# Imports\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Figure Settings\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Figure Settings\n",
"import logging\n",
"logging.getLogger('matplotlib.font_manager').disabled = True\n",
"\n",
"%config InlineBackend.figure_format = 'retina'\n",
"plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Plotting Functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Plotting Functions\n",
"\n",
"def plot_MSE_poly_fits(mse_train, mse_test, max_order):\n",
" \"\"\"\n",
" Plot the MSE values for various orders of polynomial fits on the same bar\n",
" graph\n",
"\n",
" Args:\n",
" mse_train (ndarray): an array of MSE values for each order of polynomial fit\n",
" over the training data\n",
" mse_test (ndarray): an array of MSE values for each order of polynomial fit\n",
" over the test data\n",
" max_order (scalar): max order of polynomial fit\n",
" \"\"\"\n",
" fig, ax = plt.subplots()\n",
" width = .35\n",
"\n",
" ax.bar(np.arange(max_order + 1) - width / 2,\n",
" mse_train, width, label=\"train MSE\")\n",
" ax.bar(np.arange(max_order + 1) + width / 2,\n",
" mse_test , width, label=\"test MSE\")\n",
"\n",
" ax.legend()\n",
" ax.set(xlabel='Polynomial order', ylabel='MSE',\n",
" title='Comparing polynomial fits')\n",
" plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Helper functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Helper functions\n",
"\n",
"def ordinary_least_squares(x, y):\n",
" \"\"\"Ordinary least squares estimator for linear regression.\n",
"\n",
" Args:\n",
" x (ndarray): design matrix of shape (n_samples, n_regressors)\n",
" y (ndarray): vector of measurements of shape (n_samples)\n",
"\n",
" Returns:\n",
" ndarray: estimated parameter values of shape (n_regressors)\n",
" \"\"\"\n",
"\n",
" return np.linalg.inv(x.T @ x) @ x.T @ y\n",
"\n",
"\n",
"def make_design_matrix(x, order):\n",
" \"\"\"Create the design matrix of inputs for use in polynomial regression\n",
"\n",
" Args:\n",
" x (ndarray): input vector of shape (n_samples)\n",
" order (scalar): polynomial regression order\n",
"\n",
" Returns:\n",
" ndarray: design matrix for polynomial regression of shape (samples, order+1)\n",
" \"\"\"\n",
"\n",
" # Broadcast to shape (n x 1) so dimensions work\n",
" if x.ndim == 1:\n",
" x = x[:, None]\n",
"\n",
" #if x has more than one feature, we don't want multiple columns of ones so we assign\n",
" # x^0 here\n",
" design_matrix = np.ones((x.shape[0],1))\n",
"\n",
" # Loop through rest of degrees and stack columns\n",
" for degree in range(1, order+1):\n",
" design_matrix = np.hstack((design_matrix, x**degree))\n",
"\n",
" return design_matrix\n",
"\n",
"\n",
"def solve_poly_reg(x, y, max_order):\n",
" \"\"\"Fit a polynomial regression model for each order 0 through max_order.\n",
"\n",
" Args:\n",
" x (ndarray): input vector of shape (n_samples)\n",
" y (ndarray): vector of measurements of shape (n_samples)\n",
" max_order (scalar): max order for polynomial fits\n",
"\n",
" Returns:\n",
" dict: fitted weights for each polynomial model (dict key is order)\n",
" \"\"\"\n",
"\n",
" # Create a dictionary with polynomial order as keys, and np array of theta\n",
" # (weights) as the values\n",
" theta_hats = {}\n",
"\n",
" # Loop over polynomial orders from 0 through max_order\n",
" for order in range(max_order+1):\n",
"\n",
" X = make_design_matrix(x, order)\n",
" this_theta = ordinary_least_squares(X, y)\n",
"\n",
" theta_hats[order] = this_theta\n",
"\n",
" return theta_hats"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 1: Train vs test data\n",
"\n",
"*Estimated timing to here from start of tutorial: 8 min*\n",
"\n",
" The data used for the fitting procedure for a given model is the **training data**. In tutorial 4, we computed MSE on the training data of our polynomial regression models and compared training MSE across models. An additional important type of data is **test data**. This is held-out data that is not used (in any way) during the fitting procedure. When fitting models, we often want to consider both the train error (the quality of prediction on the training data) and the test error (the quality of prediction on the test data) as we will see in the next section.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 1: Bias Variance Tradeoff\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 1: Bias Variance Tradeoff\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'NcUH_seBcVw'), ('Bilibili', 'BV1dg4y1v7wP')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Bias_Variance_Tradeoff_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We will generate some noisy data for use in this tutorial using a similar process as in Tutorial 4. However, now we will also generate test data. We want to see how our model generalizes beyond the range of values seen in the training phase. To accomplish this, we will generate x from a wider range of values ([-3, 3]). We then plot the train and test data together."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute this cell to simulate both training and test data\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute this cell to simulate both training and test data\n",
"\n",
"### Generate training data\n",
"np.random.seed(0)\n",
"n_train_samples = 50\n",
"x_train = np.random.uniform(-2, 2.5, n_train_samples) # sample from a uniform distribution over [-2, 2.5)\n",
"noise = np.random.randn(n_train_samples) # sample from a standard normal distribution\n",
"y_train = x_train**2 - x_train - 2 + noise\n",
"\n",
"### Generate testing data\n",
"n_test_samples = 20\n",
"x_test = np.random.uniform(-3, 3, n_test_samples) # sample from a uniform distribution over [-2, 2.5)\n",
"noise = np.random.randn(n_test_samples) # sample from a standard normal distribution\n",
"y_test = x_test**2 - x_test - 2 + noise\n",
"\n",
"## Plot both train and test data\n",
"fig, ax = plt.subplots()\n",
"plt.title('Training & Test Data')\n",
"plt.plot(x_train, y_train, '.', markersize=15, label='Training')\n",
"plt.plot(x_test, y_test, 'g+', markersize=15, label='Test')\n",
"plt.legend()\n",
"plt.xlabel('x')\n",
"plt.ylabel('y');"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 2: Bias-variance tradeoff\n",
"\n",
"*Estimated timing to here from start of tutorial: 10 min*\n",
"\n",
"\n",
" Click here for text recap of video
\n",
"\n",
"Finding a good model can be difficult. One of the most important concepts to keep in mind when modeling is the **bias-variance tradeoff**.\n",
"\n",
"**Bias** is the difference between the prediction of the model and the corresponding true output variables you are trying to predict. Models with high bias will not fit the training data well since the predictions are quite different from the true data. These high bias models are overly simplified - they do not have enough parameters and complexity to accurately capture the patterns in the data and are thus **underfitting**.\n",
"\n",
"\n",
"**Variance** refers to the variability of model predictions for a given input. Essentially, do the model predictions change a lot with changes in the exact training data used? Models with high variance are highly dependent on the exact training data used - they will not generalize well to test data. These high variance models are **overfitting** to the data.\n",
"\n",
"In essence:\n",
"\n",
"* High bias, low variance models have high train and test error.\n",
"* Low bias, high variance models have low train error, high test error\n",
"* Low bias, low variance models have low train and test error\n",
"\n",
"\n",
"As we can see from this list, we ideally want low bias and low variance models! These goals can be in conflict though - models with enough complexity to have low bias also tend to overfit and depend on the training data more. We need to decide on the correct tradeoff.\n",
"\n",
"In this section, we will see the bias-variance tradeoff in action with polynomial regression models of different orders.\n",
"\n",
" \n",
"\n",
"Graphical illustration of bias and variance.\n",
"(Source: http://scott.fortmann-roe.com/docs/BiasVariance.html)\n",
"\n",
"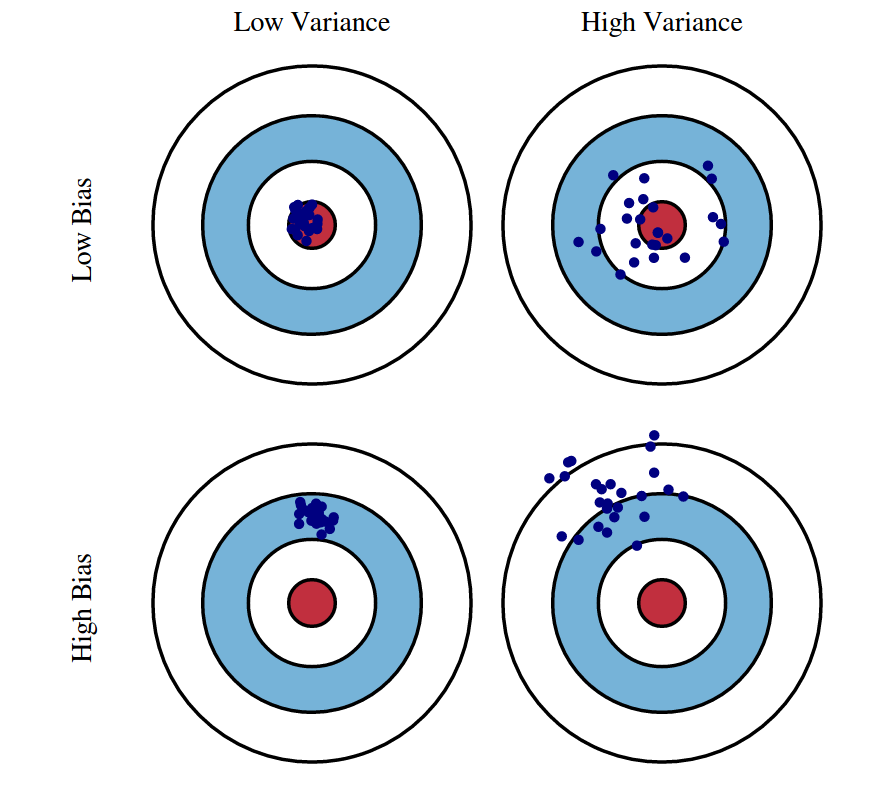"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We will first fit polynomial regression models of orders 0-5 on our simulated training data just as we did in Tutorial 4."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute this cell to estimate theta_hats\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute this cell to estimate theta_hats\n",
"max_order = 5\n",
"theta_hats = solve_poly_reg(x_train, y_train, max_order)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Coding Exercise 2: Compute and compare train vs test error\n",
"\n",
"We will use MSE as our error metric again. Compute MSE on training data ($x_{train},y_{train}$) and test data ($x_{test}, y_{test}$) for each polynomial regression model (orders 0-5). Since you already developed code in T4 Exercise 4 for making design matrices and evaluating fit polynomials, we have ported that here into the functions `make_design_matrix` and `evaluate_poly_reg` for your use.\n",
"\n",
"*Please think about it after completing the exercise before reading the following text! Do you think the order 0 model has high or low bias? High or low variance? How about the order 5 model?*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute this cell for function `evalute_poly_reg`\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute this cell for function `evalute_poly_reg`\n",
"\n",
"def evaluate_poly_reg(x, y, theta_hats, max_order):\n",
" \"\"\" Evaluates MSE of polynomial regression models on data\n",
"\n",
" Args:\n",
" x (ndarray): input vector of shape (n_samples)\n",
" y (ndarray): vector of measurements of shape (n_samples)\n",
" theta_hats (dict): fitted weights for each polynomial model (dict key is order)\n",
" max_order (scalar): max order of polynomial fit\n",
"\n",
" Returns\n",
" (ndarray): mean squared error for each order, shape (max_order)\n",
" \"\"\"\n",
"\n",
" mse = np.zeros((max_order + 1))\n",
" for order in range(0, max_order + 1):\n",
" X_design = make_design_matrix(x, order)\n",
" y_hat = np.dot(X_design, theta_hats[order])\n",
" residuals = y - y_hat\n",
" mse[order] = np.mean(residuals ** 2)\n",
"\n",
" return mse"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def compute_mse(x_train, x_test, y_train, y_test, theta_hats, max_order):\n",
" \"\"\"Compute MSE on training data and test data.\n",
"\n",
" Args:\n",
" x_train(ndarray): training data input vector of shape (n_samples)\n",
" x_test(ndarray): test data input vector of shape (n_samples)\n",
" y_train(ndarray): training vector of measurements of shape (n_samples)\n",
" y_test(ndarray): test vector of measurements of shape (n_samples)\n",
" theta_hats(dict): fitted weights for each polynomial model (dict key is order)\n",
" max_order (scalar): max order of polynomial fit\n",
"\n",
" Returns:\n",
" ndarray, ndarray: MSE error on training data and test data for each order\n",
" \"\"\"\n",
"\n",
" #######################################################\n",
" ## TODO for students: calculate mse error for both sets\n",
" ## Hint: look back at tutorial 5 where we calculated MSE\n",
" # Fill out function and remove\n",
" raise NotImplementedError(\"Student exercise: calculate mse for train and test set\")\n",
" #######################################################\n",
"\n",
" mse_train = ...\n",
" mse_test = ...\n",
"\n",
" return mse_train, mse_test\n",
"\n",
"\n",
"# Compute train and test MSE\n",
"mse_train, mse_test = compute_mse(x_train, x_test, y_train, y_test, theta_hats, max_order)\n",
"\n",
"# Visualize\n",
"plot_MSE_poly_fits(mse_train, mse_test, max_order)"
]
},
{
"cell_type": "markdown",
"metadata": {
"cellView": "both",
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/course-content/tree/main/tutorials/W1D2_ModelFitting/solutions/W1D2_Tutorial5_Solution_bb5f169f.py)\n",
"\n",
"*Example output:*\n",
"\n",
"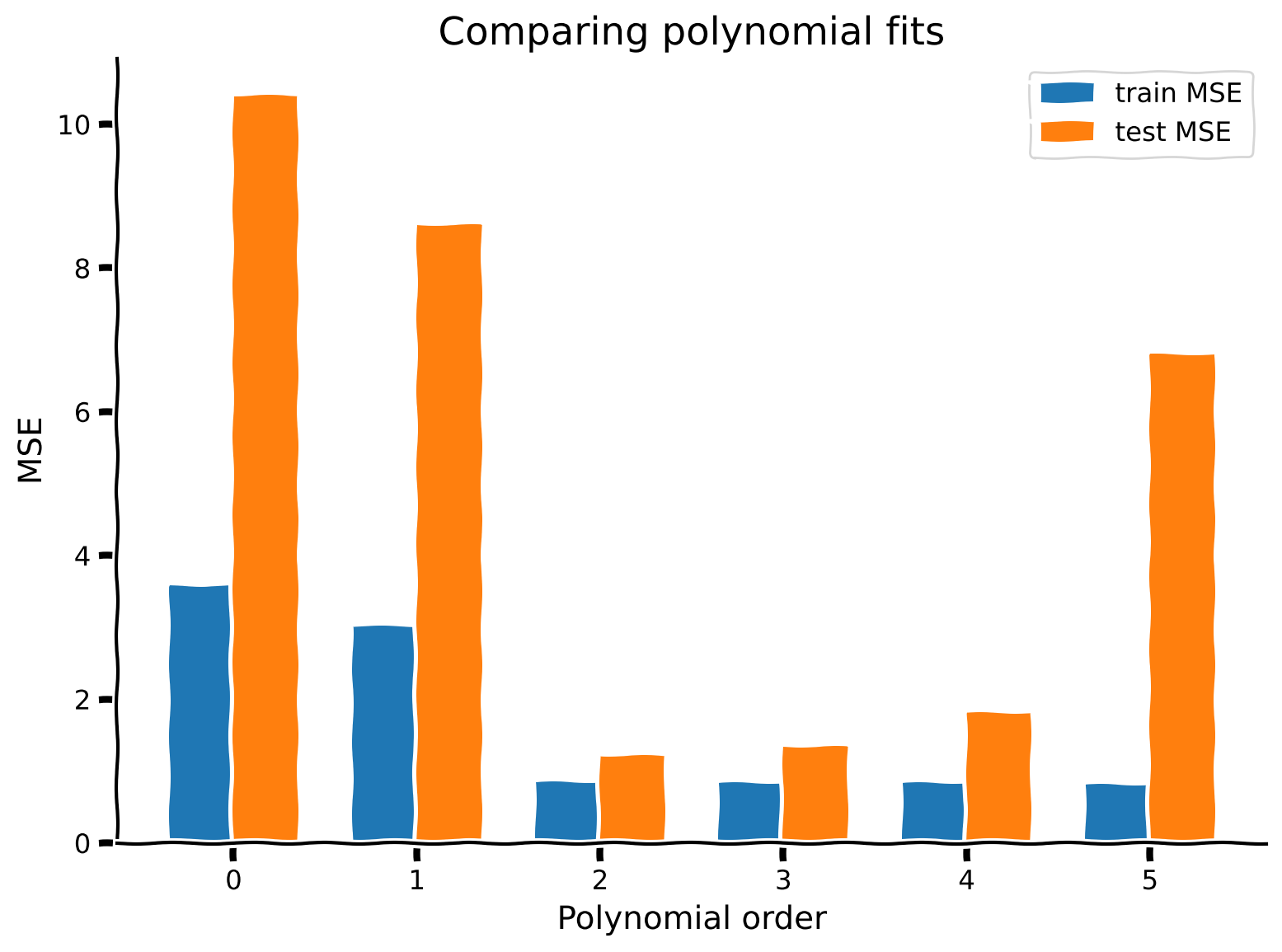 \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Compute_train_vs_test_error_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"As we can see from the plot above, more complex models (higher order polynomials) have lower MSE for training data. The overly simplified models (orders 0 and 1) have high MSE on the training data. As we add complexity to the model, we go from high bias to low bias.\n",
"\n",
"The MSE on test data follows a different pattern. The best test MSE is for an order 2 model - this makes sense as the data was generated with an order 2 model. Both simpler models and more complex models have higher test MSE.\n",
"\n",
"So to recap:\n",
"\n",
"Order 0 model: High bias, low variance\n",
"\n",
"Order 5 model: Low bias, high variance\n",
"\n",
"Order 2 model: Just right, low bias, low variance\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Summary\n",
"\n",
"*Estimated timing of tutorial: 25 minutes*\n",
"\n",
"- Training data is the data used for fitting, test data is held-out data.\n",
"- We need to strike the right balance between bias and variance. Ideally we want to find a model with optimal model complexity that has both low bias and low variance\n",
" - Too complex models have low bias and high variance.\n",
" - Too simple models have high bias and low variance."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Note**\n",
" - Bias and variance are very important concepts in modern machine learning, but it has recently been observed that they do not necessarily trade off (see for example the phenomenon and theory of \"double descent\")\n",
"\n",
"**Further readings:**\n",
"- [The elements of statistical learning](https://web.stanford.edu/~hastie/ElemStatLearn/) by Hastie, Tibshirani and Friedman"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Bonus\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus Exercise: Proof of bias-variance decomposition\n",
"\n",
"Prove the bias-variance decomposition for MSE\n",
"\n",
"\\begin{equation}\n",
"\\mathbb{E}_{x}\\left[\\left(y-\\hat{y}(x ; \\theta)\\right)^{2}\\right]=\\left(\\operatorname{Bias}_{x}[\\hat{y}(x ; \\theta)]\\right)^{2}+\\operatorname{Var}_{x}[\\hat{y}(x ; \\theta)]+\\sigma^{2}\n",
"\\end{equation}\n",
"\n",
"where\n",
"\n",
"\\begin{equation}\n",
"\\operatorname{Bias}_{x}[\\hat{y}(x ; \\theta)]=\\mathbb{E}_{x}[\\hat{y}(x ; \\theta)]-y\n",
"\\end{equation}\n",
"\n",
"and\n",
"\n",
"\\begin{equation}\n",
"\\operatorname{Var}_{x}[\\hat{y}(x ; \\theta)]=\\mathbb{E}_{x}\\left[\\hat{y}(x ; \\theta)^{2}\\right]-\\mathrm{E}_{x}[\\hat{y}(x ; \\theta)]^{2}\n",
"\\end{equation}\n",
"\n",
"\n",
"
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Compute_train_vs_test_error_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"As we can see from the plot above, more complex models (higher order polynomials) have lower MSE for training data. The overly simplified models (orders 0 and 1) have high MSE on the training data. As we add complexity to the model, we go from high bias to low bias.\n",
"\n",
"The MSE on test data follows a different pattern. The best test MSE is for an order 2 model - this makes sense as the data was generated with an order 2 model. Both simpler models and more complex models have higher test MSE.\n",
"\n",
"So to recap:\n",
"\n",
"Order 0 model: High bias, low variance\n",
"\n",
"Order 5 model: Low bias, high variance\n",
"\n",
"Order 2 model: Just right, low bias, low variance\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Summary\n",
"\n",
"*Estimated timing of tutorial: 25 minutes*\n",
"\n",
"- Training data is the data used for fitting, test data is held-out data.\n",
"- We need to strike the right balance between bias and variance. Ideally we want to find a model with optimal model complexity that has both low bias and low variance\n",
" - Too complex models have low bias and high variance.\n",
" - Too simple models have high bias and low variance."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Note**\n",
" - Bias and variance are very important concepts in modern machine learning, but it has recently been observed that they do not necessarily trade off (see for example the phenomenon and theory of \"double descent\")\n",
"\n",
"**Further readings:**\n",
"- [The elements of statistical learning](https://web.stanford.edu/~hastie/ElemStatLearn/) by Hastie, Tibshirani and Friedman"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Bonus\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus Exercise: Proof of bias-variance decomposition\n",
"\n",
"Prove the bias-variance decomposition for MSE\n",
"\n",
"\\begin{equation}\n",
"\\mathbb{E}_{x}\\left[\\left(y-\\hat{y}(x ; \\theta)\\right)^{2}\\right]=\\left(\\operatorname{Bias}_{x}[\\hat{y}(x ; \\theta)]\\right)^{2}+\\operatorname{Var}_{x}[\\hat{y}(x ; \\theta)]+\\sigma^{2}\n",
"\\end{equation}\n",
"\n",
"where\n",
"\n",
"\\begin{equation}\n",
"\\operatorname{Bias}_{x}[\\hat{y}(x ; \\theta)]=\\mathbb{E}_{x}[\\hat{y}(x ; \\theta)]-y\n",
"\\end{equation}\n",
"\n",
"and\n",
"\n",
"\\begin{equation}\n",
"\\operatorname{Var}_{x}[\\hat{y}(x ; \\theta)]=\\mathbb{E}_{x}\\left[\\hat{y}(x ; \\theta)^{2}\\right]-\\mathrm{E}_{x}[\\hat{y}(x ; \\theta)]^{2}\n",
"\\end{equation}\n",
"\n",
"\n",
"\n",
" Click here for a hint
\n",
"\n",
"Use the equation:\n",
"\n",
"\\begin{equation}\n",
"\\operatorname{Var}[X]=\\mathbb{E}\\left[X^{2}\\right]-(\\mathrm{E}[X])^{2}\n",
"\\end{equation}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Proof_bias_variance_for_MSE_Bonus_Exercise\")"
]
}
],
"metadata": {
"colab": {
"collapsed_sections": [],
"include_colab_link": true,
"name": "W1D2_Tutorial5",
"provenance": [],
"toc_visible": true
},
"kernel": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.21"
},
"toc-autonumbering": true
},
"nbformat": 4,
"nbformat_minor": 0
}