{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {},
"id": "view-in-github"
},
"source": [
"
 "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial 2: Statistical Inference\n",
"\n",
"**Week 0, Day 5: Probability & Statistics**\n",
"\n",
"**By Neuromatch Academy**\n",
"\n",
"**Content creators:** Ulrik Beierholm\n",
"\n",
"**Content reviewers:** Natalie Schaworonkow, Keith van Antwerp, Anoop Kulkarni, Pooya Pakarian, Hyosub Kim\n",
"\n",
"**Production editors:** Ethan Cheng, Ella Batty"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"#Tutorial Objectives\n",
"\n",
"This tutorial builds on Tutorial 1 by explaining how to do inference through inverting the generative process.\n",
"\n",
"By completing the exercises in this tutorial, you should:\n",
"* understand what the likelihood function is, and have some intuition of why it is important\n",
"* know how to summarise the Gaussian distribution using mean and variance\n",
"* know how to maximise a likelihood function\n",
"* be able to do simple inference in both classical and Bayesian ways\n",
"* (Optional) understand how Bayes Net can be used to model causal relationships"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Setup"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install and import feedback gadget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install and import feedback gadget\n",
"\n",
"!pip3 install vibecheck datatops --quiet\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
" return DatatopsContentReviewContainer(\n",
" \"\", # No text prompt\n",
" notebook_section,\n",
" {\n",
" \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
" \"name\": \"neuromatch-precourse\",\n",
" \"user_key\": \"8zxfvwxw\",\n",
" },\n",
" ).render()\n",
"\n",
"\n",
"feedback_prefix = \"W0D5_T2\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "code",
"execution": {}
},
"outputs": [],
"source": [
"# Imports\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"import scipy as sp\n",
"from scipy.stats import norm\n",
"from numpy.random import default_rng # a default random number generator"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Figure settings\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Figure settings\n",
"import logging\n",
"logging.getLogger('matplotlib.font_manager').disabled = True\n",
"import ipywidgets as widgets # interactive display\n",
"from ipywidgets import interact, fixed, HBox, Layout, VBox, interactive, Label, interact_manual\n",
"%config InlineBackend.figure_format = 'retina'\n",
"plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/content-creation/main/nma.mplstyle\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Plotting functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Plotting functions\n",
"\n",
"def plot_hist(data, xlabel, figtitle = None, num_bins = None):\n",
" \"\"\" Plot the given data as a histogram.\n",
"\n",
" Args:\n",
" data (ndarray): array with data to plot as histogram\n",
" xlabel (str): label of x-axis\n",
" figtitle (str): title of histogram plot (default is no title)\n",
" num_bins (int): number of bins for histogram (default is 10)\n",
"\n",
" Returns:\n",
" count (ndarray): number of samples in each histogram bin\n",
" bins (ndarray): center of each histogram bin\n",
" \"\"\"\n",
" fig, ax = plt.subplots()\n",
" ax.set_xlabel(xlabel)\n",
" ax.set_ylabel('Count')\n",
" if num_bins is not None:\n",
" count, bins, _ = plt.hist(data, max(data), bins=num_bins)\n",
" else:\n",
" count, bins, _ = plt.hist(data, max(data)) # 10 bins default\n",
" if figtitle is not None:\n",
" fig.suptitle(figtitle, size=16)\n",
" plt.show()\n",
" return count, bins\n",
"\n",
"\n",
"def plot_gaussian_samples_true(samples, xspace, mu, sigma, xlabel, ylabel):\n",
" \"\"\" Plot a histogram of the data samples on the same plot as the gaussian\n",
" distribution specified by the give mu and sigma values.\n",
"\n",
" Args:\n",
" samples (ndarray): data samples for gaussian distribution\n",
" xspace (ndarray): x values to sample from normal distribution\n",
" mu (scalar): mean parameter of normal distribution\n",
" sigma (scalar): variance parameter of normal distribution\n",
" xlabel (str): the label of the x-axis of the histogram\n",
" ylabel (str): the label of the y-axis of the histogram\n",
"\n",
" Returns:\n",
" Nothing.\n",
" \"\"\"\n",
" fig, ax = plt.subplots()\n",
" ax.set_xlabel(xlabel)\n",
" ax.set_ylabel(ylabel)\n",
" # num_samples = samples.shape[0]\n",
"\n",
" count, bins, _ = plt.hist(samples, density=True) # probability density function\n",
"\n",
" plt.plot(xspace, norm.pdf(xspace, mu, sigma), 'r-')\n",
" plt.show()\n",
"\n",
"\n",
"def plot_likelihoods(likelihoods, mean_vals, variance_vals):\n",
" \"\"\" Plot the likelihood values on a heatmap plot where the x and y axes match\n",
" the mean and variance parameter values the likelihoods were computed for.\n",
"\n",
" Args:\n",
" likelihoods (ndarray): array of computed likelihood values\n",
" mean_vals (ndarray): array of mean parameter values for which the\n",
" likelihood was computed\n",
" variance_vals (ndarray): array of variance parameter values for which the\n",
" likelihood was computed\n",
"\n",
" Returns:\n",
" Nothing.\n",
" \"\"\"\n",
" fig, ax = plt.subplots()\n",
" im = ax.imshow(likelihoods)\n",
"\n",
" cbar = ax.figure.colorbar(im, ax=ax)\n",
" cbar.ax.set_ylabel('log likelihood', rotation=-90, va=\"bottom\")\n",
"\n",
" ax.set_xticks(np.arange(len(mean_vals)))\n",
" ax.set_yticks(np.arange(len(variance_vals)))\n",
" ax.set_xticklabels(mean_vals)\n",
" ax.set_yticklabels(variance_vals)\n",
" ax.set_xlabel('Mean')\n",
" ax.set_ylabel('Variance')\n",
" plt.show()\n",
"\n",
"\n",
"def posterior_plot(x, likelihood=None, prior=None,\n",
" posterior_pointwise=None, ax=None):\n",
" \"\"\"\n",
" Plots normalized Gaussian distributions and posterior.\n",
"\n",
" Args:\n",
" x (numpy array of floats): points at which the likelihood has been evaluated\n",
" auditory (numpy array of floats): normalized probabilities for auditory likelihood evaluated at each `x`\n",
" visual (numpy array of floats): normalized probabilities for visual likelihood evaluated at each `x`\n",
" posterior (numpy array of floats): normalized probabilities for the posterior evaluated at each `x`\n",
" ax: Axis in which to plot. If None, create new axis.\n",
"\n",
" Returns:\n",
" Nothing.\n",
" \"\"\"\n",
" if likelihood is None:\n",
" likelihood = np.zeros_like(x)\n",
"\n",
" if prior is None:\n",
" prior = np.zeros_like(x)\n",
"\n",
" if posterior_pointwise is None:\n",
" posterior_pointwise = np.zeros_like(x)\n",
"\n",
" if ax is None:\n",
" fig, ax = plt.subplots()\n",
"\n",
" ax.plot(x, likelihood, '-C1', linewidth=2, label='Auditory')\n",
" ax.plot(x, prior, '-C0', linewidth=2, label='Visual')\n",
" ax.plot(x, posterior_pointwise, '-C2', linewidth=2, label='Posterior')\n",
" ax.legend()\n",
" ax.set_ylabel('Probability')\n",
" ax.set_xlabel('Orientation (Degrees)')\n",
" plt.show()\n",
"\n",
" return ax\n",
"\n",
"\n",
"def plot_classical_vs_bayesian_normal(num_points, mu_classic, var_classic,\n",
" mu_bayes, var_bayes):\n",
" \"\"\" Helper function to plot optimal normal distribution parameters for varying\n",
" observed sample sizes using both classic and Bayesian inference methods.\n",
"\n",
" Args:\n",
" num_points (int): max observed sample size to perform inference with\n",
" mu_classic (ndarray): estimated mean parameter for each observed sample size\n",
" using classic inference method\n",
" var_classic (ndarray): estimated variance parameter for each observed sample size\n",
" using classic inference method\n",
" mu_bayes (ndarray): estimated mean parameter for each observed sample size\n",
" using Bayesian inference method\n",
" var_bayes (ndarray): estimated variance parameter for each observed sample size\n",
" using Bayesian inference method\n",
"\n",
" Returns:\n",
" Nothing.\n",
" \"\"\"\n",
" xspace = np.linspace(0, num_points, num_points)\n",
" fig, ax = plt.subplots()\n",
" ax.set_xlabel('n data points')\n",
" ax.set_ylabel('mu')\n",
" plt.plot(xspace, mu_classic,'r-', label=\"Classical\")\n",
" plt.plot(xspace, mu_bayes,'b-', label=\"Bayes\")\n",
" plt.legend()\n",
" plt.show()\n",
"\n",
" fig, ax = plt.subplots()\n",
" ax.set_xlabel('n data points')\n",
" ax.set_ylabel('sigma^2')\n",
" plt.plot(xspace, var_classic,'r-', label=\"Classical\")\n",
" plt.plot(xspace, var_bayes,'b-', label=\"Bayes\")\n",
" plt.legend()\n",
" plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
" ---\n",
"# Section 1: Basic probability"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 1.1: Basic probability theory"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Video 1: Basic Probability\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 1: Basic Probability\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'SL0_6rw8zrM'), ('Bilibili', 'BV1bw411o7HR')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Basic_Probability_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"This video covers basic probability theory, including complementary probability, conditional probability, joint probability, and marginalisation.\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial 2: Statistical Inference\n",
"\n",
"**Week 0, Day 5: Probability & Statistics**\n",
"\n",
"**By Neuromatch Academy**\n",
"\n",
"**Content creators:** Ulrik Beierholm\n",
"\n",
"**Content reviewers:** Natalie Schaworonkow, Keith van Antwerp, Anoop Kulkarni, Pooya Pakarian, Hyosub Kim\n",
"\n",
"**Production editors:** Ethan Cheng, Ella Batty"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"#Tutorial Objectives\n",
"\n",
"This tutorial builds on Tutorial 1 by explaining how to do inference through inverting the generative process.\n",
"\n",
"By completing the exercises in this tutorial, you should:\n",
"* understand what the likelihood function is, and have some intuition of why it is important\n",
"* know how to summarise the Gaussian distribution using mean and variance\n",
"* know how to maximise a likelihood function\n",
"* be able to do simple inference in both classical and Bayesian ways\n",
"* (Optional) understand how Bayes Net can be used to model causal relationships"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Setup"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install and import feedback gadget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Install and import feedback gadget\n",
"\n",
"!pip3 install vibecheck datatops --quiet\n",
"\n",
"from vibecheck import DatatopsContentReviewContainer\n",
"def content_review(notebook_section: str):\n",
" return DatatopsContentReviewContainer(\n",
" \"\", # No text prompt\n",
" notebook_section,\n",
" {\n",
" \"url\": \"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab\",\n",
" \"name\": \"neuromatch-precourse\",\n",
" \"user_key\": \"8zxfvwxw\",\n",
" },\n",
" ).render()\n",
"\n",
"\n",
"feedback_prefix = \"W0D5_T2\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "code",
"execution": {}
},
"outputs": [],
"source": [
"# Imports\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"import scipy as sp\n",
"from scipy.stats import norm\n",
"from numpy.random import default_rng # a default random number generator"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Figure settings\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Figure settings\n",
"import logging\n",
"logging.getLogger('matplotlib.font_manager').disabled = True\n",
"import ipywidgets as widgets # interactive display\n",
"from ipywidgets import interact, fixed, HBox, Layout, VBox, interactive, Label, interact_manual\n",
"%config InlineBackend.figure_format = 'retina'\n",
"plt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/content-creation/main/nma.mplstyle\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Plotting functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Plotting functions\n",
"\n",
"def plot_hist(data, xlabel, figtitle = None, num_bins = None):\n",
" \"\"\" Plot the given data as a histogram.\n",
"\n",
" Args:\n",
" data (ndarray): array with data to plot as histogram\n",
" xlabel (str): label of x-axis\n",
" figtitle (str): title of histogram plot (default is no title)\n",
" num_bins (int): number of bins for histogram (default is 10)\n",
"\n",
" Returns:\n",
" count (ndarray): number of samples in each histogram bin\n",
" bins (ndarray): center of each histogram bin\n",
" \"\"\"\n",
" fig, ax = plt.subplots()\n",
" ax.set_xlabel(xlabel)\n",
" ax.set_ylabel('Count')\n",
" if num_bins is not None:\n",
" count, bins, _ = plt.hist(data, max(data), bins=num_bins)\n",
" else:\n",
" count, bins, _ = plt.hist(data, max(data)) # 10 bins default\n",
" if figtitle is not None:\n",
" fig.suptitle(figtitle, size=16)\n",
" plt.show()\n",
" return count, bins\n",
"\n",
"\n",
"def plot_gaussian_samples_true(samples, xspace, mu, sigma, xlabel, ylabel):\n",
" \"\"\" Plot a histogram of the data samples on the same plot as the gaussian\n",
" distribution specified by the give mu and sigma values.\n",
"\n",
" Args:\n",
" samples (ndarray): data samples for gaussian distribution\n",
" xspace (ndarray): x values to sample from normal distribution\n",
" mu (scalar): mean parameter of normal distribution\n",
" sigma (scalar): variance parameter of normal distribution\n",
" xlabel (str): the label of the x-axis of the histogram\n",
" ylabel (str): the label of the y-axis of the histogram\n",
"\n",
" Returns:\n",
" Nothing.\n",
" \"\"\"\n",
" fig, ax = plt.subplots()\n",
" ax.set_xlabel(xlabel)\n",
" ax.set_ylabel(ylabel)\n",
" # num_samples = samples.shape[0]\n",
"\n",
" count, bins, _ = plt.hist(samples, density=True) # probability density function\n",
"\n",
" plt.plot(xspace, norm.pdf(xspace, mu, sigma), 'r-')\n",
" plt.show()\n",
"\n",
"\n",
"def plot_likelihoods(likelihoods, mean_vals, variance_vals):\n",
" \"\"\" Plot the likelihood values on a heatmap plot where the x and y axes match\n",
" the mean and variance parameter values the likelihoods were computed for.\n",
"\n",
" Args:\n",
" likelihoods (ndarray): array of computed likelihood values\n",
" mean_vals (ndarray): array of mean parameter values for which the\n",
" likelihood was computed\n",
" variance_vals (ndarray): array of variance parameter values for which the\n",
" likelihood was computed\n",
"\n",
" Returns:\n",
" Nothing.\n",
" \"\"\"\n",
" fig, ax = plt.subplots()\n",
" im = ax.imshow(likelihoods)\n",
"\n",
" cbar = ax.figure.colorbar(im, ax=ax)\n",
" cbar.ax.set_ylabel('log likelihood', rotation=-90, va=\"bottom\")\n",
"\n",
" ax.set_xticks(np.arange(len(mean_vals)))\n",
" ax.set_yticks(np.arange(len(variance_vals)))\n",
" ax.set_xticklabels(mean_vals)\n",
" ax.set_yticklabels(variance_vals)\n",
" ax.set_xlabel('Mean')\n",
" ax.set_ylabel('Variance')\n",
" plt.show()\n",
"\n",
"\n",
"def posterior_plot(x, likelihood=None, prior=None,\n",
" posterior_pointwise=None, ax=None):\n",
" \"\"\"\n",
" Plots normalized Gaussian distributions and posterior.\n",
"\n",
" Args:\n",
" x (numpy array of floats): points at which the likelihood has been evaluated\n",
" auditory (numpy array of floats): normalized probabilities for auditory likelihood evaluated at each `x`\n",
" visual (numpy array of floats): normalized probabilities for visual likelihood evaluated at each `x`\n",
" posterior (numpy array of floats): normalized probabilities for the posterior evaluated at each `x`\n",
" ax: Axis in which to plot. If None, create new axis.\n",
"\n",
" Returns:\n",
" Nothing.\n",
" \"\"\"\n",
" if likelihood is None:\n",
" likelihood = np.zeros_like(x)\n",
"\n",
" if prior is None:\n",
" prior = np.zeros_like(x)\n",
"\n",
" if posterior_pointwise is None:\n",
" posterior_pointwise = np.zeros_like(x)\n",
"\n",
" if ax is None:\n",
" fig, ax = plt.subplots()\n",
"\n",
" ax.plot(x, likelihood, '-C1', linewidth=2, label='Auditory')\n",
" ax.plot(x, prior, '-C0', linewidth=2, label='Visual')\n",
" ax.plot(x, posterior_pointwise, '-C2', linewidth=2, label='Posterior')\n",
" ax.legend()\n",
" ax.set_ylabel('Probability')\n",
" ax.set_xlabel('Orientation (Degrees)')\n",
" plt.show()\n",
"\n",
" return ax\n",
"\n",
"\n",
"def plot_classical_vs_bayesian_normal(num_points, mu_classic, var_classic,\n",
" mu_bayes, var_bayes):\n",
" \"\"\" Helper function to plot optimal normal distribution parameters for varying\n",
" observed sample sizes using both classic and Bayesian inference methods.\n",
"\n",
" Args:\n",
" num_points (int): max observed sample size to perform inference with\n",
" mu_classic (ndarray): estimated mean parameter for each observed sample size\n",
" using classic inference method\n",
" var_classic (ndarray): estimated variance parameter for each observed sample size\n",
" using classic inference method\n",
" mu_bayes (ndarray): estimated mean parameter for each observed sample size\n",
" using Bayesian inference method\n",
" var_bayes (ndarray): estimated variance parameter for each observed sample size\n",
" using Bayesian inference method\n",
"\n",
" Returns:\n",
" Nothing.\n",
" \"\"\"\n",
" xspace = np.linspace(0, num_points, num_points)\n",
" fig, ax = plt.subplots()\n",
" ax.set_xlabel('n data points')\n",
" ax.set_ylabel('mu')\n",
" plt.plot(xspace, mu_classic,'r-', label=\"Classical\")\n",
" plt.plot(xspace, mu_bayes,'b-', label=\"Bayes\")\n",
" plt.legend()\n",
" plt.show()\n",
"\n",
" fig, ax = plt.subplots()\n",
" ax.set_xlabel('n data points')\n",
" ax.set_ylabel('sigma^2')\n",
" plt.plot(xspace, var_classic,'r-', label=\"Classical\")\n",
" plt.plot(xspace, var_bayes,'b-', label=\"Bayes\")\n",
" plt.legend()\n",
" plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
" ---\n",
"# Section 1: Basic probability"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 1.1: Basic probability theory"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Video 1: Basic Probability\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 1: Basic Probability\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'SL0_6rw8zrM'), ('Bilibili', 'BV1bw411o7HR')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Basic_Probability_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"This video covers basic probability theory, including complementary probability, conditional probability, joint probability, and marginalisation.\n",
"\n",
"\n",
" Click here for text recap of video
\n",
"\n",
"Previously we were only looking at sampling or properties of a single variables, but as we will now move on to statistical inference, it is useful to go over basic probability theory.\n",
"\n",
"\n",
"As a reminder, probability has to be in the range 0 to 1\n",
"$P(A) \\in [0,1] $\n",
"\n",
"and the complementary can always be defined as\n",
"\n",
"$P(\\neg A) = 1-P(A)$\n",
"\n",
"\n",
"When we have two variables, the *conditional probability* of $A$ given $B$ is\n",
"\n",
"$P (A|B) = P (A \\cap B)/P (B)=P (A, B)/P (B)$\n",
"\n",
"while the *joint probability* of $A$ and $B$ is\n",
"\n",
"$P(A \\cap B)=P(A,B) = P(B|A)P(A) = P(A|B)P(B) $\n",
"\n",
"We can then also define the process of *marginalisation* (for discrete variables) as\n",
"\n",
"$P(A)=\\sum P(A,B)=\\sum P(A|B)P(B)$\n",
"\n",
"where the summation is over the possible values of $B$.\n",
"\n",
"As an example if $B$ is a binary variable that can take values $B+$ or $B0$ then\n",
"$P(A)=\\sum P(A,B)=P(A|B+)P(B+)+ P(A|B0)P(B0) $.\n",
"\n",
"For continuous variables marginalization is given as\n",
"$P(A)=\\int P(A,B) dB=\\int P(A|B)P(B) dB$\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Math Exercise 1.1: Probability example\n",
"\n",
"To remind ourselves of how to use basic probability theory we will do a short exercise (no coding needed!), based on measurement of binary probabilistic neural responses.\n",
"As shown by Hubel and Wiesel in 1959 there are neurons in primary visual cortex that respond to different orientations of visual stimuli, with different neurons being sensitive to different orientations. The numbers in the following are however purely fictional.\n",
"\n",
"Imagine that your collaborator tells you that they have recorded the activity of visual neurons while presenting either a horizontal or vertical grid as a visual stimulus. The activity of the neurons is measured as binary: they are either active or inactive in response to the stimulus.\n",
"\n",
"After recording from a large number of neurons they find that when presenting a horizontal grid, on average 40% of neurons are active, while 30% respond to vertical grids.\n",
"\n",
"We will use the following notation to indicate the probability that a randomly chosen neuron responds to horizontal grids\n",
"\n",
"\\begin{equation}\n",
"P(h_+)=0.4\n",
"\\end{equation}\n",
"\n",
"and this to show the probability it responds to vertical:\n",
"\n",
"\\begin{equation}\n",
"P(v_+)=0.3\n",
"\\end{equation}\n",
"\n",
"We can find the complementary event, that the neuron does not respond to the horizontal grid, using the fact that these events must add up to 1. We see that the probability the neuron does not respond to the horizontal grid ($h_0$) is\n",
"\n",
"\\begin{equation}\n",
"P(h_0)=1-P(h_+)=0.6\n",
"\\end{equation}\n",
"\n",
"and that the probability to not respond to vertical is\n",
"\n",
"\\begin{equation}\n",
"P(v_0)=1-P(v_+)=0.7\n",
"\\end{equation}\n",
"\n",
"We will practice computing various probabilities in this framework."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### A) Product\n",
"\n",
"Assuming that the horizontal and vertical orientation selectivity are independent, what is the probability that a randomly chosen neuron is sensitive to both horizontal and vertical orientations?\n",
"\n",
"Hint: Two events are independent if the outcome of one does not affect the outcome of the other.\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/precourse/tree/main/tutorials/W0D5_Statistics/solutions/W0D5_Tutorial2_Solution_a800cd95.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### B) Joint probability generally\n",
"A collaborator informs you that actually these are not independent. Of those neurons that respond to vertical, only 10 percent also respond to horizontal, i.e. the probability of responding to horizonal *given* that it responds to vertical is $P(h+|v+)=0.1$\n",
"\n",
"Given this new information, what is now the probability that a randomly chosen neuron is sensitive to both horizontal and vertical orientations?\n",
"\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/precourse/tree/main/tutorials/W0D5_Statistics/solutions/W0D5_Tutorial2_Solution_efb5f300.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### C) Conditional probability\n",
"\n",
"You start measuring from a neuron and find that it responds to horizontal orientations. What is now the probability that it also responds to vertical, i.e., $P(v_+|h_+)$)?\n",
"\n",
"\n",
"\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/precourse/tree/main/tutorials/W0D5_Statistics/solutions/W0D5_Tutorial2_Solution_dfab0dfa.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### D) Marginal probability\n",
"\n",
"Lastly, let's check that everything has been done correctly. Given our knowledge about the conditional probabilities, we should be able to use marginalisation to recover the marginal probability of a random neuron responding to vertical orientations, i.e.,$P(v_+)$. We know from above that this should equal 0.3.\n",
"\n",
"Calculate $P(v_+)$ based on the conditional probabilities for $P(v_+|h_+)$ and $P(v_+|h_0)$ (the latter which you will need to calculate).\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/precourse/tree/main/tutorials/W0D5_Statistics/solutions/W0D5_Tutorial2_Solution_e558d38b.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Probability_Example_Main_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 1.2: Markov chains\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Video 2: Markov Chains\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 2: Markov Chains\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'XjQF13xMpss'), ('Bilibili', 'BV1Rh41187ZC')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Markov_Chains_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
"### Coding exercise 1.2 Markov chains\n",
"\n",
"\n",
"We will practice more probability theory by looking at **Markov chains**. The Markov property specifies that you can fully encapsulate the important properties of a system based on its *current* state at the current time, any previous history does not matter. It is memoryless.\n",
"\n",
"As an example imagine that a rat is able to move freely between 3 areas: a dark rest area\n",
"($state=1$), a nesting area ($state=2$) and a bright area for collecting food ($state=3$). Every 5 minutes (timepoint $i$) we record the rat's location. We can use a **categorical distribution** to look at the probability that the rat moves to one state from another.\n",
"\n",
"The table below shows the probability of the rat transitioning from one area to another between timepoints ($state_i$ to $state_{i+1}$).\n",
"\n",
"\\begin{matrix}\n",
"\\hline\n",
"state_{i} &P(state_{i+1}=1|state_i=*) &P(state_{i+1}=2|state_i=*) & P(state_{i+1}=3|state=_i*) \\\\ \\hline\n",
"state_{i}=1 & 0.2 & 0.6 & 0.2 \\\\\n",
"state_{i}=2 & 0.6 & 0.3 & 0.1 \\\\\n",
"state_{i}=3 & 0.8 & 0.2 & 0.0 \\\\\n",
"\\hline\n",
"\\end{matrix}\n",
"\n",
"We are modeling this as a Markov chain, so the animal is only in one of the states at a time and can transition between the states.\n",
"\n",
"We want to get the probability of each state at time $i+1$. We know from Section 1.1 that we can use marginalisation:\n",
"\n",
"\\begin{equation}\n",
"P(state_{i+1} = 1) = P(state_{i+1}=1|state_i=1)P(state_i = 1) + P(state_{i+1}=1|state_i=2)P(state_i = 2) + P(state_{i+1}=1|state_i=3)P(state_i = 3)\n",
"\\end{equation}\n",
"\n",
"Let's say we had a row vector (a vector defined as a row, not a column so matrix multiplication will work out) of the probabilities of the current state:\n",
"\n",
"\\begin{equation}\n",
"P_i = [P(state_i = 1), P(state_i = 2), P(state_i = 3) ]\n",
"\\end{equation}\n",
"\n",
"If we actually know where the rat is at the current time point, this would be deterministic (e.g., $P_i = [0, 1, 0]$ if the rat is in state 2). Otherwise, this could be probabilistic (e.g. $P_i = [0.1, 0.7, 0.2]$).\n",
"\n",
"To compute the vector of probabilities of the state at the time $i+1$, we can use linear algebra and multiply our vector of the probabilities of the current state with the transition matrix. Recall your matrix multiplication skills from W0D3 to check this!\n",
"\n",
"\\begin{equation}\n",
"P_{i+1} = P_{i} T\n",
"\\end{equation}\n",
"\n",
"where $T$ is our transition matrix.\n",
"\n",
"This is the same formula for every step, which allows us to get the probabilities for a time more than 1 step in advance easily. If we started at $i=0$ and wanted to look at the probabilities at step $i=2$, we could do:\n",
"\n",
"\\begin{align}\n",
"P_{1} &= P_{0}T\\\\\n",
"P_{2} &= P_{1}T = P_{0}TT = P_{0}T^2\\\\\n",
"\\end{align}\n",
"\n",
"So, every time we take a further step we can just multiply with the transition matrix again. So, the probability vector of states at j timepoints after the current state at timepoint i is equal to the probability vector at timepoint i times the transition matrix raised to the jth power.\n",
"\n",
"\\begin{equation}\n",
"P_{i + j} = P_{i}T^j\n",
"\\end{equation}\n",
"\n",
"If the animal starts in area 2, what is the probability the animal will again be in area 2 when we check on it 20 minutes (4 transitions) later?\n",
"\n",
"Fill in the transition matrix in the code below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"###################################################################\n",
"## TODO for student\n",
"## Fill out the following then remove\n",
"raise NotImplementedError(\"Student exercise: compute state probabilities after 4 transitions\")\n",
"###################################################################\n",
"\n",
"# Transition matrix\n",
"transition_matrix = np.array([[ 0.2, 0.6, 0.2], [ .6, 0.3, 0.1], [0.8, 0.2, 0]])\n",
"\n",
"# Initial state, p0\n",
"p0 = np.array([0, 1, 0])\n",
"\n",
"# Compute the probabilities 4 transitions later (use np.linalg.matrix_power to raise a matrix a power)\n",
"p4 = ...\n",
"\n",
"# The second area is indexed as 1 (Python starts indexing at 0)\n",
"print(f\"The probability the rat will be in area 2 after 4 transitions is: {p4[1]}\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"You should get a probability of `0.4311`, i.e., there is a 43.11% chance that you will find the rat in area 2 in 20 minutes."
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/precourse/tree/main/tutorials/W0D5_Statistics/solutions/W0D5_Tutorial2_Solution_582d22a1.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"What is the average amount of time spent by the rat in each of the states?\n",
"\n",
"Implicit in the question is the idea that we can start off with a random initial state and then measure how much relative time is spent in each area. If we make a few assumptions (e.g. ergodic or 'randomly mixing' system), we can instead start with an initial random distribution and see how the final probabilities of each state after many time steps (100) to estimate the time spent in each state."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Initialize random initial distribution\n",
"p_random = np.ones((1, 3))/3\n",
"\n",
"###################################################################\n",
"## TODO for student: Fill compute the state matrix after 100 transitions\n",
"raise NotImplementedError(\"Student exercise: need to complete computation below\")\n",
"###################################################################\n",
"\n",
"# Fill in the missing line to get the state matrix after 100 transitions, like above\n",
"p_average_time_spent = ...\n",
"print(f\"The proportion of time spend by the rat in each of the three states is: {p_average_time_spent[0]}\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The proportion of time spend in each of the three areas are `0.4473`, `0.4211`, and `0.1316`, respectively."
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/precourse/tree/main/tutorials/W0D5_Statistics/solutions/W0D5_Tutorial2_Solution_1b326e02.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Markov_Chains_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Imagine now that if the animal is satiated and tired the transitions change to:\n",
"\n",
"\\begin{matrix}\n",
"\\hline\n",
"state_{i} & P(state_{i+1}=1|state_i=*) & P(state_{i+1}=2|state_i=*) & P(state_{i+1}=3|state_i=*) \\\\\n",
"\\hline\n",
"state_{i}=1 & 0.2 & 0.7 & 0.1\\\\\n",
"state_{i}=2 & 0.3 & 0.7 & 0.0\\\\\n",
"state_{i}=3 & 0.8 & 0.2 & 0.0\\\\\n",
"\\hline\n",
"\\end{matrix}\n",
"\n",
"Try repeating the questions above for this table of transitions by changing the transition matrix. Based on the probability values, what would you predict? Check how much time the rat spends on average in each area and see if it matches your predictions.\n",
"\n",
"**Main course preview:** The Markov property is extremely important for many models, particularly Hidden Markov Models, discussed on [hidden dynamics day](https://compneuro.neuromatch.io/tutorials/W3D2_HiddenDynamics/chapter_title.html), and for methods such as Markov Chain Monte Carlo sampling."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 2: Statistical inference and likelihood"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 2.1: Likelihoods"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Video 3: Statistical inference and likelihood\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 3: Statistical inference and likelihood\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', '7aiKvKlYwR0'), ('Bilibili', 'BV1LM4y1g7wT')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Statistical_inference_and_likelihood_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Correction to video**: The variance estimate that maximizes the likelihood is $\\bar{\\sigma}^2=\\frac{1}{n} \\sum_i (x_i-\\bar{x})^2 $. This is a biased estimate. Shown in the video is the sample variance, which is an unbiased estimate for variance: $\\bar{\\sigma}^2=\\frac{1}{n-1} \\sum_i (x_i-\\bar{x})^2 $. See section 2.2.3 for more details."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
" Click here for text recap of video
\n",
"\n",
"A generative model (such as the Gaussian distribution from the previous tutorial) allows us to make predictions about outcomes.\n",
"\n",
"However, after we observe $n$ data points, we can also evaluate our model (and any of its associated parameters) by calculating the **likelihood** of our model having generated each of those data points $x_i$.\n",
"\n",
"\\begin{equation}\n",
"P(x_i|\\mu,\\sigma)=\\mathcal{N}(x_i,\\mu,\\sigma)\n",
"\\end{equation}\n",
"\n",
"For all data points $\\mathbf{x}=(x_1, x_2, x_3, ...x_n) $ we can then calculate the likelihood for the whole dataset by computing the product of the likelihood for each single data point.\n",
"\n",
"\\begin{equation}\n",
"P(\\mathbf{x}|\\mu,\\sigma)=\\prod_{i=1}^n \\mathcal{N}(x_i,\\mu,\\sigma)\n",
"\\end{equation}\n",
"\n",
" \n",
"\n",
"While the likelihood may be written as a conditional probability ($P(x|\\mu,\\sigma)$), we refer to it as the **likelihood function**, $L(\\mu,\\sigma)$. This slight switch in notation is to emphasize our focus: we use likelihood functions when the data points $\\mathbf{x}$ are fixed and we are focused on the parameters.\n",
"\n",
"Our new notation makes clear that the likelihood $L(\\mu,\\sigma)$ is a function of $\\mu$ and $\\sigma$, not of $\\mathbf{x}$.\n",
"\n",
"In the last tutorial we reviewed how the data was generated given the selected parameters of the generative process. If we do not know the parameters $\\mu$, $\\sigma$ that generated the data, we can try to **infer** which parameter values (given our model) gives the best (highest) likelihood. This is what we call statistical inference: trying to infer what parameters make our observed data the most likely or probable?"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Coding Exercise 2.1: Computing likelihood\n",
"\n",
"Let's start with computing the likelihood of some set of data points being drawn from a Gaussian distribution with a mean and variance we choose.\n",
"\n",
"\n",
"\n",
"As multiplying small probabilities together can lead to very small numbers, it is often convenient to report the *logarithm* of the likelihood. This is just a convenient transformation and as logarithm is a monotonically increasing function this does not change what parameters maximise the function.\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def compute_likelihood_normal(x, mean_val, standard_dev_val):\n",
" \"\"\" Computes the log-likelihood values given a observed data sample x, and\n",
" potential mean and variance values for a normal distribution\n",
"\n",
" Args:\n",
" x (ndarray): 1-D array with all the observed data\n",
" mean_val (scalar): value of mean for which to compute likelihood\n",
" standard_dev_val (scalar): value of variance for which to compute likelihood\n",
"\n",
" Returns:\n",
" likelihood (scalar): value of likelihood for this combination of means/variances\n",
" \"\"\"\n",
"\n",
" ###################################################################\n",
" ## TODO for student\n",
" raise NotImplementedError(\"Student exercise: compute likelihood\")\n",
" ###################################################################\n",
"\n",
" # Get probability of each data point (use norm.pdf from scipy stats)\n",
" p_data = ...\n",
"\n",
" # Compute likelihood (sum over the log of the probabilities)\n",
" likelihood = ...\n",
"\n",
" return likelihood\n",
"\n",
"# Set random seed\n",
"np.random.seed(0)\n",
"\n",
"# Generate data\n",
"true_mean = 5\n",
"true_standard_dev = 1\n",
"n_samples = 1000\n",
"x = np.random.normal(true_mean, true_standard_dev, size = (n_samples,))\n",
"\n",
"# Compute likelihood for a guessed mean/standard dev\n",
"guess_mean = 4\n",
"guess_standard_dev = .1\n",
"likelihood = compute_likelihood_normal(x, guess_mean, guess_standard_dev)\n",
"print(likelihood)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"You should get a likelihood of `-92904.81`."
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/precourse/tree/main/tutorials/W0D5_Statistics/solutions/W0D5_Tutorial2_Solution_bd7d0ec0.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"This is somewhat meaningless to us! For it to be useful, we need to compare it to the likelihoods computing using other guesses of the mean or standard deviation. The visualization below shows us the likelihood for various values of the mean and the standard deviation. Essentially, we are performing a rough grid-search over means and standard deviations. What would you guess as the true mean and standard deviation based on this visualization?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute to visualize likelihoods\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute to visualize likelihoods\n",
"\n",
"# Set random seed\n",
"np.random.seed(0)\n",
"\n",
"# Generate data\n",
"true_mean = 5\n",
"true_standard_dev = 1\n",
"n_samples = 1000\n",
"x = np.random.normal(true_mean, true_standard_dev, size = (n_samples,))\n",
"\n",
"\n",
"# Compute likelihood for different mean/variance values\n",
"mean_vals = np.linspace(1, 10, 10) # potential mean values to ry\n",
"standard_dev_vals = np.array([0.7, 0.8, 0.9, 1, 1.2, 1.5, 2, 3, 4, 5]) # potential variance values to try\n",
"\n",
"# Initialise likelihood collection array\n",
"likelihood = np.zeros((mean_vals.shape[0], standard_dev_vals.shape[0]))\n",
"\n",
"# Compute the likelihood for observing the gvien data x assuming\n",
"# each combination of mean and variance values\n",
"for idxMean in range(mean_vals.shape[0]):\n",
" for idxVar in range(standard_dev_vals .shape[0]):\n",
" likelihood[idxVar,idxMean]= sum(np.log(norm.pdf(x, mean_vals[idxMean],\n",
" standard_dev_vals[idxVar])))\n",
"\n",
"# Uncomment once you've generated the samples and compute likelihoods\n",
"xspace = np.linspace(0, 10, 100)\n",
"plot_likelihoods(likelihood, mean_vals, standard_dev_vals)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Computing_likelihood_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 2.2: Maximum likelihood"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Video 4: Maximum likelihood\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 4: Maximum likelihood\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'Fuwx_V64nEU'), ('Bilibili', 'BV1Lo4y1C7xy')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Maximum_likelihood_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
"Implicitly, by looking for the parameters that give the highest likelihood in the last section, we have been searching for the **maximum likelihood** estimate.\n",
"\\begin{equation}\n",
"(\\hat{\\mu},\\hat{\\sigma}) = \\underset{\\mu,\\sigma}{\\operatorname{argmax}}L(\\mu,\\sigma) = \\underset{\\mu,\\sigma}{\\operatorname{argmax}} \\prod_{i=1}^n \\mathcal{N}(x_i,\\mu,\\sigma).\n",
"\\end{equation}\n",
"\n",
"In next sections, we will look at other ways of inferring such parameter variables."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Section 2.2.1: Searching for best parameters\n",
"\n",
"We want to do inference on this data set, i.e. we want to infer the parameters that most likely gave rise to the data given our model. Intuitively that means that we want as good as possible a fit between the observed data and the probability distribution function with the best inferred parameters. We can search for the best parameters manually by trying out a bunch of possible values of the parameters, computing the likelihoods, and picking the parameters that resulted in the highest likelihood."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"#### Interactive Demo 2.2: Maximum likelihood inference\n",
"\n",
"Try to see how well you can fit the probability distribution to the data by using the demo sliders to control the mean and standard deviation parameters of the distribution. We will visualize the histogram of data points (in blue) and the Gaussian density curve with that mean and standard deviation (in red). Below, we print the log-likelihood.\n",
"\n",
"- What (approximate) values of mu and sigma result in the best fit?\n",
"- How does the value below the plot (the log-likelihood) change with the quality of fit?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Make sure you execute this cell to enable the widget and fit by hand!\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Make sure you execute this cell to enable the widget and fit by hand!\n",
"# Generate data\n",
"true_mean = 5\n",
"true_standard_dev = 1\n",
"n_samples = 1000\n",
"vals = np.random.normal(true_mean, true_standard_dev, size = (n_samples,))\n",
"\n",
"def plotFnc(mu,sigma):\n",
" loglikelihood= sum(np.log(norm.pdf(vals,mu,sigma)))\n",
" #calculate histogram\n",
"\n",
" #prepare to plot\n",
" fig, ax = plt.subplots()\n",
" ax.set_xlabel('x')\n",
" ax.set_ylabel('probability')\n",
"\n",
" #plot histogram\n",
" count, bins, ignored = plt.hist(vals,density=True)\n",
" x = np.linspace(0,10,100)\n",
"\n",
" #plot pdf\n",
" plt.plot(x, norm.pdf(x,mu,sigma),'r-')\n",
" plt.show()\n",
" print(\"The log-likelihood for the selected parameters is: \" + str(loglikelihood))\n",
"\n",
"#interact(plotFnc, mu=5.0, sigma=2.1);\n",
"#interact(plotFnc, mu=widgets.IntSlider(min=0.0, max=10.0, step=1, value=4.0),sigma=widgets.IntSlider(min=0.1, max=10.0, step=1, value=4.0));\n",
"interact(plotFnc, mu=(0.0, 15.0, 0.1),sigma=(0.1, 5.0, 0.1));"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/precourse/tree/main/tutorials/W0D5_Statistics/solutions/W0D5_Tutorial2_Solution_097c8cc8.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Doing this was similar to the grid searched image from Section 2.1. Really, we want to see if we can do inference on observed data in a bit more principled way.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Maximum_likelihood_inference_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Section 2.2.2: Optimization to find parameters\n",
"\n",
"Let's again assume that we have a data set, $\\mathbf{x}$, assumed to be generated by a normal distribution (we actually generate it ourselves in line 1, so we know how it was generated!).\n",
"We want to maximise the likelihood of the parameters $\\mu$ and $\\sigma^2$. We can do so using a couple of tricks:\n",
"\n",
"* Using a log transform will not change the maximum of the function, but will allow us to work with very small numbers that could lead to problems with machine precision.\n",
"* Maximising a function is the same as minimising the negative of a function, allowing us to use the minimize optimisation provided by scipy.\n",
"\n",
"The optimisation will be done using `sp.optimize.minimize`, which does a version of gradient descent (there are hundreds of ways to do numerical optimisation, we will not cover these here!)."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"#### Coding Exercise 2.2: Maximum Likelihood Estimation\n",
"\n",
"\n",
"In the code below, insert the missing line (see the `compute_likelihood_normal` function from previous exercise), with the mean as `theta[0]` and standard deviation as `theta[1]`.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# We define the function to optimise, the negative log likelihood\n",
"def negLogLike(theta, x):\n",
" \"\"\" Function for computing the negative log-likelihood given the observed data\n",
" and given parameter values stored in theta.\n",
"\n",
" Args:\n",
" theta (ndarray): normal distribution parameters\n",
" (mean is theta[0], standard deviation is theta[1])\n",
" x (ndarray): array with observed data points\n",
"\n",
" Returns:\n",
" Calculated negative Log Likelihood value!\n",
" \"\"\"\n",
" ###################################################################\n",
" ## TODO for students: Compute the negative log-likelihood value for the\n",
" ## given observed data values and parameters (theta)\n",
" # Fill out the following then remove\n",
" raise NotImplementedError(\"Student exercise: need to compute the negative \\\n",
" log-likelihood value\")\n",
" ###################################################################\n",
" return ...\n",
"\n",
"# Set random seed\n",
"np.random.seed(0)\n",
"\n",
"# Generate data\n",
"true_mean = 5\n",
"true_standard_dev = 1\n",
"n_samples = 1000\n",
"x = np.random.normal(true_mean, true_standard_dev, size=(n_samples, ))\n",
"\n",
"# Define bounds, var has to be positive\n",
"bnds = ((None, None), (0, None))\n",
"\n",
"# Optimize with scipy!\n",
"optimal_parameters = sp.optimize.minimize(negLogLike, (2, 2), args=x, bounds=bnds)\n",
"print(f\"The optimal mean estimate is: {optimal_parameters.x[0]}\")\n",
"print(f\"The optimal standard deviation estimate is: {optimal_parameters.x[1]}\")\n",
"\n",
"# optimal_parameters contains a lot of information about the optimization,\n",
"# but we mostly want the mean and standard deviation"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/precourse/tree/main/tutorials/W0D5_Statistics/solutions/W0D5_Tutorial2_Solution_6dff9e6e.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"These are the approximations of the parameters that maximise the likelihood ($\\mu$ ~ 5.280 and $\\sigma$ ~ 1.148).\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"##### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Maximum_likelihood_estimation_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Section 2.2.3: Analytical solution\n",
"\n",
"Sometimes, things work out well and we can come up with formulas for the maximum likelihood estimates of parameters. We won't get into this further but basically we could set the derivative of the likelihood to 0 (to find a maximum) and solve for the parameters. This won't always work but for the Gaussian distribution, it does.\n",
"\n",
"Specifically , the special thing about the Gaussian is that mean and standard deviation of the random sample can effectively approximate the two parameters of a Gaussian, $\\mu, \\sigma$.\n",
"\n",
"\n",
"Hence using the mean, $\\bar{x}=\\frac{1}{n}\\sum_i x_i$, and variance, $\\bar{\\sigma}^2=\\frac{1}{n} \\sum_i (x_i-\\bar{x})^2 $ of the sample should give us the best/maximum likelihood, $L(\\bar{x},\\bar{\\sigma}^2)$.\n",
"\n",
"Let's compare these values to those we've been finding using manual search and optimization, and the true values (which we only know because we generated the numbers!)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"# Set random seed\n",
"np.random.seed(0)\n",
"\n",
"# Generate data\n",
"true_mean = 5\n",
"true_standard_dev = 1\n",
"n_samples = 1000\n",
"x = np.random.normal(true_mean, true_standard_dev, size=(n_samples, ))\n",
"\n",
"# Compute and print sample means and standard deviations\n",
"print(f\"This is the sample mean as estimated by numpy: {np.mean(x)}\")\n",
"print(f\"This is the sample standard deviation as estimated by numpy: {np.std(x)}\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/precourse/tree/main/tutorials/W0D5_Statistics/solutions/W0D5_Tutorial2_Solution_fe639311.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"If you try out different values of the mean and standard deviation in all the previous exercises, you should see that changing the mean and\n",
"sigma parameter values (and generating new data from a distribution with theseparameters) makes no difference as MLE methods can still recover these parameters.\n",
"\n",
"There is a slight problem: it turns out that the maximum likelihood estimate for the variance is actually a biased one! This means that the estimators expected value (mean value) and the true value of the parameter are different. An unbiased estimator for the variance is $\\bar{\\sigma}^2=\\frac{1}{n-1} \\sum_i (x_i-\\bar{x})^2 $, this is called the sample variance. For more details, see [the wiki page on bias of estimators](https://en.wikipedia.org/wiki/Bias_of_an_estimator)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Analytical_Solution_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Section 3: Bayesian Inference"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 3.1: Bayes"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Video 5: Bayesian inference with Gaussian distribution\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 5: Bayesian inference with Gaussian distribution\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', '1Q3VqcpfvBk'), ('Bilibili', 'BV11K4y1u7vH')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Bayesian_inference_with_Gaussian_distribution_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Note:** The Bayes rule in the video (0:14-3:05) contains a typo: the denominator should be $P(x)$ and not $P(x,\\theta)$. So, the formula should be $ P(\\theta | x) = \\frac{P(x|\\theta) P(\\theta)}{P(x)}$."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We will start to introduce Bayesian inference here to contrast with our maximum likelihood methods, but you will also revisit Bayesian inference in great detail on [Bayesian Decisions day](https://compneuro.neuromatch.io/tutorials/W3D1_BayesianDecisions/chapter_title.html) of the course so we won't dive into all details.\n",
"\n",
"For Bayesian inference we do not focus on the likelihood function $L(y)=P(x|y)$, but instead focus on the posterior distribution:\n",
"\n",
"\\begin{equation}\n",
"P(y|x)=\\frac{P(x|y)P(y)}{P(x)}\n",
"\\end{equation}\n",
"\n",
"which is composed of the **likelihood** function $P(x|y)$, the **prior** $P(y)$ and a normalising term $P(x)$ (which we will ignore for now).\n",
"\n",
"While there are other advantages to using Bayesian inference (such as the ability to derive Bayesian Nets, see optional bonus task below), we will start by focusing on the role of the prior in inference. Does including prior information allow us to infer parameters in a better way?"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! 3.1: Bayesian inference with Gaussian distribution\n",
"\n",
"In the above sections we performed inference using maximum likelihood, i.e. finding the parameters that maximised the likelihood of a set of parameters, given the model and data.\n",
"\n",
"We will now repeat the inference process, but with an added Bayesian prior, and compare it to the \"classical\" inference (maximum likelihood) process we did before (Section 2). When using conjugate priors (more on this below) we can just update the parameter values of the distributions (here Gaussian distributions).\n",
"\n",
"\n",
"For the prior we start by guessing a mean of 5 (mean of previously observed data points 4 and 6) and variance of 1 (variance of 4 and 6). We use a trick (not detailed here) that is a simplified way of applying a prior, that allows us to just add these 2 values (pseudo-data) to the real data.\n",
"\n",
"See the visualization below that shows the mean and standard deviation inferred by our classical maximum likelihood approach and the Bayesian approach for different numbers of data points.\n",
"\n",
"Remembering that our true values are $\\mu = 5$, and $\\sigma^2 = 1$, how do the Bayesian inference and classical inference compare?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Execute to visualize inference\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @markdown Execute to visualize inference\n",
"\n",
"def classic_vs_bayesian_normal(mu, sigma, num_points, prior):\n",
" \"\"\" Compute both classical and Bayesian inference processes over the range of\n",
" data sample sizes (num_points) for a normal distribution with parameters\n",
" mu,sigma for comparison.\n",
"\n",
" Args:\n",
" mu (scalar): the mean parameter of the normal distribution\n",
" sigma (scalar): the standard deviation parameter of the normal distribution\n",
" num_points (int): max number of points to use for inference\n",
" prior (ndarray): prior data points for Bayesian inference\n",
"\n",
" Returns:\n",
" mean_classic (ndarray): estimate mean parameter via classic inference\n",
" var_classic (ndarray): estimate variance parameter via classic inference\n",
" mean_bayes (ndarray): estimate mean parameter via Bayesian inference\n",
" var_bayes (ndarray): estimate variance parameter via Bayesian inference\n",
" \"\"\"\n",
"\n",
" # Initialize the classical and Bayesian inference arrays that will estimate\n",
" # the normal parameters given a certain number of randomly sampled data points\n",
" mean_classic = np.zeros(num_points)\n",
" var_classic = np.zeros(num_points)\n",
"\n",
" mean_bayes = np.zeros(num_points)\n",
" var_bayes = np.zeros(num_points)\n",
"\n",
" for nData in range(num_points):\n",
"\n",
" random_num_generator = default_rng(0)\n",
" x = random_num_generator.normal(mu, sigma, nData + 1)\n",
"\n",
" # Compute the mean of those points and set the corresponding array entry to this value\n",
" mean_classic[nData] = np.mean(x)\n",
"\n",
" # Compute the variance of those points and set the corresponding array entry to this value\n",
" var_classic[nData] = np.var(x)\n",
"\n",
" # Bayesian inference with the given prior is performed below for you\n",
" xsupp = np.hstack((x, prior))\n",
" mean_bayes[nData] = np.mean(xsupp)\n",
" var_bayes[nData] = np.var(xsupp)\n",
"\n",
" return mean_classic, var_classic, mean_bayes, var_bayes\n",
"\n",
"# Set random seed\n",
"np.random.seed(0)\n",
"\n",
"# Set normal distribution parameters, mu and sigma\n",
"mu = 5\n",
"sigma = 1\n",
"\n",
"# Set the prior to be two new data points, 4 and 6, and print the mean and variance\n",
"prior = np.array((4, 6))\n",
"print(\"The mean of the data comprising the prior is: \" + str(np.mean(prior)))\n",
"print(\"The variance of the data comprising the prior is: \" + str(np.var(prior)))\n",
"\n",
"mean_classic, var_classic, mean_bayes, var_bayes = classic_vs_bayesian_normal(mu, sigma, 60, prior)\n",
"plot_classical_vs_bayesian_normal(60, mean_classic, var_classic, mean_bayes, var_bayes)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/precourse/tree/main/tutorials/W0D5_Statistics/solutions/W0D5_Tutorial2_Solution_439c8c36.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
"\n",
"Note that the prior is only beneficial when it is close to the true value, i.e., 'a good guess' (or at least not 'a bad guess'). As we will see in the next exercise, if you have a prior/bias that is very wrong, your inference will start off very wrong!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Bayesian_inference_with_Gaussian_distribution_Discussion\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Section 3.2: Conjugate priors"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Video 6: Conjugate priors\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 6: Conjugate priors\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'mDEyZHaG5aY'), ('Bilibili', 'BV1Hg41137Zr')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Conjugate_priors_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Interactive Demo 3.2: Conjugate priors\n",
"Let's return to our example from Tutorial 1 using the binomial distribution - rat in a T-maze.\n",
"\n",
"Bayesian inference can be used for any likelihood distribution, but it is a lot more convenient to work with **conjugate** priors, where multiplying the prior with the likelihood just provides another instance of the prior distribution with updated values.\n",
"\n",
"For the binomial likelihood it is convenient to use the **beta** distribution as a prior\n",
"\n",
"\\begin{equation}\n",
"f(p;\\alpha ,\\beta )={\\frac {1}{\\mathrm {B} (\\alpha ,\\beta )}}p^{\\alpha -1}(1-p)^{\\beta -1}\n",
"\\end{equation}\n",
"\n",
"where $B$ is the beta function, $\\alpha$ and $\\beta$ are parameters, and $p$ is the probability of the rat turning left or right. The beta distribution is thus a distribution over a probability.\n",
"\n",
"Given a series of Left and Right moves of the rat, we can now estimate the probability that the animal will turn left. Using Bayesian Inference, we use a beta distribution *prior*, which is then multiplied with the *likelihood* to create a *posterior* that is also a beta distribution, but with updated parameters (we will not cover the math here).\n",
"\n",
"Activate the widget below to explore the variables, and follow the instructions below."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### \n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Make sure you execute this cell to enable the widget\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"#@title\n",
"\n",
"#@markdown Make sure you execute this cell to enable the widget\n",
"\n",
"#beta distribution\n",
"#and binomial\n",
"def plotFnc(p,n,priorL,priorR):\n",
" # Set random seed\n",
" np.random.seed(1)\n",
" #sample from binomial\n",
" numL = np.random.binomial(n, p, 1)\n",
" numR = n - numL\n",
" stepSize=0.001\n",
" x = np.arange(0, 1, stepSize)\n",
" betaPdf=sp.stats.beta.pdf(x,numL+priorL,numR+priorR)\n",
" betaPrior=sp.stats.beta.pdf(x,priorL,priorR)\n",
" print(\"number of left \"+str(numL))\n",
" print(\"number of right \"+str(numR))\n",
" print(\" \")\n",
" print(\"max likelihood \"+str(numL/(numL+numR)))\n",
" print(\" \")\n",
" print(\"max posterior \" + str(x[np.argmax(betaPdf)]))\n",
" print(\"mean posterior \" + str(np.mean(betaPdf*x)))\n",
"\n",
"\n",
" print(\" \")\n",
"\n",
" with plt.xkcd():\n",
" #rng.beta()\n",
" fig, ax = plt.subplots()\n",
" plt.rcParams.update({'font.size': 22})\n",
" ax.set_xlabel('p')\n",
" ax.set_ylabel('probability density')\n",
" plt.plot(x,betaPdf, label = \"Posterior\")\n",
" plt.plot(x,betaPrior, label = \"Prior\")\n",
" #print(int(len(betaPdf)/2))\n",
" plt.legend()\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"interact(plotFnc, p=(0, 1, 0.01),n=(1, 50, 1), priorL=(1, 10, 1),priorR=(1, 10, 1));"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The plot above shows you the prior distribution (i.e. before any data) and the posterior distribution (after data), with a summary of the data (number of left and right moves) and the maximum likelihood, maximum posterior and mean of the posterior. Dependent on the purpose either the mean or the max of the posterior can be useful as a 'single-number' summary of the posterior.\n",
"Once you are familiar with the sliders and what they represent, go through these instructions.\n",
"\n",
"**For $p=0.5$**\n",
"\n",
"- Set $p=0.5$ and start off with a \"flat\" prior (`priorL=0`, `priorR=0`). Note that the prior distribution (orange) is flat, also known as uniformative. In this case the maximum likelihood and maximum posterior will get you almost identical results as you vary the number of datapoints ($n$) and the probability of the rat going left. However the posterior is a full distribution and not just a single point estimate.\n",
"\n",
"- As $n$ gets large you will also notice that the estimate (max likelihood or max posterior) changes less for each change in $n$, i.e. the estimation stabilises.\n",
"\n",
"- How many data points do you need think is needed for the probability estimate to stabilise? Note that this depends on how large fluctuations you are willing to accept.\n",
"\n",
"- Try increasing the strength of the prior, `priorL=10` and `priorR=10`. You will see that the prior distribution becomes more 'peaky'. In short this prior means that small or large values of $p$ are conidered very unlikely. Try playing with the number of data points $n$, you should find that the prior stabilises/regularises the maximum posterior estimate so that it does not move as much.\n",
"\n",
"**For $p=0.2$**\n",
"\n",
"Try the same as you just did, now with $p=0.2$,\n",
"do you notice any differences? Note that the prior (assumeing equal chance Left and Right) is now badly matched to the data. Do the maximum likelihood and maximum posterior still give similar results, for a weak prior? For a strong prior? Does the prior still have a stabilising effect on the estimate?\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"**Take-away message:**\n",
"Bayesian inference gives you a full distribution over the variables that you are inferring, can help regularise inference when you have limited data, and allows you to build more complex models that better reflects true causality (see bonus below)."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"### Think! 3.2: Bayesian Brains\n",
"Bayesian inference can help you when doing data analysis, especially when you only have little data. But consider whether the brain might be able to benefit from this too. If the brain needs to make inferences about the world, would it be useful to do regularisation on the input? Maybe there are times where having a full probability distribution could be useful?"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/precourse/tree/main/tutorials/W0D5_Statistics/solutions/W0D5_Tutorial2_Solution_281848de.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Conjugate_priors_Interactive_Demo\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Summary\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 7: Summary\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 7: Summary\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'OJN7ri3_FCA'), ('Bilibili', 'BV1qB4y1K7WZ')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Summary_Video\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
"Having done the different exercises you should now:\n",
"* understand what the likelihood function is, and have some intuition of why it is important\n",
"* know how to summarise the Gaussian distribution using mean and variance\n",
"* know how to maximise a likelihood function\n",
"* be able to do simple inference in both classical and Bayesian ways\n",
"\n",
"For more resources see [here](https://github.com/NeuromatchAcademy/precourse/blob/master/resources.md)."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"---\n",
"# Bonus"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus Coding Exercise 1: Finding the posterior computationally\n",
"\n",
"Imagine an experiment where participants estimate the location of a noise-emitting object. To estimate its position, the participants can use two sources of information:\n",
" 1. new noisy auditory information (the likelihood)\n",
" 2. prior visual expectations of where the stimulus is likely to come from (visual prior).\n",
"\n",
"The auditory and visual information are both noisy, so participants will combine these sources of information to better estimate the position of the object.\n",
"\n",
"We will use Gaussian distributions to represent the auditory likelihood (in red), and a Gaussian visual prior (expectations - in blue). Using Bayes rule, you will combine them into a posterior distribution that summarizes the probability that the object is in each possible location.\n",
"\n",
"We have provided you with a ready-to-use plotting function, and a code skeleton.\n",
"\n",
"* You can use `my_gaussian` from Tutorial 1 (also included below), to generate an auditory likelihood with parameters $\\mu = 3$ and $\\sigma = 1.5$\n",
"* Generate a visual prior with parameters $\\mu = -1$ and $\\sigma = 1.5$\n",
"* Calculate the posterior using pointwise multiplication of the likelihood and prior. Don't forget to normalize so the posterior adds up to 1\n",
"* Plot the likelihood, prior and posterior using the predefined function `posterior_plot`"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"def my_gaussian(x_points, mu, sigma):\n",
" \"\"\" Returns normalized Gaussian estimated at points `x_points`, with parameters:\n",
" mean `mu` and standard deviation `sigma`\n",
"\n",
" Args:\n",
" x_points (ndarray of floats): points at which the gaussian is evaluated\n",
" mu (scalar): mean of the Gaussian\n",
" sigma (scalar): standard deviation of the gaussian\n",
"\n",
" Returns:\n",
" (numpy array of floats) : normalized Gaussian evaluated at `x`\n",
" \"\"\"\n",
" px = 1/(2*np.pi*sigma**2)**1/2 *np.exp(-(x_points-mu)**2/(2*sigma**2))\n",
"\n",
" # as we are doing numerical integration we may have to remember to normalise\n",
" # taking into account the stepsize (0.1)\n",
" px = px/(0.1*sum(px))\n",
" return px\n",
"\n",
"\n",
"def compute_posterior_pointwise(prior, likelihood):\n",
" \"\"\" Compute the posterior probability distribution point-by-point using Bayes\n",
" Rule.\n",
"\n",
" Args:\n",
" prior (ndarray): probability distribution of prior\n",
" likelihood (ndarray): probability distribution of likelihood\n",
"\n",
" Returns:\n",
" posterior (ndarray): probability distribution of posterior\n",
" \"\"\"\n",
" ##############################################################################\n",
" # TODO for students: Write code to compute the posterior from the prior and\n",
" # likelihood via pointwise multiplication. (You may assume both are defined\n",
" # over the same x-axis)\n",
" #\n",
" # Comment out the line below to test your solution\n",
" raise NotImplementedError(\"Finish the simulation code first\")\n",
" ##############################################################################\n",
"\n",
" posterior = ...\n",
"\n",
" return posterior\n",
"\n",
"\n",
"def localization_simulation(mu_auditory=3.0, sigma_auditory=1.5,\n",
" mu_visual=-1.0, sigma_visual=1.5):\n",
" \"\"\" Perform a sound localization simulation with an auditory prior.\n",
"\n",
" Args:\n",
" mu_auditory (float): mean parameter value for auditory prior\n",
" sigma_auditory (float): standard deviation parameter value for auditory\n",
" prior\n",
" mu_visual (float): mean parameter value for visual likelihood distribution\n",
" sigma_visual (float): standard deviation parameter value for visual\n",
" likelihood distribution\n",
"\n",
" Returns:\n",
" x (ndarray): range of values for which to compute probabilities\n",
" auditory (ndarray): probability distribution of the auditory prior\n",
" visual (ndarray): probability distribution of the visual likelihood\n",
" posterior_pointwise (ndarray): posterior probability distribution\n",
" \"\"\"\n",
" ##############################################################################\n",
" ## Using the x variable below,\n",
" ## create a gaussian called 'auditory' with mean 3, and std 1.5\n",
" ## create a gaussian called 'visual' with mean -1, and std 1.5\n",
" #\n",
" #\n",
" ## Comment out the line below to test your solution\n",
" raise NotImplementedError(\"Finish the simulation code first\")\n",
" ###############################################################################\n",
" x = np.arange(-8, 9, 0.1)\n",
"\n",
" auditory = ...\n",
" visual = ...\n",
" posterior = compute_posterior_pointwise(auditory, visual)\n",
"\n",
" return x, auditory, visual, posterior\n",
"\n",
"\n",
"x, auditory, visual, posterior_pointwise=localization_simulation()\n",
"_ = posterior_plot(x, auditory, visual, posterior_pointwise)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/precourse/tree/main/tutorials/W0D5_Statistics/solutions/W0D5_Tutorial2_Solution_dd2d1f7b.py)\n",
"\n",
"*Example output:*\n",
"\n",
"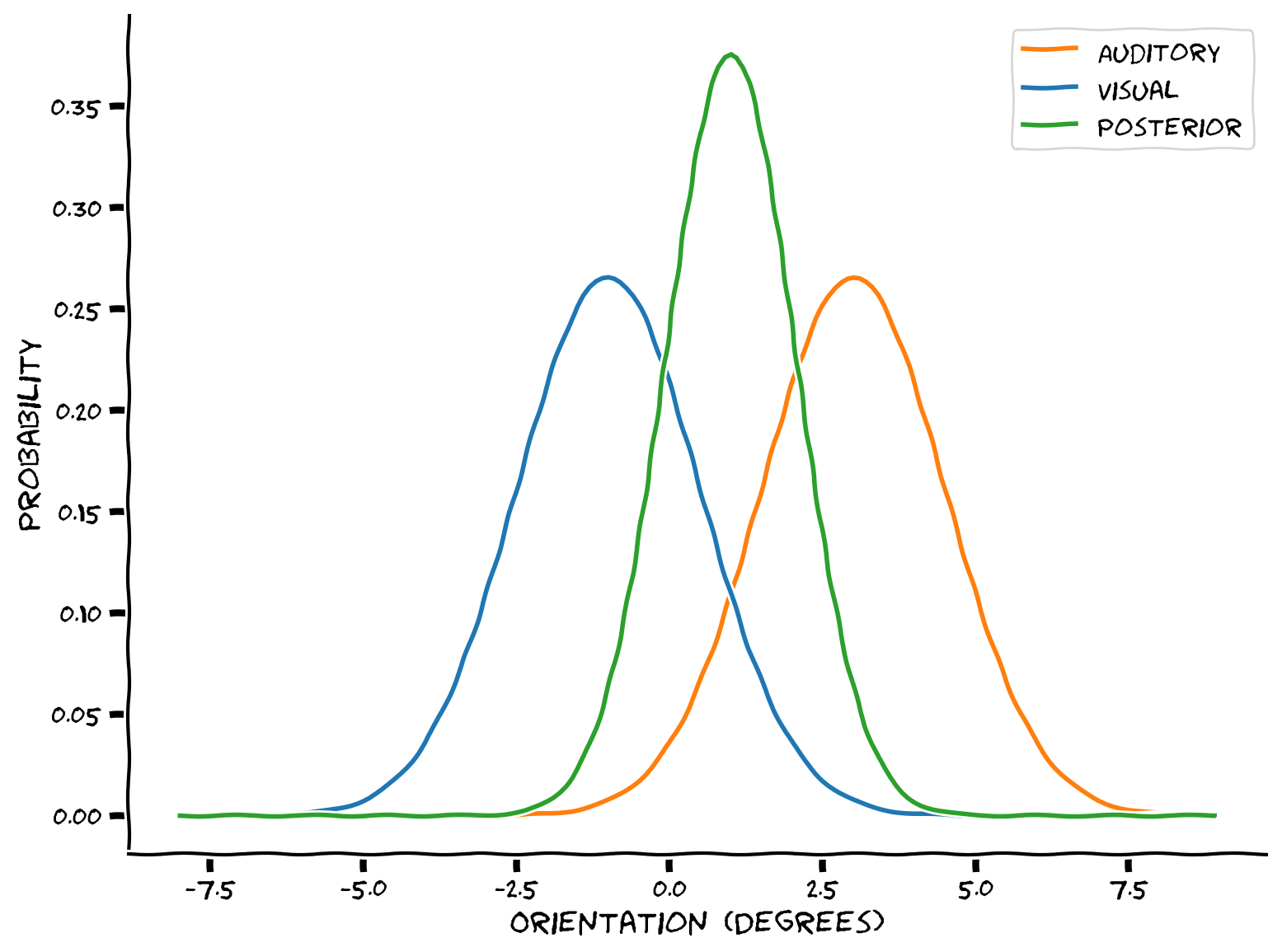 \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Combining the the visual and auditory information could help the brain get a better estimate of the location of an audio-visual object, with lower variance.\n",
"\n",
"**Main course preview:** On [Bayesian Decisions day](W3D1) there will be a whole day devoted to examining whether the brain uses Bayesian inference. Is the brain Bayesian?!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Finding_the_posterior_computationally_Bonus_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus Coding Exercise 2: Bayes Net\n",
"If you have the time, here is another extra exercise.\n",
"\n",
"Bayes Net, or Bayesian Belief Networks, provide a way to make inferences about multiple levels of information, which would be very difficult to do in a classical frequentist paradigm.\n",
"\n",
"We can encapsulate our knowledge about causal relationships and use this to make inferences about hidden properties."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We will try a simple example of a Bayesian Net (aka belief network). Imagine that you have a house with an unreliable sprinkler system installed for watering the grass. This is set to water the grass independently of whether it has rained that day. We have three variables, rain ($r$), sprinklers ($s$) and wet grass ($w$). Each of these can be true (1) or false (0). See the graphical model representing the relationship between the variables."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Combining the the visual and auditory information could help the brain get a better estimate of the location of an audio-visual object, with lower variance.\n",
"\n",
"**Main course preview:** On [Bayesian Decisions day](W3D1) there will be a whole day devoted to examining whether the brain uses Bayesian inference. Is the brain Bayesian?!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Finding_the_posterior_computationally_Bonus_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus Coding Exercise 2: Bayes Net\n",
"If you have the time, here is another extra exercise.\n",
"\n",
"Bayes Net, or Bayesian Belief Networks, provide a way to make inferences about multiple levels of information, which would be very difficult to do in a classical frequentist paradigm.\n",
"\n",
"We can encapsulate our knowledge about causal relationships and use this to make inferences about hidden properties."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"We will try a simple example of a Bayesian Net (aka belief network). Imagine that you have a house with an unreliable sprinkler system installed for watering the grass. This is set to water the grass independently of whether it has rained that day. We have three variables, rain ($r$), sprinklers ($s$) and wet grass ($w$). Each of these can be true (1) or false (0). See the graphical model representing the relationship between the variables."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"There is a table below describing all the relationships between $w, r$, and s$.\n",
"\n",
"Obviously the grass is more likely to be wet if either the sprinklers were on or it was raining. On any given day the sprinklers have probability 0.25 of being on, $P(s = 1) = 0.25$, while there is a probability 0.1 of rain, $P (r = 1) = 0.1$. The table then lists the conditional probabilities for the given being wet, given a rain and sprinkler condition for that day.\n",
"\n",
"
\n",
"\n",
"\\begin{matrix}\n",
"\\hline\n",
"r & s & P(w=0|r,s) & P(w=1|r,s)\\\\\n",
"\\hline\n",
"0 & 0 & 0.999 & 0.001 \\\\\n",
"0 & 1 & 0.1 & 0.9 \\\\\n",
"1 & 0 & 0.01 & 0.99 \\\\\n",
"1 & 1 & 0.001 & 0.999 \\\\\n",
"\\hline\n",
"\\end{matrix}\n",
"\n",
"
\n",
"\n",
"You come home and find that the the grass is wet, what is the probability the sprinklers were on today (you do not know if it was raining)?\n",
"\n",
"We can start by writing out the joint probability:\n",
"$P(r,w,s)=P(w|r,s)P(r)P(s)$\n",
"\n",
"The conditional probability is then:\n",
"\n",
"\\begin{equation}\n",
"P(s|w)=\\frac{\\sum_{r} P(w|s,r)P(s) P(r)}{P(w)}=\\frac{P(s) \\sum_{r} P(w|s,r) P(r)}{P(w)}\n",
"\\end{equation}\n",
"\n",
"Note that we are summing over all possible conditions for $r$ as we do not know if it was raining. Specifically, we want to know the probability of sprinklers having been on given the wet grass, $P(s=1|w=1)$:\n",
"\n",
"\\begin{equation}\n",
"P(s=1|w=1) = \\frac{P(s = 1)( P(w = 1|s = 1, r = 1) P(r = 1)+ P(w = 1|s = 1,r = 0) P(r = 0))}{P(w = 1)}\n",
"\\end{equation}\n",
"\n",
"where\n",
"\n",
"\\begin{eqnarray}\n",
"P(w=1)=P(s=1)( P(w=1|s=1,r=1 ) P(r=1) &+ P(w=1|s=1,r=0) P(r=0))\\\\\n",
"+P(s=0)( P(w=1|s=0,r=1 ) P(r=1) &+ P(w=1|s=0,r=0) P(r=0))\\\\\n",
"\\end{eqnarray}\n",
"\n",
"This code has been written out below, you just need to insert the right numbers from the table."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"##############################################################################\n",
"# TODO for student: Write code to insert the correct conditional probabilities\n",
"# from the table; see the comments to match variable with table entry.\n",
"# Comment out the line below to test your solution\n",
"raise NotImplementedError(\"Finish the simulation code first\")\n",
"##############################################################################\n",
"\n",
"Pw1r1s1 = ... # the probability of wet grass given rain and sprinklers on\n",
"Pw1r1s0 = ... # the probability of wet grass given rain and sprinklers off\n",
"Pw1r0s1 = ... # the probability of wet grass given no rain and sprinklers on\n",
"Pw1r0s0 = ... # the probability of wet grass given no rain and sprinklers off\n",
"Ps = ... # the probability of the sprinkler being on\n",
"Pr = ... # the probability of rain that day\n",
"\n",
"\n",
"# Calculate A and B\n",
"A = Ps * (Pw1r1s1 * Pr + (Pw1r0s1) * (1 - Pr))\n",
"B = (1 - Ps) * (Pw1r1s0 *Pr + (Pw1r0s0) * (1 - Pr))\n",
"print(f\"Given that the grass is wet, the probability the sprinkler was on is: {A/(A + B):.4f}\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"The probability you should get is about `0.7522`."
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/NeuromatchAcademy/precourse/tree/main/tutorials/W0D5_Statistics/solutions/W0D5_Tutorial2_Solution_c6d5f60c.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Your neighbour now tells you that it was indeed\n",
"raining today, $P(r=1) = 1$, so what is now the probability the sprinklers were on? Try changing the numbers above."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Bayes_Net_Bonus_Exercise\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Bonus Think!: Causality in the Brain\n",
"\n",
"In a causal stucture this is the correct way to calculate the probabilities. Do you think this is how the brain solves such problems? Would it be different for task involving novel stimuli (e.g., for someone with no previous exposure to sprinklers), as opposed to common stimuli?\n",
"\n",
"**Main course preview:** On [Network Causality day](https://compneuro.neuromatch.io/tutorials/W3D5_NetworkCausality/chapter_title.html) we will discuss causality further!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Submit your feedback\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Submit your feedback\n",
"content_review(f\"{feedback_prefix}_Causality_in_the_Brain_Bonus_Discussion\")"
]
}
],
"metadata": {
"colab": {
"collapsed_sections": [],
"include_colab_link": true,
"name": "W0D5_Tutorial2",
"provenance": [],
"toc_visible": true
},
"kernel": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.17"
},
"toc-autonumbering": true
},
"nbformat": 4,
"nbformat_minor": 0
}